
Qualitative Data Coding 101
How to code qualitative data, the smart way (with examples).
By: Jenna Crosley (PhD) | Reviewed by:Dr Eunice Rautenbach | December 2020
As we’ve discussed previously , qualitative research makes use of non-numerical data – for example, words, phrases or even images and video. To analyse this kind of data, the first dragon you’ll need to slay is qualitative data coding (or just “coding” if you want to sound cool). But what exactly is coding and how do you do it?
Overview: Qualitative Data Coding
In this post, we’ll explain qualitative data coding in simple terms. Specifically, we’ll dig into:
- What exactly qualitative data coding is
- What different types of coding exist
- How to code qualitative data (the process)
- Moving from coding to qualitative analysis
- Tips and tricks for quality data coding

What is qualitative data coding?
Let’s start by understanding what a code is. At the simplest level, a code is a label that describes the content of a piece of text. For example, in the sentence:
“Pigeons attacked me and stole my sandwich.”
You could use “pigeons” as a code. This code simply describes that the sentence involves pigeons.
So, building onto this, qualitative data coding is the process of creating and assigning codes to categorise data extracts. You’ll then use these codes later down the road to derive themes and patterns for your qualitative analysis (for example, thematic analysis ). Coding and analysis can take place simultaneously, but it’s important to note that coding does not necessarily involve identifying themes (depending on which textbook you’re reading, of course). Instead, it generally refers to the process of labelling and grouping similar types of data to make generating themes and analysing the data more manageable.
Makes sense? Great. But why should you bother with coding at all? Why not just look for themes from the outset? Well, coding is a way of making sure your data is valid . In other words, it helps ensure that your analysis is undertaken systematically and that other researchers can review it (in the world of research, we call this transparency). In other words, good coding is the foundation of high-quality analysis.

What are the different types of coding?
Now that we’ve got a plain-language definition of coding on the table, the next step is to understand what overarching types of coding exist – in other words, coding approaches . Let’s start with the two main approaches, inductive and deductive .
With deductive coding, you, as the researcher, begin with a set of pre-established codes and apply them to your data set (for example, a set of interview transcripts). Inductive coding on the other hand, works in reverse, as you create the set of codes based on the data itself – in other words, the codes emerge from the data. Let’s take a closer look at both.
Deductive coding 101
With deductive coding, we make use of pre-established codes, which are developed before you interact with the present data. This usually involves drawing up a set of codes based on a research question or previous research . You could also use a code set from the codebook of a previous study.
For example, if you were studying the eating habits of college students, you might have a research question along the lines of
“What foods do college students eat the most?”
As a result of this research question, you might develop a code set that includes codes such as “sushi”, “pizza”, and “burgers”.
Deductive coding allows you to approach your analysis with a very tightly focused lens and quickly identify relevant data . Of course, the downside is that you could miss out on some very valuable insights as a result of this tight, predetermined focus.

Inductive coding 101
But what about inductive coding? As we touched on earlier, this type of coding involves jumping right into the data and then developing the codes based on what you find within the data.
For example, if you were to analyse a set of open-ended interviews , you wouldn’t necessarily know which direction the conversation would flow. If a conversation begins with a discussion of cats, it may go on to include other animals too, and so you’d add these codes as you progress with your analysis. Simply put, with inductive coding, you “go with the flow” of the data.
Inductive coding is great when you’re researching something that isn’t yet well understood because the coding derived from the data helps you explore the subject. Therefore, this type of coding is usually used when researchers want to investigate new ideas or concepts , or when they want to create new theories.

A little bit of both… hybrid coding approaches
If you’ve got a set of codes you’ve derived from a research topic, literature review or a previous study (i.e. a deductive approach), but you still don’t have a rich enough set to capture the depth of your qualitative data, you can combine deductive and inductive methods – this is called a hybrid coding approach.
To adopt a hybrid approach, you’ll begin your analysis with a set of a priori codes (deductive) and then add new codes (inductive) as you work your way through the data. Essentially, the hybrid coding approach provides the best of both worlds, which is why it’s pretty common to see this in research.
Need a helping hand?
How to code qualitative data
Now that we’ve looked at the main approaches to coding, the next question you’re probably asking is “how do I actually do it?”. Let’s take a look at the coding process , step by step.
Both inductive and deductive methods of coding typically occur in two stages: initial coding and line by line coding .
In the initial coding stage, the objective is to get a general overview of the data by reading through and understanding it. If you’re using an inductive approach, this is also where you’ll develop an initial set of codes. Then, in the second stage (line by line coding), you’ll delve deeper into the data and (re)organise it according to (potentially new) codes.
Step 1 – Initial coding
The first step of the coding process is to identify the essence of the text and code it accordingly. While there are various qualitative analysis software packages available, you can just as easily code textual data using Microsoft Word’s “comments” feature.
Let’s take a look at a practical example of coding. Assume you had the following interview data from two interviewees:
What pets do you have?
I have an alpaca and three dogs.
Only one alpaca? They can die of loneliness if they don’t have a friend.
I didn’t know that! I’ll just have to get five more.
I have twenty-three bunnies. I initially only had two, I’m not sure what happened.
In the initial stage of coding, you could assign the code of “pets” or “animals”. These are just initial, fairly broad codes that you can (and will) develop and refine later. In the initial stage, broad, rough codes are fine – they’re just a starting point which you will build onto in the second stage.

How to decide which codes to use
But how exactly do you decide what codes to use when there are many ways to read and interpret any given sentence? Well, there are a few different approaches you can adopt. The main approaches to initial coding include:
- In vivo coding
Process coding
- Open coding
Descriptive coding
Structural coding.
- Value coding
Let’s take a look at each of these:
In vivo coding
When you use in vivo coding , you make use of a participants’ own words , rather than your interpretation of the data. In other words, you use direct quotes from participants as your codes. By doing this, you’ll avoid trying to infer meaning, rather staying as close to the original phrases and words as possible.
In vivo coding is particularly useful when your data are derived from participants who speak different languages or come from different cultures. In these cases, it’s often difficult to accurately infer meaning due to linguistic or cultural differences.
For example, English speakers typically view the future as in front of them and the past as behind them. However, this isn’t the same in all cultures. Speakers of Aymara view the past as in front of them and the future as behind them. Why? Because the future is unknown, so it must be out of sight (or behind us). They know what happened in the past, so their perspective is that it’s positioned in front of them, where they can “see” it.
In a scenario like this one, it’s not possible to derive the reason for viewing the past as in front and the future as behind without knowing the Aymara culture’s perception of time. Therefore, in vivo coding is particularly useful, as it avoids interpretation errors.
Next up, there’s process coding , which makes use of action-based codes . Action-based codes are codes that indicate a movement or procedure. These actions are often indicated by gerunds (words ending in “-ing”) – for example, running, jumping or singing.
Process coding is useful as it allows you to code parts of data that aren’t necessarily spoken, but that are still imperative to understanding the meaning of the texts.
An example here would be if a participant were to say something like, “I have no idea where she is”. A sentence like this can be interpreted in many different ways depending on the context and movements of the participant. The participant could shrug their shoulders, which would indicate that they genuinely don’t know where the girl is; however, they could also wink, showing that they do actually know where the girl is.
Simply put, process coding is useful as it allows you to, in a concise manner, identify the main occurrences in a set of data and provide a dynamic account of events. For example, you may have action codes such as, “describing a panda”, “singing a song about bananas”, or “arguing with a relative”.

Descriptive coding aims to summarise extracts by using a single word or noun that encapsulates the general idea of the data. These words will typically describe the data in a highly condensed manner, which allows the researcher to quickly refer to the content.
Descriptive coding is very useful when dealing with data that appear in forms other than traditional text – i.e. video clips, sound recordings or images. For example, a descriptive code could be “food” when coding a video clip that involves a group of people discussing what they ate throughout the day, or “cooking” when coding an image showing the steps of a recipe.
Structural coding involves labelling and describing specific structural attributes of the data. Generally, it includes coding according to answers to the questions of “ who ”, “ what ”, “ where ”, and “ how ”, rather than the actual topics expressed in the data. This type of coding is useful when you want to access segments of data quickly, and it can help tremendously when you’re dealing with large data sets.
For example, if you were coding a collection of theses or dissertations (which would be quite a large data set), structural coding could be useful as you could code according to different sections within each of these documents – i.e. according to the standard dissertation structure . What-centric labels such as “hypothesis”, “literature review”, and “methodology” would help you to efficiently refer to sections and navigate without having to work through sections of data all over again.
Structural coding is also useful for data from open-ended surveys. This data may initially be difficult to code as they lack the set structure of other forms of data (such as an interview with a strict set of questions to be answered). In this case, it would useful to code sections of data that answer certain questions such as “who?”, “what?”, “where?” and “how?”.
Let’s take a look at a practical example. If we were to send out a survey asking people about their dogs, we may end up with a (highly condensed) response such as the following:
Bella is my best friend. When I’m at home I like to sit on the floor with her and roll her ball across the carpet for her to fetch and bring back to me. I love my dog.
In this set, we could code Bella as “who”, dog as “what”, home and floor as “where”, and roll her ball as “how”.
Values coding
Finally, values coding involves coding that relates to the participant’s worldviews . Typically, this type of coding focuses on excerpts that reflect the values, attitudes, and beliefs of the participants. Values coding is therefore very useful for research exploring cultural values and intrapersonal and experiences and actions.
To recap, the aim of initial coding is to understand and familiarise yourself with your data , to develop an initial code set (if you’re taking an inductive approach) and to take the first shot at coding your data . The coding approaches above allow you to arrange your data so that it’s easier to navigate during the next stage, line by line coding (we’ll get to this soon).
While these approaches can all be used individually, it’s important to remember that it’s possible, and potentially beneficial, to combine them . For example, when conducting initial coding with interviews, you could begin by using structural coding to indicate who speaks when. Then, as a next step, you could apply descriptive coding so that you can navigate to, and between, conversation topics easily. You can check out some examples of various techniques here .
Step 2 – Line by line coding
Once you’ve got an overall idea of our data, are comfortable navigating it and have applied some initial codes, you can move on to line by line coding. Line by line coding is pretty much exactly what it sounds like – reviewing your data, line by line, digging deeper and assigning additional codes to each line.
With line-by-line coding, the objective is to pay close attention to your data to add detail to your codes. For example, if you have a discussion of beverages and you previously just coded this as “beverages”, you could now go deeper and code more specifically, such as “coffee”, “tea”, and “orange juice”. The aim here is to scratch below the surface. This is the time to get detailed and specific so as to capture as much richness from the data as possible.
In the line-by-line coding process, it’s useful to code everything in your data, even if you don’t think you’re going to use it (you may just end up needing it!). As you go through this process, your coding will become more thorough and detailed, and you’ll have a much better understanding of your data as a result of this, which will be incredibly valuable in the analysis phase.

Moving from coding to analysis
Once you’ve completed your initial coding and line by line coding, the next step is to start your analysis . Of course, the coding process itself will get you in “analysis mode” and you’ll probably already have some insights and ideas as a result of it, so you should always keep notes of your thoughts as you work through the coding.
When it comes to qualitative data analysis, there are many different types of analyses (we discuss some of the most popular ones here ) and the type of analysis you adopt will depend heavily on your research aims, objectives and questions . Therefore, we’re not going to go down that rabbit hole here, but we’ll cover the important first steps that build the bridge from qualitative data coding to qualitative analysis.
When starting to think about your analysis, it’s useful to ask yourself the following questions to get the wheels turning:
- What actions are shown in the data?
- What are the aims of these interactions and excerpts? What are the participants potentially trying to achieve?
- How do participants interpret what is happening, and how do they speak about it? What does their language reveal?
- What are the assumptions made by the participants?
- What are the participants doing? What is going on?
- Why do I want to learn about this? What am I trying to find out?
- Why did I include this particular excerpt? What does it represent and how?

Code categorisation
Categorisation is simply the process of reviewing everything you’ve coded and then creating code categories that can be used to guide your future analysis. In other words, it’s about creating categories for your code set. Let’s take a look at a practical example.
If you were discussing different types of animals, your initial codes may be “dogs”, “llamas”, and “lions”. In the process of categorisation, you could label (categorise) these three animals as “mammals”, whereas you could categorise “flies”, “crickets”, and “beetles” as “insects”. By creating these code categories, you will be making your data more organised, as well as enriching it so that you can see new connections between different groups of codes.
Theme identification
From the coding and categorisation processes, you’ll naturally start noticing themes. Therefore, the logical next step is to identify and clearly articulate the themes in your data set. When you determine themes, you’ll take what you’ve learned from the coding and categorisation and group it all together to develop themes. This is the part of the coding process where you’ll try to draw meaning from your data, and start to produce a narrative . The nature of this narrative depends on your research aims and objectives, as well as your research questions (sounds familiar?) and the qualitative data analysis method you’ve chosen, so keep these factors front of mind as you scan for themes.

Tips & tricks for quality coding
Before we wrap up, let’s quickly look at some general advice, tips and suggestions to ensure your qualitative data coding is top-notch.
- Before you begin coding, plan out the steps you will take and the coding approach and technique(s) you will follow to avoid inconsistencies.
- When adopting deductive coding, it’s useful to use a codebook from the start of the coding process. This will keep your work organised and will ensure that you don’t forget any of your codes.
- Whether you’re adopting an inductive or deductive approach, keep track of the meanings of your codes and remember to revisit these as you go along.
- Avoid using synonyms for codes that are similar, if not the same. This will allow you to have a more uniform and accurate coded dataset and will also help you to not get overwhelmed by your data.
- While coding, make sure that you remind yourself of your aims and coding method. This will help you to avoid directional drift , which happens when coding is not kept consistent.
- If you are working in a team, make sure that everyone has been trained and understands how codes need to be assigned.
32 Comments

I appreciated the valuable information provided to accomplish the various stages of the inductive and inductive coding process. However, I would have been extremely satisfied to be appraised of the SPECIFIC STEPS to follow for: 1. Deductive coding related to the phenomenon and its features to generate the codes, categories, and themes. 2. Inductive coding related to using (a) Initial (b) Axial, and (c) Thematic procedures using transcribe data from the research questions

Thank you so much for this. Very clear and simplified discussion about qualitative data coding.

This is what I want and the way I wanted it. Thank you very much.

All of the information’s are valuable and helpful. Thank for you giving helpful information’s. Can do some article about alternative methods for continue researches during the pandemics. It is more beneficial for those struggling to continue their researchers.

Thank you for your information on coding qualitative data, this is a very important point to be known, really thank you very much.

Very useful article. Clear, articulate and easy to understand. Thanks

This is very useful. You have simplified it the way I wanted it to be! Thanks

Thank you so very much for explaining, this is quite helpful!

hello, great article! well written and easy to understand. Can you provide some of the sources in this article used for further reading purposes?

You guys are doing a great job out there . I will not realize how many students you help through your articles and post on a daily basis. I have benefited a lot from your work. this is remarkable.

Wonderful one thank you so much.

Hello, I am doing qualitative research, please assist with example of coding format.

This is an invaluable website! Thank you so very much!

Well explained and easy to follow the presentation. A big thumbs up to you. Greatly appreciate the effort 👏👏👏👏

Thank you for this clear article with examples

Thank you for the detailed explanation. I appreciate your great effort. Congrats!

Ahhhhhhhhhh! You just killed me with your explanation. Crystal clear. Two Cheers!

D0 you have primary references that was used when creating this? If so, can you share them?

Being a complete novice to the field of qualitative data analysis, your indepth analysis of the process of thematic analysis has given me better insight. Thank you so much.

Excellent summary

Thank you so much for your precise and very helpful information about coding in qualitative data.

Thanks a lot to this helpful information. You cleared the fog in my brain.

Glad to hear that!

This has been very helpful. I am excited and grateful.

I still don’t understand the coding and categorizing of qualitative research, please give an example on my research base on the state of government education infrastructure environment in PNG

Wahho, this is amazing and very educational to have come across this site.. from a little search to a wide discovery of knowledge.
Thanks I really appreciate this.

Thank you so much! Very grateful.

This was truly helpful. I have been so lost, and this simplified the process for me.

Just at the right time when I needed to distinguish between inductive and
deductive data analysis of my Focus group discussion results very helpful

Very useful across disciplines and at all levels. Thanks…

Hello, Thank you for sharing your knowledge on us.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
University Library
Qualitative Data Analysis: Coding
- Atlas.ti web
- R for text analysis
- Microsoft Excel & spreadsheets
- Other options
- Planning Qual Data Analysis
- Free Tools for QDA
- QDA with NVivo
- QDA with Atlas.ti
- QDA with MAXQDA
- PKM for QDA
- QDA with Quirkos
- Working Collaboratively
- Qualitative Methods Texts
- Transcription
- Data organization
- Example Publications
Coding Qualitative Data
Planning your coding strategy.
Coding is a qualitative data analysis strategy in which some aspect of the data is assigned a descriptive label that allows the researcher to identify related content across the data. How you decide to code - or whether to code- your data should be driven by your methodology. But there are rarely step-by-step descriptions, and you'll have to make many decisions about how to code for your own project.
Some questions to consider as you decide how to code your data:
What will you code?
What aspects of your data will you code? If you are not coding all of your available data, how will you decide which elements need to be coded? If you have recordings interviews or focus groups, or other types of multimedia data, will you create transcripts to analyze and code? Or will you code the media itself (see Farley, Duppong & Aitken, 2020 on direct coding of audio recordings rather than transcripts).
Where will your codes come from?
Depending on your methodology, your coding scheme may come from previous research and be applied to your data (deductive). Or you my try to develop codes entirely from the data, ignoring as much as possible, previous knowledge of the topic under study, to develop a scheme grounded in your data (inductive). In practice, however, many practices will fall between these two approaches.
How will you apply your codes to your data?
You may decide to use software to code your qualitative data, to re-purpose other software tools (e.g. Word or spreadsheet software) or work primarily with physical versions of your data. Qualitative software is not strictly necessary, though it does offer some advantages, like:
- Codes can be easily re-labeled, merged, or split. You can also choose to apply multiple coding schemes to the same data, which means you can explore multiple ways of understanding the same data. Your analysis, then, is not limited by how often you are able to work with physical data, such as paper transcripts.
- Most software programs for QDA include the ability to export and import coding schemes. This means you can create a re-use a coding scheme from a previous study, or that was developed in outside of the software, without having to manually create each code.
- Some software for QDA includes the ability to directly code image, video, and audio files. This may mean saving time over creating transcripts. Or, your coding may be enhanced by access to the richness of mediated content, compared to transcripts.
- Using QDA software may also allow you the ability to use auto-coding functions. You may be able to automatically code all of the statements by speaker in a focus group transcript, for example, or identify and code all of the paragraphs that include a specific phrase.
What will be coded?
Will you deploy a line-by-line coding approach, with smaller codes eventually condensed into larger categories or concepts? Or will you start with codes applied to larger segments of the text, perhaps later reviewing the examples to explore and re-code for differences between the segments?
How will you explain the coding process?
- Regardless of how you approach coding, the process should be clearly communicated when you report your research, though this is not always the case (Deterding & Waters, 2021).
- Carefully consider the use of phrases like "themes emerged." This phrasing implies that the themes lay passively in the data, waiting for the researcher to pluck them out. This description leaves little room for describing how the researcher "saw" the themes and decided which were relevant to the study. Ryan and Bernard (2003) offer a terrific guide to ways that you might identify themes in the data, using both your own observations as well as manipulations of the data.
How will you report the results of your coding process?
How you report your coding process should align with the methodology you've chosen. Your methodology may call for careful and consistent application of a coding scheme, with reports of inter-rater reliability and counts of how often a code appears within the data. Or you may use the codes to help develop a rich description of an experience, without needing to indicate precisely how often the code was applied.
How will you code collaboratively?
If you are working with another researcher or a team, your coding process requires careful planning and implementation. You will likely need to have regular conversations about your process, particularly if your goal is to develop and consistently apply a coding scheme across your data.
Coding Features in QDA Software Programs
- Atlas.ti (Mac)
- Atlas.ti (Windows)
- NVivo (Windows)
- NVivo (Mac)
- Coding data See how to create and manage codes and apply codes to segments of the data (known as quotations in Atlas.ti).
- Search and Code Using the search and code feature lets you locate and automatically code data through text search, regular expressions, Named Entity Recognition, and Sentiment Analysis.
- Focus Group Coding Properly prepared focus group documents can be automatically coded by speaker.
- Inter-Coder Agreement Coded text, audio, and video documents can be tested for inter-coder agreement. ICA is not available for images or PDF documents.
- Quotation Reader Once you've coded data, you can view just the data that has been assigned that code.
- Find Redundant Codings (Mac) This tool identifies "overlapping or embedded" quotations that have the same code, that are the result of manual coding or errors when merging project files.
- Coding Data in Atlas.ti (Windows) Demonstrates how to create new codes, manage codes and applying codes to segments of the data (known as quotations in Atlas.ti)
- Search and Code in Atlas.ti (Windows) You can use a text search, regular expressions, Named Entity Recognition, and Sentiment Analysis to identify and automatically code data in Atlas.ti.
- Focus Group Coding in Atlas.ti (Windows) Properly prepared focus group transcripts can be automatically coded by speaker.
- Inter-coder Agreement in Atlas.ti (Windows) Coded text, audio, and video documents can be tested for inter-coder agreement. ICA is not available for images or PDF documents.
- Quotation Reader in Atlas.ti (Windows) Once you've coded data, you can view and export the quotations that have been assigned that code.
- Find Redundant Codings in Atlas.ti (Windows) This tool identifies "overlapping or embedded" quotations that have the same code, that are the result of manual coding or errors when merging project files.
- Coding in NVivo (Windows) This page includes an overview of the coding features in NVivo.
- Automatic Coding in Documents in NVivo (Windows) You can use paragraph formatting styles or speaker names to automatically format documents.
- Coding Comparison Query in NVivo (Windows) You can use the coding comparison feature to compare how different users have coded data in NVivo.
- Review the References in a Node in NVivo (Windows) References are the term that NVivo uses for coded segments of the data. This shows you how to view references related to a code (or any node)
- Text Search Queries in NVivo (Windows) Text queries let you search for specific text in your data. The results of your query can be saved as a node (a form of auto coding).
- Coding Query in NVivo (Windows) Use a coding query to display references from your data for a single code or multiples of codes.
- Code Files and Manage Codes in NVivo (Mac) This page offers an overview of coding features in NVivo. Note that NVivo uses the concept of a node to refer to any structure around which you organize your data. Codes are a type of node, but you may see these terms used interchangeably.
- Automatic Coding in Datasets in NVivo (Mac) A dataset in NVivo is data that is in rows and columns, as in a spreadsheet. If a column is set to be codable, you can also automatically code the data. This approach could be used for coding open-ended survey data.
- Text Search Query in NVivo (Mac) Use the text search query to identify relevant text in your data and automatically code references by saving as a node.
- Review the References in a Node in NVivo (Mac) NVivo uses the term references to refer to data that has been assigned to a code or any node. You can use the reference view to see the data linked to a specific node or combination of nodes.
- Coding Comparison Query in NVivo (Mac) Use the coding comparison query to calculate a measure of inter-rater reliability when you've worked with multiple coders.
The MAXQDA interface is the same across Mac and Windows devices.
- The "Code System" in MAXQDA This section of the manual shows how to create and manage codes in MAXQDA's code system.
- How to Code with MAXQDA
- Display Coded Segments in the Document Browser Once you've coded a document within MAXQDA, you can choose which of those codings will appear on the document, as well as choose whether or not the text is highlighted in the color linked to the code.
- Creative Coding in MAXQDA Use the creative coding feature to explore the relationships between codes in your system. If you develop a new structure to you codes that you like, you can apply the changes to your overall code scheme.
- Text Search in MAXQDA Use a Text Search to identify data that matches your search terms and automatically code the results. You can choose whether to code only the matching results, the sentence the results are in, or the paragraph the results appear in.
- Segment Retrieval in MAXQDA Data that has been coded is considered a segment. Segment retrieval is how you display the segments that match a code or combination of codes. You can use the activation feature to show only the segments from a document group, or that match a document variable.
- Intercorder Agreement in MAXQDA MAXQDA includes the ability to compare coding between two coders on a single project.
- Create Tags in Taguette Taguette uses the term tag to refer to codes. You can create single tags as well as a tag hierarchy using punctuation marks.
- Highlighting in Taguette Select text with a document (a highlight) and apply tags to code data in Taguette.
Useful Resources on Coding

Deterding, N. M., & Waters, M. C. (2021). Flexible coding of in-depth interviews: A twenty-first-century approach. Sociological Methods & Research , 50 (2), 708–739. https://doi.org/10.1177/0049124118799377
Farley, J., Duppong Hurley, K., & Aitken, A. A. (2020). Monitoring implementation in program evaluation with direct audio coding. Evaluation and Program Planning , 83 , 101854. https://doi.org/10.1016/j.evalprogplan.2020.101854
Ryan, G. W., & Bernard, H. R. (2003). Techniques to identify themes. Field Methods , 15 (1), 85–109. https://doi.org/10.1177/1525822X02239569.
- << Previous: Data organization
- Next: Citations >>
- Last Updated: Jul 30, 2024 5:06 PM
- URL: https://guides.library.illinois.edu/qualitative
- AI & NLP
- Churn & Loyalty
- Customer Experience
- Customer Journeys
- Customer Metrics
- Feedback Analysis
- Product Experience
- Product Updates
- Sentiment Analysis
- Surveys & Feedback Collection
- Text Analytics
- Try Thematic
Welcome to the community

Coding Qualitative Data: How To Guide
How many hours have you spent sitting in front of Excel spreadsheets trying to find new insights from customer feedback?
You know that asking open-ended survey questions gives you more actionable insights than asking your customers for just a numerical Net Promoter Score (NPS) . But when you ask open-ended, free-text questions, you end up with hundreds (or even thousands) of free-text responses.
How can you turn all of that text into quantifiable, applicable information about your customers’ needs and expectations? By coding qualitative data.
In this article, we will cover different coding methods for qualitative data, including both manual and automated approaches, to provide a comprehensive understanding of the techniques used in the first-round pass at coding.
Keep reading to learn:
- What coding qualitative data means (and why it’s important)
- Different methods of coding qualitative data
- How to manually code qualitative data to find significant themes in your data
What is coding in qualitative research?
Conducting qualitative research, particularly through coding, is a crucial step in ensuring the validity and reliability of the findings. Coding is the process of labeling and organizing your qualitative data to identify different themes and the relationships between them.
When coding customer feedback , you assign labels to words or phrases that represent important (and recurring) themes in each response. These labels can be words, phrases, or numbers; we recommend using words or short phrases, since they’re easier to remember, skim, and organize.
Coding qualitative research to find common themes and concepts is part of thematic analysis . Thematic analysis extracts themes from text by analyzing the word and sentence structure.
Within the context of customer feedback, it’s important to understand the many different types of qualitative feedback a business can collect, such as open-ended surveys, social media comments, reviews & more.
What is qualitative data analysis?
Qualitative data analysis , including coding and analyzing qualitative data, is essential for understanding the depth and complexity of qualitative data. It is the process of examining and interpreting qualitative data to understand what it represents.
Qualitative analysis is crucial as it involves various methods such as thematic analysis, emotion coding, inductive and deductive thematic analysis, and content analysis. These methods help in coding the data, which is vital for the validity of the analysis.
Qualitative data is defined as any non-numerical and unstructured data; when looking at customer feedback, qualitative data usually refers to any verbatim or text-based feedback such as reviews, open-ended responses in surveys , complaints, chat messages, customer interviews, case notes or social media posts.
For example, NPS metric can be strictly quantitative, but when you ask customers why they gave you a rating a score, you will need qualitative data analysis methods in place to understand the comments that customers leave alongside numerical responses.
Methods of qualitative data analysis
Thematic analysis.
This refers to the uncovering of themes, by analyzing the patterns and relationships in a set of qualitative data. A theme emerges or is built when related findings appear to be meaningful and there are multiple occurrences. Thematic analysis can be used by anyone to transform and organize open-ended responses, analyze online reviews , and other qualitative data into significant themes. Thematic analysis coding is a method that aids in categorizing data extracts and deriving themes and patterns for qualitative analysis, facilitating the identification of themes revolving around a particular concept or phenomenon in the social sciences.
Content analysis:
This refers to the categorization, tagging and thematic analysis of qualitative data. Essentially content analysis is a quantification of themes, by counting the occurrence of concepts, topics or themes. Content analysis can involve combining the categories in qualitative data with quantitative data, such as behavioral data or demographic data, for deeper insights.
Narrative analysis:
Some qualitative data, such as interviews or field notes may contain a story on how someone experienced something. For example, the process of choosing a product, using it, evaluating its quality and decision to buy or not buy this product next time. The goal of narrative analysis is to turn the individual narratives into data that can be coded. This is then analyzed to understand how events or experiences had an impact on the people involved. Process coding is particularly useful in narrative analysis for identifying specific phases, sequences, and movements within the stories, capturing actions within qualitative data by using codes that typically represent gerunds ending in 'ing', providing a dynamic account of events within the data.
Discourse analysis:
This refers to analysis of what people say in social and cultural context. The goal of discourse analysis is to understand user or customer behavior by uncovering their beliefs, interests and agendas. These are reflected in the way they express their opinions, preferences and experiences. Structural coding is a method that can be applied here, organizing data based on predetermined structures, such as the structure of discourse elements, to enhance the analysis of discourse. It’s particularly useful when your focus is on building or strengthening a brand , by examining how they use metaphors and rhetorical devices.
Framework analysis:
When performing qualitative data analysis, it is useful to have a framework to organize the buckets of meaning. A taxonomy or code frame (a hierarchical set of themes used in coding qualitative data) is an example of the result. Don't fall into the trap of starting with a framework to make it faster to organize your data. You should look at how themes relate to each other by analyzing the data and consistently check that you can validate that themes are related to each other .
Grounded theory:
This method of analysis starts by formulating a theory around a single data case. Therefore the theory is “grounded' in actual data. Then additional cases can be examined to see if they are relevant and can add to the original theory.
Why is it important to code qualitative data?
Coding qualitative data makes it easier to interpret customer feedback. Assigning codes to words and phrases in each response helps capture what the response is about which, in turn, helps you better analyze and summarize the results of the entire survey.
Researchers use coding and other qualitative data analysis processes to help them make data-driven decisions based on customer feedback. When you use coding to analyze your customer feedback, you can quantify the common themes in customer language. This makes it easier to accurately interpret and analyze customer satisfaction.
What is thematic coding?
Thematic coding, also called thematic analysis, is a type of qualitative data analysis that finds themes in text by analyzing the meaning of words and sentence structure.
When you use thematic coding to analyze customer feedback for example, you can learn which themes are most frequent in feedback. This helps you understand what drives customer satisfaction in an accurate, actionable way.
To learn more about how Thematic analysis software helps you automate the data coding process, check out this article .
Automated vs. Manual coding of qualitative data
Methods of coding qualitative data fall into three categories: automated coding and manual coding, and a blend of the two.
You can automate the coding of your qualitative data with thematic analysis software . Thematic analysis and qualitative data analysis software use machine learning, artificial intelligence (AI) natural language processing (NLP) to code your qualitative data and break text up into themes.
Thematic analysis software is autonomous , which means…
- You don't need to set up themes or categories in advance.
- You don't need to train the algorithm — it learns on its own.
- You can easily capture the “unknown unknowns” to identify themes you may not have spotted on your own.
…all of which will save you time (and lots of unnecessary headaches) when analyzing your customer feedback.
Businesses are also seeing the benefit of using thematic analysis software. The capacity to aggregate data sources into a single source of analysis helps to break down data silos, unifying the analysis and insights across departments . This is now being referred to as Omni channel analysis or Unified Data Analytics .
Use Thematic Analysis Software
Try Thematic today to discover why leading companies rely on the platform to automate the coding of qualitative customer feedback at scale. Whether you have tons of customer reviews, support chat, customer service conversationals ( conversational analytics ) or open-ended survey responses, Thematic brings every valuable insight to the surface, while saving you thousands of hours.
Advances in natural language processing & machine learning have made it possible to automate the analysis of qualitative data, in particular content and framework analysis. The most commonly used software for automated coding of qualitative data is text analytics software such as Thematic .
While manual human analysis is still popular due to its perceived high accuracy, automating most of the analysis is quickly becoming the preferred choice. Unlike manual analysis, which is prone to bias and doesn't scale to the amount of qualitative data that is generated today, automating analysis is not only more consistent and therefore can be more accurate, but can also save a ton of time, and therefore money.
Our Theme Editor tool ensures you take a reflexive approach, an important step in thematic analysis. The drag-and-drop tool makes it easy to refine, validate, and rename themes as you get more data. By guiding the AI, you can ensure your results are always precise, easy to understand and perfectly aligned with your objectives.
Thematic is the best software to automate code qualitative feedback at scale.
Don't just take it from us. Here's what some of our customers have to say:
I'm a fan of Thematic's ability to save time and create heroes. It does an excellent job using a single view to break down the verbatims into themes displayed by volume, sentiment and impact on our beacon metric, often but not exclusively NPS.
It does a superlative job using GenAI in summarizing a theme or sub-theme down to a single paragraph making it clear what folks are trying to say. Peter K, Snr Research Manager.
Thematic is a very intuitive tool to use. It boasts a robust level of granularity, allowing the user to see the general breadth of verbatim themes, dig into the sub-themes, and further into the sentiment of the open text itself. Artem C, Sr Manager of Research. LinkedIn.
AI-powered software to transform qualitative data at scale through a thematic and content analysis.
How to manually code qualitative data
For the rest of this post, we'll focus on manual coding. Different researchers have different processes, but manual coding usually looks something like this:
- Choose whether you'll use deductive or inductive coding.
- Read through your data to get a sense of what it looks like. Assign your first set of codes.
- Go through your data line-by-line to code as much as possible. Your codes should become more detailed at this step.
- Categorize your codes and figure out how they fit into your coding frame.
- Identify which themes come up the most — and act on them.
Let's break it down a little further…
Deductive coding vs. inductive coding
Before you start qualitative data coding, you need to decide which codes you'll use.
What is Deductive Coding?
Deductive coding means you start with a predefined set of codes, then assign those codes to the new qualitative data. These codes might come from previous research, or you might already know what themes you're interested in analyzing. Deductive coding is also called concept-driven coding.
For example, let's say you're conducting a survey on customer experience . You want to understand the problems that arise from long call wait times, so you choose to make “wait time” one of your codes before you start looking at the data.
The deductive approach can save time and help guarantee that your areas of interest are coded. But you also need to be careful of bias; when you start with predefined codes, you have a bias as to what the answers will be. Make sure you don't miss other important themes by focusing too hard on proving your own hypothesis.
What is Inductive Coding?
Inductive coding , also called open coding, starts from scratch and creates codes based on the qualitative data itself. You don't have a set codebook; all codes arise directly from the survey responses.
Here's how inductive coding works:
- Break your qualitative dataset into smaller samples.
- Read a sample of the data.
- Create codes that will cover the sample.
- Reread the sample and apply the codes.
- Read a new sample of data, applying the codes you created for the first sample.
- Note where codes don't match or where you need additional codes.
- Create new codes based on the second sample.
- Go back and recode all responses again.
- Repeat from step 5 until you've coded all of your data.
If you add a new code, split an existing code into two, or change the description of a code, make sure to review how this change will affect the coding of all responses. Otherwise, the same responses at different points in the survey could end up with different codes.
Sounds like a lot of work, right? Inductive coding is an iterative process, which means it takes longer and is more thorough than deductive coding. A major advantage is that it gives you a more complete, unbiased look at the themes throughout your data.
Combining inductive and deductive coding
In practice, most researchers use a blend of inductive and deductive approaches to coding.
For example, with Thematic, the AI inductively comes up with themes , while also framing the analysis so that it reflects how business decisions are made . At the end of the analysis, researchers use the Theme Editor to iterate or refine themes. Then, in the next wave of analysis, as new data comes in, the AI starts deductively with the theme taxonomy.
Categorize your codes with coding frames
Once you create your codes, you need to put them into a coding frame. A coding frame represents the organizational structure of the themes in your research. There are two types of coding frames: flat and hierarchical.
Flat Coding Frame
A flat coding frame assigns the same level of specificity and importance to each code. While this might feel like an easier and faster method for manual coding, it can be difficult to organize and navigate the themes and concepts as you create more and more codes. It also makes it hard to figure out which themes are most important, which can slow down decision making.
Hierarchical Coding Frame
Hierarchical frames help you organize codes based on how they relate to one another. For example, you can organize the codes based on your customers' feelings on a certain topic:

Hierarchical Coding Frame example
In this example:
- The top-level code describes the topic (customer service)
- The mid-level code specifies whether the sentiment is positive or negative
- The third level details the attribute or specific theme associated with the topic
Hierarchical framing supports a larger code frame and lets you organize codes based on organizational structure. It also allows for different levels of granularity in your coding.
Whether your code frames are hierarchical or flat, your code frames should be flexible. Manually analyzing survey data takes a lot of time and effort; make sure you can use your results in different contexts.
For example, if your survey asks customers about customer service, you might only use codes that capture answers about customer service. Then you realize that the same survey responses have a lot of comments about your company's products. To learn more about what people say about your products, you may have to code all of the responses from scratch! A flexible coding frame covers different topics and insights, which lets you reuse the results later on.
Tips for manually coding qualitative data
Now that you know the basics of coding your qualitative data, here are some tips on making the most of your qualitative research.
Use a codebook to keep track of your codes
As you code more and more data, it can be hard to remember all of your codes off the top of your head. Tracking your codes in a codebook helps keep you organized throughout the data analysis process. Your codebook can be as simple as an Excel spreadsheet or word processor document. As you code new data, add new codes to your codebook and reorganize categories and themes as needed.
Make sure to track:
- The label used for each code
- A description of the concept or theme the code refers to
- Who originally coded it
- The date that it was originally coded or updated
- Any notes on how the code relates to other codes in your analysis
How to create high-quality codes - 4 tips
1. cover as many survey responses as possible..
The code should be generic enough to apply to multiple comments, but specific enough to be useful in your analysis. For example, “Product” is a broad code that will cover a variety of responses — but it's also pretty vague. What about the product? On the other hand, “Product stops working after using it for 3 hours” is very specific and probably won't apply to many responses. “Poor product quality” or “short product lifespan” might be a happy medium.
2. Avoid commonalities.
Having similar codes is okay as long as they serve different purposes. “Customer service” and “Product” are different enough from one another, while “Customer service” and “Customer support” may have subtle differences but should likely be combined into one code.
3. Capture the positive and the negative.
Try to create codes that contrast with each other to track both the positive and negative elements of a topic separately. For example, “Useful product features” and “Unnecessary product features” would be two different codes to capture two different themes.
4. Reduce data — to a point.
Let's look at the two extremes: There are as many codes as there are responses, or each code applies to every single response. In both cases, the coding exercise is pointless; you don't learn anything new about your data or your customers. To make your analysis as useful as possible, try to find a balance between having too many and too few codes.
Group responses based on themes, not words
Make sure to group responses with the same themes under the same code, even if they don't use the same exact wording. For example, a code such as “cleanliness” could cover responses including words and phrases like:
- Looked like a dump
- Could eat off the floor
Having only a few codes and hierarchical framing makes it easier to group different words and phrases under one code. If you have too many codes, especially in a flat frame, your results can become ambiguous and themes can overlap. Manual coding also requires the coder to remember or be able to find all of the relevant codes; the more codes you have, the harder it is to find the ones you need, no matter how organized your codebook is.
Make accuracy a priority
Manually coding qualitative data means that the coder's cognitive biases can influence the coding process. For each study, make sure you have coding guidelines and training in place to keep coding reliable, consistent, and accurate .
One thing to watch out for is definitional drift, which occurs when the data at the beginning of the data set is coded differently than the material coded later. Check for definitional drift across the entire dataset and keep notes with descriptions of how the codes vary across the results.
If you have multiple coders working on one team, have them check one another's coding to help eliminate cognitive biases.
Conclusion: 6 main takeaways for coding qualitative data
Here are 6 final takeaways for manually coding your qualitative data:
- Coding is the process of labeling and organizing your qualitative data to identify themes. After you code your qualitative data, you can analyze it just like numerical data.
- Inductive coding (without a predefined code frame) is more difficult, but less prone to bias, than deductive coding.
- Code frames can be flat (easier and faster to use) or hierarchical (more powerful and organized).
- Your code frames need to be flexible enough that you can make the most of your results and use them in different contexts.
- When creating codes, make sure they cover several responses, contrast one another, and strike a balance between too much and too little information.
- Consistent coding = accuracy. Establish coding procedures and guidelines and keep an eye out for definitional drift in your qualitative data analysis.
Some more detail in our downloadable guide
If you've made it this far, you'll likely be interested in our free guide: Best practices for analyzing open-ended questions.
The guide includes some of the topics covered in this article, and goes into some more niche details.
If your company is looking to automate your qualitative coding process, try Thematic !
If you're looking to trial multiple solutions, check out our free buyer's guide . It covers what to look for when trialing different feedback analytics solutions to ensure you get the depth of insights you need.
Happy coding!
Authored by Alyona Medelyan, PhD – Natural Language Processing & Machine Learning

CEO and Co-Founder
Alyona has a PhD in NLP and Machine Learning. Her peer-reviewed articles have been cited by over 2600 academics. Her love of writing comes from years of PhD research.
We make it easy to discover the customer and product issues that matter.
Unlock the value of feedback at scale, in one platform. Try it for free now!
- Questions to ask your Feedback Analytics vendor
- How to end customer churn for good
- Scalable analysis of NPS verbatims
- 5 Text analytics approaches
- How to calculate the ROI of CX
Our experts will show you how Thematic works, how to discover pain points and track the ROI of decisions. To access your free trial, book a personal demo today.
Recent posts
Become a qualitative theming pro! Creating a perfect code frame is hard, but thematic analysis software makes the process much easier.
Discover the power of thematic analysis to unlock insights from qualitative data. Learn about manual vs. AI-powered approaches, best practices, and how Thematic software can revolutionize your analysis workflow.
When two major storms wreaked havoc on Auckland and Watercare’s infrastructurem the utility went through a CX crisis. With a massive influx of calls to their support center, Thematic helped them get inisghts from this data to forge a new approach to restore services and satisfaction levels.
Chapter 18. Data Analysis and Coding
Introduction.
Piled before you lie hundreds of pages of fieldnotes you have taken, observations you’ve made while volunteering at city hall. You also have transcripts of interviews you have conducted with the mayor and city council members. What do you do with all this data? How can you use it to answer your original research question (e.g., “How do political polarization and party membership affect local politics?”)? Before you can make sense of your data, you will have to organize and simplify it in a way that allows you to access it more deeply and thoroughly. We call this process coding . [1] Coding is the iterative process of assigning meaning to the data you have collected in order to both simplify and identify patterns. This chapter introduces you to the process of qualitative data analysis and the basic concept of coding, while the following chapter (chapter 19) will take you further into the various kinds of codes and how to use them effectively.
To those who have not yet conducted a qualitative study, the sheer amount of collected data will be a surprise. Qualitative data can be absolutely overwhelming—it may mean hundreds if not thousands of pages of interview transcripts, or fieldnotes, or retrieved documents. How do you make sense of it? Students often want very clear guidelines here, and although I try to accommodate them as much as possible, in the end, analyzing qualitative data is a bit more of an art than a science: “The process of bringing order, structure, and interpretation to a mass of collected data is messy, ambiguous, time-consuming, creative, and fascinating. It does not proceed in a linear fashion: it is not neat. At times, the researcher may feel like an eccentric and tormented artist; not to worry, this is normal” ( Marshall and Rossman 2016:214 ).
To complicate matters further, each approach (e.g., Grounded Theory, deep ethnography, phenomenology) has its own language and bag of tricks (techniques) when it comes to analysis. Grounded Theory, for example, uses in vivo coding to generate new theoretical insights that emerge from a rigorous but open approach to data analysis. Ethnographers, in contrast, are more focused on creating a rich description of the practices, behaviors, and beliefs that operate in a particular field. They are less interested in generating theory and more interested in getting the picture right, valuing verisimilitude in the presentation. And then there are some researchers who seek to account for the qualitative data using almost quantitative methods of analysis, perhaps counting and comparing the uses of certain narrative frames in media accounts of a phenomenon. Qualitative content analysis (QCA) often includes elements of counting (see chapter 17). For these researchers, having very clear hypotheses and clearly defined “variables” before beginning analysis is standard practice, whereas the same would be expressly forbidden by those researchers, like grounded theorists, taking a more emergent approach.
All that said, there are some helpful techniques to get you started, and these will be presented in this and the following chapter. As you become more of an expert yourself, you may want to read more deeply about the tradition that speaks to your research. But know that there are many excellent qualitative researchers that use what works for any given study, who take what they can from each tradition. Most of us find this permissible (but watch out for the methodological purists that exist among us).

Qualitative Data Analysis as a Long Process!
Although most of this and the following chapter will focus on coding, it is important to understand that coding is just one (very important) aspect of the long data-analysis process. We can consider seven phases of data analysis, each of which is important for moving your voluminous data into “findings” that can be reported to others. The first phase involves data organization. This might mean creating a special password-protected Dropbox folder for storing your digital files. It might mean acquiring computer-assisted qualitative data-analysis software ( CAQDAS ) and uploading all transcripts, fieldnotes, and digital files to its storage repository for eventual coding and analysis. Finding a helpful way to store your material can take a lot of time, and you need to be smart about this from the very beginning. Losing data because of poor filing systems or mislabeling is something you want to avoid. You will also want to ensure that you have procedures in place to protect the confidentiality of your interviewees and informants. Filing signed consent forms (with names) separately from transcripts and linking them through an ID number or other code that only you have access to (and store safely) are important.
Once you have all of your material safely and conveniently stored, you will need to immerse yourself in the data. The second phase consists of reading and rereading or viewing and reviewing all of your data. As you do this, you can begin to identify themes or patterns in the data, perhaps writing short memos to yourself about what you are seeing. You are not committing to anything in this third phase but rather keeping your eyes and mind open to what you see. In an actual study, you may very well still be “in the field” or collecting interviews as you do this, and what you see might push you toward either concluding your data collection or expanding so that you can follow a particular group or factor that is emerging as important. For example, you may have interviewed twelve international college students about how they are adjusting to life in the US but realized as you read your transcripts that important gender differences may exist and you have only interviewed two women (and ten men). So you go back out and make sure you have enough female respondents to check your impression that gender matters here. The seven phases do not proceed entirely linearly! It is best to think of them as recursive; conceptually, there is a path to follow, but it meanders and flows.
Coding is the activity of the fourth phase . The second part of this chapter and all of chapter 19 will focus on coding in greater detail. For now, know that coding is the primary tool for analyzing qualitative data and that its purpose is to both simplify and highlight the important elements buried in mounds of data. Coding is a rigorous and systematic process of identifying meaning, patterns, and relationships. It is a more formal extension of what you, as a conscious human being, are trained to do every day when confronting new material and experiences. The “trick” or skill is to learn how to take what you do naturally and semiconsciously in your mind and put it down on paper so it can be documented and verified and tested and refined.
At the conclusion of the coding phase, your material will be searchable, intelligible, and ready for deeper analysis. You can begin to offer interpretations based on all the work you have done so far. This fifth phase might require you to write analytic memos, beginning with short (perhaps a paragraph or two) interpretations of various aspects of the data. You might then attempt stitching together both reflective and analytical memos into longer (up to five pages) general interpretations or theories about the relationships, activities, patterns you have noted as salient.
As you do this, you may be rereading the data, or parts of the data, and reviewing your codes. It’s possible you get to this phase and decide you need to go back to the beginning. Maybe your entire research question or focus has shifted based on what you are now thinking is important. Again, the process is recursive , not linear. The sixth phase requires you to check the interpretations you have generated. Are you really seeing this relationship, or are you ignoring something important you forgot to code? As we don’t have statistical tests to check the validity of our findings as quantitative researchers do, we need to incorporate self-checks on our interpretations. Ask yourself what evidence would exist to counter your interpretation and then actively look for that evidence. Later on, if someone asks you how you know you are correct in believing your interpretation, you will be able to explain what you did to verify this. Guard yourself against accusations of “ cherry-picking ,” selecting only the data that supports your preexisting notion or expectation about what you will find. [2]
The seventh and final phase involves writing up the results of the study. Qualitative results can be written in a variety of ways for various audiences (see chapter 20). Due to the particularities of qualitative research, findings do not exist independently of their being written down. This is different for quantitative research or experimental research, where completed analyses can somewhat speak for themselves. A box of collected qualitative data remains a box of collected qualitative data without its written interpretation. Qualitative research is often evaluated on the strength of its presentation. Some traditions of qualitative inquiry, such as deep ethnography, depend on written thick descriptions, without which the research is wholly incomplete, even nonexistent. All of that practice journaling and writing memos (reflective and analytical) help develop writing skills integral to the presentation of the findings.
Remember that these are seven conceptual phases that operate in roughly this order but with a lot of meandering and recursivity throughout the process. This is very different from quantitative data analysis, which is conducted fairly linearly and processually (first you state a falsifiable research question with hypotheses, then you collect your data or acquire your data set, then you analyze the data, etc.). Things are a bit messier when conducting qualitative research. Embrace the chaos and confusion, and sort your way through the maze. Budget a lot of time for this process. Your research question might change in the middle of data collection. Don’t worry about that. The key to being nimble and flexible in qualitative research is to start thinking and continue thinking about your data, even as it is being collected. All seven phases can be started before all the data has been gathered. Data collection does not always precede data analysis. In some ways, “qualitative data collection is qualitative data analysis.… By integrating data collection and data analysis, instead of breaking them up into two distinct steps, we both enrich our insights and stave off anxiety. We all know the anxiety that builds when we put something off—the longer we put it off, the more anxious we get. If we treat data collection as this mass of work we must do before we can get started on the even bigger mass of work that is analysis, we set ourselves up for massive anxiety” ( Rubin 2021:182–183 ; emphasis added).
The Coding Stage
A code is “a word or short phrase that symbolically assigns a summative, salient, essence-capturing, and/or evocative attribute for a portion of language-based or visual data” ( Saldaña 2014:5 ). Codes can be applied to particular sections of or entire transcripts, documents, or even videos. For example, one might code a video taken of a preschooler trying to solve a puzzle as “puzzle,” or one could take the transcript of that video and highlight particular sections or portions as “arranging puzzle pieces” (a descriptive code) or “frustration” (a summative emotion-based code). If the preschooler happily shouts out, “I see it!” you can denote the code “I see it!” (this is an example of an in vivo, participant-created code). As one can see from even this short example, there are many different kinds of codes and many different strategies and techniques for coding, more of which will be discussed in detail in chapter 19. The point to remember is that coding is a rigorous systematic process—to some extent, you are always coding whenever you look at a person or try to make sense of a situation or event, but you rarely do this consciously. Coding is the process of naming what you are seeing and how you are simplifying the data so that you can make sense of it in a way that is consistent with your study and in a way that others can understand and follow and replicate. Another way of saying this is that a code is “a researcher-generated interpretation that symbolizes or translates data” ( Vogt et al. 2014:13 ).
As with qualitative data analysis generally, coding is often done recursively, meaning that you do not merely take one pass through the data to create your codes. Saldaña ( 2014 ) differentiates first-cycle coding from second-cycle coding. The goal of first-cycle coding is to “tag” or identify what emerges as important codes. Note that I said emerges—you don’t always know from the beginning what will be an important aspect of the study or not, so the coding process is really the place for you to begin making the kinds of notes necessary for future analyses. In second-cycle coding, you will want to be much more focused—no longer gathering wholly new codes but synthesizing what you have into metacodes.
You might also conceive of the coding process in four parts (figure 18.1). First, identify a representative or diverse sample set of interview transcripts (or fieldnotes or other documents). This is the group you are going to use to get a sense of what might be emerging. In my own study of career obstacles to success among first-generation and working-class persons in sociology, I might select one interview from each career stage: a graduate student, a junior faculty member, a senior faculty member.
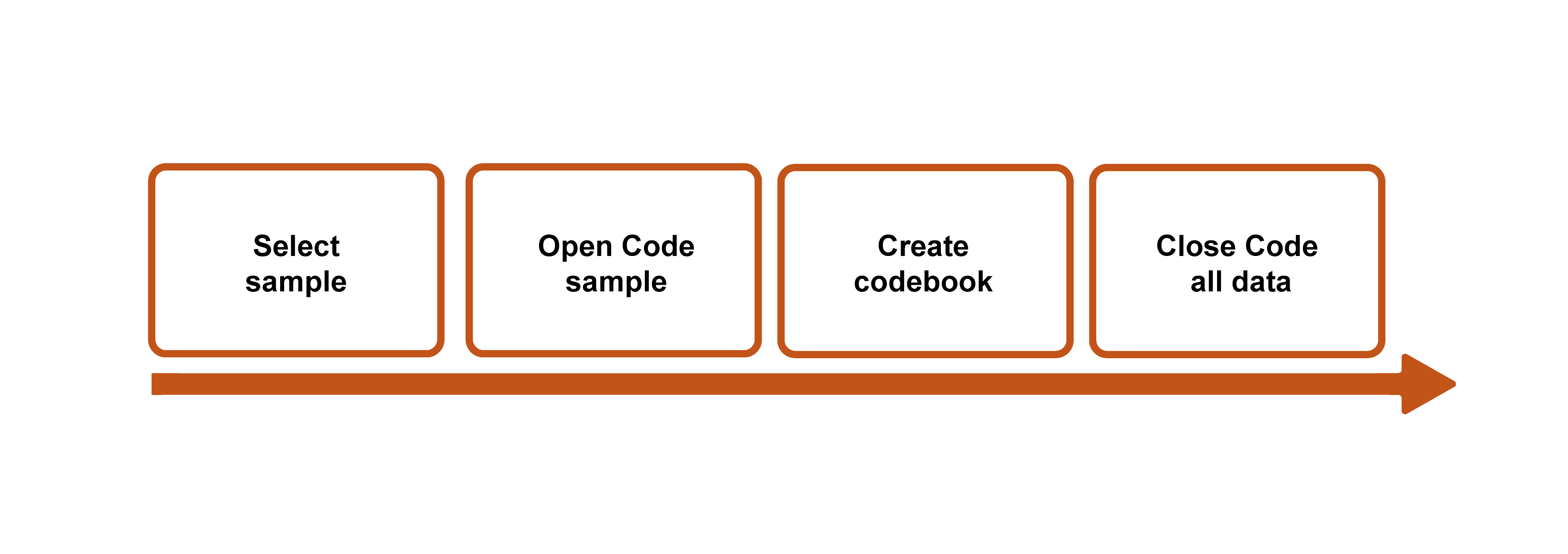
Second, code everything (“ open coding ”). See what emerges, and don’t limit yourself in any way. You will end up with a ton of codes, many more than you will end up with, but this is an excellent way to not foreclose an interesting finding too early in the analysis. Note the importance of starting with a sample of your collected data, because otherwise, open coding all your data is, frankly, impossible and counterproductive. You will just get stuck in the weeds.
Third, pare down your coding list. Where you may have begun with fifty (or more!) codes, you probably want no more than twenty remaining. Go back through the weeds and pull out everything that does not have the potential to bloom into a nicely shaped garden. Note that you should do this before tackling all of your data . Sometimes, however, you might need to rethink the sample you chose. Let’s say that the graduate student interview brought up some interesting gender issues that were pertinent to female-identifying sociologists, but both the junior and the senior faculty members identified as male. In that case, I might read through and open code at least one other interview transcript, perhaps a female-identifying senior faculty member, before paring down my list of codes.
This is also the time to create a codebook if you are using one, a master guide to the codes you are using, including examples (see Sample Codebooks 1 and 2 ). A codebook is simply a document that lists and describes the codes you are using. It is easy to forget what you meant the first time you penciled a coded notation next to a passage, so the codebook allows you to be clear and consistent with the use of your codes. There is not one correct way to create a codebook, but generally speaking, the codebook should include (1) the code (either name or identification number or both), (2) a description of what the code signifies and when and where it should be applied, and (3) an example of the code to help clarify (2). Listing all the codes down somewhere also allows you to organize and reorganize them, which can be part of the analytical process. It is possible that your twenty remaining codes can be neatly organized into five to seven master “themes.” Codebooks can and should develop as you recursively read through and code your collected material. [3]
Fourth, using the pared-down list of codes (or codebook), read through and code all the data. I know many qualitative researchers who work without a codebook, but it is still a good practice, especially for beginners. At the very least, read through your list of codes before you begin this “ closed coding ” step so that you can minimize the chance of missing a passage or section that needs to be coded. The final step is…to do it all again. Or, at least, do closed coding (step four) again. All of this takes a great deal of time, and you should plan accordingly.
Researcher Note
People often say that qualitative research takes a lot of time. Some say this because qualitative researchers often collect their own data. This part can be time consuming, but to me, it’s the analytical process that takes the most time. I usually read every transcript twice before starting to code, then it usually takes me six rounds of coding until I’m satisfied I’ve thoroughly coded everything. Even after the coding, it usually takes me a year to figure out how to put the analysis together into a coherent argument and to figure out what language to use. Just deciding what name to use for a particular group or idea can take months. Understanding this going in can be helpful so that you know to be patient with yourself.
—Jessi Streib, author of The Power of the Past and Privilege Lost
Note that there is no magic in any of this, nor is there any single “right” way to code or any “correct” codes. What you see in the data will be prompted by your position as a researcher and your scholarly interests. Where the above codes on a preschooler solving a puzzle emerged from my own interest in puzzle solving, another researcher might focus on something wholly different. A scholar of linguistics, for example, may focus instead on the verbalizations made by the child during the discovery process, perhaps even noting particular vocalizations (incidence of grrrs and gritting of the teeth, for example). Your recording of the codes you used is the important part, as it allows other researchers to assess the reliability and validity of your analyses based on those codes. Chapter 19 will provide more details about the kinds of codes you might develop.
Saldaña ( 2014 ) lists seven “necessary personal attributes” for successful coding. To paraphrase, they are the following:
- Having (or practicing) good organizational skills
- Perseverance
- The ability and willingness to deal with ambiguity
- Flexibility
- Creativity, broadly understood, which includes “the ability to think visually, to think symbolically, to think in metaphors, and to think of as many ways as possible to approach a problem” (20)
- Commitment to being rigorously ethical
- Having an extensive vocabulary [4]
Writing Analytic Memos during/after Coding
Coding the data you have collected is only one aspect of analyzing it. Too many beginners have coded their data and then wondered what to do next. Coding is meant to help organize your data so that you can see it more clearly, but it is not itself an analysis. Thinking about the data, reviewing the coded data, and bringing in the previous literature (here is where you use your literature review and theory) to help make sense of what you have collected are all important aspects of data analysis. Analytic memos are notes you write to yourself about the data. They can be short (a single page or even a paragraph) or long (several pages). These memos can themselves be the subject of subsequent analytic memoing as part of the recursive process that is qualitative data analysis.
Short analytic memos are written about impressions you have about the data, what is emerging, and what might be of interest later on. You can write a short memo about a particular code, for example, and why this code seems important and where it might connect to previous literature. For example, I might write a paragraph about a “cultural capital” code that I use whenever a working-class sociologist says anything about “not fitting in” with their peers (e.g., not having the right accent or hairstyle or private school background). I could then write a little bit about Bourdieu, who originated the notion of cultural capital, and try to make some connections between his definition and how I am applying it here. I can also use the memo to raise questions or doubts I have about what I am seeing (e.g., Maybe the type of school belongs somewhere else? Is this really the right code?). Later on, I can incorporate some of this writing into the theory section of my final paper or article. Here are some types of things that might form the basis of a short memo: something you want to remember, something you noticed that was new or different, a reaction you had, a suspicion or hunch that you are developing, a pattern you are noticing, any inferences you are starting to draw. Rubin ( 2021 ) advises, “Always include some quotation or excerpt from your dataset…that set you off on this idea. It’s happened to me so many times—I’ll have a really strong reaction to a piece of data, write down some insight without the original quotation or context, and then [later] have no idea what I was talking about and have no way of recreating my insight because I can’t remember what piece of data made me think this way” ( 203 ).
All CAQDAS programs include spaces for writing, generating, and storing memos. You can link a memo to a particular transcript, for example. But you can just as easily keep a notebook at hand in which you write notes to yourself, if you prefer the more tactile approach. Drawing pictures that illustrate themes and patterns you are beginning to see also works. The point is to write early and write often, as these memos are the building blocks of your eventual final product (chapter 20).
In the next chapter (chapter 19), we will go a little deeper into codes and how to use them to identify patterns and themes in your data. This chapter has given you an idea of the process of data analysis, but there is much yet to learn about the elements of that process!
Qualitative Data-Analysis Samples
The following three passages are examples of how qualitative researchers describe their data-analysis practices. The first, by Harvey, is a useful example of how data analysis can shift the original research questions. The second example, by Thai, shows multiple stages of coding and how these stages build upward to conceptual themes and theorization. The third example, by Lamont, shows a masterful use of a variety of techniques to generate theory.
Example 1: “Look Someone in the Eye” by Peter Francis Harvey ( 2022 )
I entered the field intending to study gender socialization. However, through the iterative process of writing fieldnotes, rereading them, conducting further research, and writing extensive analytic memos, my focus shifted. Abductive analysis encourages the search for unexpected findings in light of existing literature. In my early data collection, fieldnotes, and memoing, classed comportment was unmistakably prominent in both schools. I was surprised by how pervasive this bodily socialization proved to be and further surprised by the discrepancies between the two schools.…I returned to the literature to compare my empirical findings.…To further clarify patterns within my data and to aid the search for disconfirming evidence, I constructed data matrices (Miles, Huberman, and Saldaña 2013). While rereading my fieldnotes, I used ATLAS.ti to code and recode key sections (Miles et al. 2013), punctuating this process with additional analytic memos. ( 2022:1420 )
Example 2:” Policing and Symbolic Control” by Mai Thai ( 2022 )
Conventional to qualitative research, my analyses iterated between theory development and testing. Analytical memos were written throughout the data collection, and my analyses using MAXQDA software helped me develop, confirm, and challenge specific themes.…My early coding scheme which included descriptive codes (e.g., uniform inspection, college trips) and verbatim codes of the common terms used by field site participants (e.g., “never quit,” “ghetto”) led me to conceptualize valorization. Later analyses developed into thematic codes (e.g., good citizens, criminality) and process codes (e.g., valorization, criminalization), which helped refine my arguments. ( 2022:1191–1192 )
Example 3: The Dignity of Working Men by Michèle Lamont ( 2000 )
To analyze the interviews, I summarized them in a 13-page document including socio-demographic information as well as information on the boundary work of the interviewees. To facilitate comparisons, I noted some of the respondents’ answers on grids and summarized these on matrix displays using techniques suggested by Miles and Huberman for standardizing and processing qualitative data. Interviews were also analyzed one by one, with a focus on the criteria that each respondent mobilized for the evaluation of status. Moreover, I located each interviewee on several five-point scales pertaining to the most significant dimensions they used to evaluate status. I also compared individual interviewees with respondents who were similar to and different from them, both within and across samples. Finally, I classified all the transcripts thematically to perform a systematic analysis of all the important themes that appear in the interviews, approaching the latter as data against which theoretical questions can be explored. ( 2000:256–257 )
Sample Codebook 1
This is an abridged version of the codebook used to analyze qualitative responses to a question about how class affects careers in sociology. Note the use of numbers to organize the flow, supplemented by highlighting techniques (e.g., bolding) and subcoding numbers.
01. CAPS: Any reference to “capitals” in the response, even if the specific words are not used
01.1: cultural capital 01.2: social capital 01.3: economic capital
(can be mixed: “0.12”= both cultural and asocial capital; “0.23”= both social and economic)
01. CAPS: a reference to “capitals” in which the specific words are used [ bold : thus, 01.23 means that both social capital and economic capital were mentioned specifically
02. DEBT: discussion of debt
02.1: mentions personal issues around debt 02.2: discusses debt but in the abstract only (e.g., “people with debt have to worry”)
03. FirstP: how the response is positioned
03.1: neutral or abstract response 03.2: discusses self (“I”) 03.3: discusses others (“they”)
Sample Coded Passage:
| “I was really hurt when I didn’t get that scholarship. It was going to cost me thousands of dollars to stay in the program, and I was going to have to borrow all of it. My faculty advisor wasn’t helpful at all. They told | 03.2 |
| me not to worry about it, because it wasn’t really that much money! I almost fell over when they said that! Like, do they not understand what it’s like to be poor? I just felt so isolated then. I was on my own. | 02.1. 01.3 |
| I couldn’t talk to anyone about it, because no one else seemed to worry about it. Talk about economic capital!” |
* Question: What other codes jump out to you here? Shouldn’t there be a code for feelings of loneliness or alienation? What about an emotions code ?
Sample Codebook 2
| CODE | DEFINITION | WHEN TO APPLY | IN VIVO EXAMPLE |
|---|---|---|---|
| ALIENATION | Feeling out of place in academia | Any time uses the word alienation or impostor syndrome or feeling out of place | “I was so lonely in graduate school. It was an alienating experience.” |
| CULTURAL CAPITAL | Knowledge or other cultural resources that affect success in academia | When “cultural capital” is used but also when knowledge or lack of knowledge about cultural things are discussed | “We went to a fancy restaurant after my job interview and I was paralyzed with fear because I did not know which fork I was supposed to be using. Yikes!” |
| SOCIAL CAPITAL | Social networks that advance success in academia | When “social capital” is used but also when social networks are discussed or knowing the right people | “I didn’t know who to turn to. It seemed like everyone else had parents who could help them and I didn’t know anyone else who had ever even gone to college!” |
This is an example that uses "word" categories only, with descriptions and examples for each code
Further Readings
Elliott, Victoria. 2018. “Thinking about the Coding Process in Qualitative Analysis.” Qualitative Report 23(11):2850–2861. Address common questions those new to coding ask, including the use of “counting” and how to shore up reliability.
Friese, Susanne. 2019. Qualitative Data Analysis with ATLAS.ti. 3rd ed. A good guide to ATLAS.ti, arguably the most used CAQDAS program. Organized around a series of “skills training” to get you up to speed.
Jackson, Kristi, and Pat Bazeley. 2019. Qualitative Data Analysis with NVIVO . 3rd ed. Thousand Oaks, CA: SAGE. If you want to use the CAQDAS program NVivo, this is a good affordable guide to doing so. Includes copious examples, figures, and graphic displays.
LeCompte, Margaret D. 2000. “Analyzing Qualitative Data.” Theory into Practice 39(3):146–154. A very practical and readable guide to the entire coding process, with particular applicability to educational program evaluation/policy analysis.
Miles, Matthew B., and A. Michael Huberman. 1994. Qualitative Data Analysis: An Expanded Sourcebook . 2nd ed. Thousand Oaks, CA: SAGE. A classic reference on coding. May now be superseded by Miles, Huberman, and Saldaña (2019).
Miles, Matthew B., A. Michael Huberman, and Johnny Saldaña. 2019. Qualitative Data Analysis: A Methods Sourcebook . 4th ed. Thousand Oaks, CA; SAGE. A practical methods sourcebook for all qualitative researchers at all levels using visual displays and examples. Highly recommended.
Saldaña, Johnny. 2014. The Coding Manual for Qualitative Researchers . 2nd ed. Thousand Oaks, CA: SAGE. The most complete and comprehensive compendium of coding techniques out there. Essential reference.
Silver, Christina. 2014. Using Software in Qualitative Research: A Step-by-Step Guide. 2nd ed. Thousand Oaks, CA; SAGE. If you are unsure which CAQDAS program you are interested in using or want to compare the features and usages of each, this guidebook is quite helpful.
Vogt, W. Paul, Elaine R. Vogt, Diane C. Gardner, and Lynne M. Haeffele2014. Selecting the Right Analyses for Your Data: Quantitative, Qualitative, and Mixed Methods . New York: The Guilford Press. User-friendly reference guide to all forms of analysis; may be particularly helpful for those engaged in mixed-methods research.
- When you have collected content (historical, media, archival) that interests you because of its communicative aspect, content analysis (chapter 17) is appropriate. Whereas content analysis is both a research method and a tool of analysis, coding is a tool of analysis that can be used for all kinds of data to address any number of questions. Content analysis itself includes coding. ↵
- Scientific research, whether quantitative or qualitative, demands we keep an open mind as we conduct our research, that we are “neutral” regarding what is actually there to find. Students who are trained in non-research-based disciplines such as the arts or philosophy or who are (admirably) focused on pursuing social justice can too easily fall into the trap of thinking their job is to “demonstrate” something through the data. That is not the job of a researcher. The job of a researcher is to present (and interpret) findings—things “out there” (even if inside other people’s hearts and minds). One helpful suggestion: when formulating your research question, if you already know the answer (or think you do), scrap that research. Ask a question to which you do not yet know the answer. ↵
- Codebooks are particularly useful for collaborative research so that codes are applied and interpreted similarly. If you are working with a team of researchers, you will want to take extra care that your codebooks remain in synch and that any refinements or developments are shared with fellow coders. You will also want to conduct an “intercoder reliability” check, testing whether the codes you have developed are clearly identifiable so that multiple coders are using them similarly. Messy, unclear codes that can be interpreted differently by different coders will make it much more difficult to identify patterns across the data. ↵
- Note that this is important for creating/denoting new codes. The vocabulary does not need to be in English or any particular language. You can use whatever words or phrases capture what it is you are seeing in the data. ↵
A first-cycle coding process in which gerunds are used to identify conceptual actions, often for the purpose of tracing change and development over time. Widely used in the Grounded Theory approach.
A first-cycle coding process in which terms or phrases used by the participants become the code applied to a particular passage. It is also known as “verbatim coding,” “indigenous coding,” “natural coding,” “emic coding,” and “inductive coding,” depending on the tradition of inquiry of the researcher. It is common in Grounded Theory approaches and has even given its name to one of the primary CAQDAS programs (“NVivo”).
Computer-assisted qualitative data-analysis software. These are software packages that can serve as a repository for qualitative data and that enable coding, memoing, and other tools of data analysis. See chapter 17 for particular recommendations.
The purposeful selection of some data to prove a preexisting expectation or desired point of the researcher where other data exists that would contradict the interpretation offered. Note that it is not cherry picking to select a quote that typifies the main finding of a study, although it would be cherry picking to select a quote that is atypical of a body of interviews and then present it as if it is typical.
A preliminary stage of coding in which the researcher notes particular aspects of interest in the data set and begins creating codes. Later stages of coding refine these preliminary codes. Note: in Grounded Theory , open coding has a more specific meaning and is often called initial coding : data are broken down into substantive codes in a line-by-line manner, and incidents are compared with one another for similarities and differences until the core category is found. See also closed coding .
A set of codes, definitions, and examples used as a guide to help analyze interview data. Codebooks are particularly helpful and necessary when research analysis is shared among members of a research team, as codebooks allow for standardization of shared meanings and code attributions.
The final stages of coding after the refinement of codes has created a complete list or codebook in which all the data is coded using this refined list or codebook. Compare to open coding .
A first-cycle coding process in which emotions and emotionally salient passages are tagged.
Introduction to Qualitative Research Methods Copyright © 2023 by Allison Hurst is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License , except where otherwise noted.
The Coding Manual for Qualitative Researchers
Student resources.
Welcome to the companion website for The Coding Manual for Qualitative Research , third edition, by Johnny Saldaña. This website offers a wealth of additional resources to support students and lecturers including:
CAQDAS links giving guidance and links to a variety of qualitative data analysis software.
Code lists including data extracted from the author’s study, “Lifelong Learning Impact: Adult Perceptions of Their High School Speech and/or Theatre Participation” (McCammon, Saldaña, Hines, & Omasta, 2012), which you can download and make your own practice manipulations to the data.
Coding examples from SAGE journals providing actual examples of coding at work, giving you insight into coding procedures.
Three sample interview transcripts that allow you to test your coding skills.
Group exercises for small and large groups encourage you to get to grips with basic principles of coding, partner development, categorization and qualitative data analysis
Flashcard glossary of terms enables you to test your knowledge of the terminology commonly used in qualitative research and coding.
About the book
Johnny Saldaña’s unique and invaluable manual demystifies the qualitative coding process with a comprehensive assessment of different coding types, examples and exercises. The ideal reference for students, teachers, and practitioners of qualitative inquiry, it is essential reading across the social sciences and neatly guides you through the multiple approaches available for coding qualitative data.
Its wide array of strategies, from the more straightforward to the more complex, is skilfully explained and carefully exemplified, providing a complete toolkit of codes and skills that can be applied to any research project. For each code Saldaña provides information about the method's origin, gives a detailed description of the method, demonstrates its practical applications, and sets out a clearly illustrated example with analytic follow up.
This international bestseller is an extremely usable, robust manual and is a must-have resource for qualitative researchers at all levels.
This website may contain links to both internal and external websites. All links included were active at the time the website was launched. SAGE does not operate these external websites and does not necessarily endorse the views expressed within them. SAGE cannot take responsibility for the changing content or nature of linked sites, as these sites are outside of our control and subject to change without our knowledge. If you do find an inactive link to an external website, please try to locate that website by using a search engine. SAGE will endeavour to update inactive or broken links when possible.

- Find My Rep
You are here
The Coding Manual for Qualitative Researchers
- Johnny Saldana - Arizona State University, USA
- Description
“ Especially useful for utilization in higher education, administrative research, general development, the arts, social sciences, nursing, business, and health care. That may seem like a vast application, but both students and professionals will appreciate the clarity and the emblematic mentorship this book provides. ” – American Journal of Qualitative Research
This invaluable manual from world-renowned expert Johnny Saldaña illuminates the process of qualitative coding and provides clear, insightful guidance for qualitative researchers at all levels. The fourth edition includes a range of updates that build upon the huge success of the previous editions:
- A structural reformat has increased accessibility; the 3 sections from the previous edition are now spread over 15 chapters for easier sectional reference
- There are two new first cycle coding methods join the 33 others in the collection: Metaphor Coding and Themeing the Data: Categorically
- Includes a brand new companion website with links to SAGE journal articles, sample transcripts, links to CAQDAS sites, student exercises, links to video and digital content
- Analytic software screenshots and academic references have been updated, alongside several new figures added throughout the manual
Saldana presents a range of coding options with advantages and disadvantages to help researchers to choose the most appropriate approach for their project, reinforcing their perspective with real world examples, used to show step-by-step processes and to demonstrate important skills.
Supplements
This coding manual is the best go-to text for qualitative data analysis, both for a manual approach and for computer-assisted analysis. It offers a range of coding strategies applicable to any research projects, written in accessible language, making this text highly practical as well as theoretically comprehensive.
With this expanded fourth edition of The Coding Manual for Qualitative Researchers, Saldaña has proved to be an exemplary archivist of the field of qualitative methods, whilst never losing sight of the practical issues involved in inducting new researchers to the variety of coding methods available to them. His text provides great worked examples which build up understanding, skills and confidence around coding for the new researcher, whilst also enhancing established researchers’ grasp of the key principles of coding.
Johnny Saldaña’s Coding Manual for Qualitative Researcher s has been an indispensable resource for students, teachers and practitioners since it was first published in 2009. With its expanded contents, new coding methods and more intuitive structure, the fourth edition deserves a prominent place on every qualitative researcher’s bookshelf.
An essential text for qualitative research training and fieldwork. Along with updated examples and applications, Saldaña's fourth edition introduces multiple new coding methods, solidifying this as the most comprehensive, practical qualitative coding guide on the market today.
This book really is the coding manual for qualitative researchers, both aspiring and seasoned. The text is well-organized and thorough. With several new methods included in the fourth edition, this is an essential reference text for qualitative analysts.
This book will be of particular help to PhD students rather than masters.
This will be of particular help to PhD students rather than Masters
Great update to the third addition.
This is a great resource for qualitative researchers of all levels. It gives clear details on different ways to code, it gives clear examples, and there are citations of others who have used that type of coding. It is great for use in the methods section of articles. It is also valuable for introducing graduate students different ways to code. It is an indispensable resource.
Excellent resource for learning how to analyze qualitative data.
Preview this book
For instructors, select a purchasing option.
- Electronic Order Options VitalSource Amazon Kindle Google Play eBooks.com Kobo
Related Products


The Ultimate Guide to Qualitative Research - Part 2: Handling Qualitative Data

- Handling qualitative data
- Transcripts
- Field notes
- Survey data and responses
- Visual and audio data
- Data organization
- Introduction
Qualitative data
Coding qualitative data, coding methods, using atlas.ti for qualitative data coding, automated coding tools in atlas.ti.
- Coding frame
- Auto and smart coding
- Organizing codes
- Qualitative data analysis
- Content analysis
- Thematic analysis
- Thematic analysis vs. content analysis
- Narrative research
- Phenomenological research
- Discourse analysis
- Grounded theory
- Deductive reasoning
- Inductive reasoning
- Inductive vs. deductive reasoning
- Qualitative data interpretation
- Qualitative data analysis software
Coding qualitative data for valuable insights
Qualitative researchers, at one point or another, will inevitably find themselves involved in coding their data. The coding process can be arduous and time-consuming, so it's essential to understand how coding contributes to the understanding of knowledge in qualitative research .

Qualitative research tends to work with unstructured data that requires some systematic organization to facilitate insights relevant to your research inquiry. Suppose you need to determine the most critical aspects for deciding what hotel to stay in when you go on vacation. The decision process that goes into choosing the "best" hotel can be located in various and separate places (e.g., travel websites, blogs, personal conversations) and scattered among pieces of information that may not be relevant to you. In qualitative research, one of the goals prior to data analysis is to identify what information is important, find that information, and sort that information in a way that makes it easy for you to come to a decision.

Qualitative coding is almost always a necessary part of the qualitative data analysis process . Coding provides a way to make the meaning of the data clear to you and to your research audience.
What is a code?
A code in the context of qualitative data analysis is a summary of a larger segment of text. Imagine applying a couple of sticky notes to a collection of recipes, marking each section with short labels like "ingredients," "directions," and "advice." Afterward, someone can page through those recipes and easily locate the section they are looking for, thanks to those sticky notes.
Now, suppose you have different colors of sticky notes, where each color denotes a particular cuisine (e.g., Italian, Chinese, vegetarian). Now, with two ways to organize the data in front of you, you can look at all of the ingredient sections of all the recipes belonging to a cuisine to get a sense of the items that are commonly used for such recipes.
As illustrated in this example, one reason someone might apply sticky notes to a recipe is to help the reader save time in getting the desired information from that text, which is essentially the goal of qualitative coding. Coding allows a reader to get the information they are looking for to facilitate the analysis process. Moreover, this process of categorizing the different pieces of data helps researchers see what is going on in their data and identify emerging dimensions and patterns.
The use of codes also has a purpose beyond simply establishing a convenient means to draw meaning from the data . When presenting qualitative research to an audience, researchers could rely on a narrative summary of the data, but such narratives might be too lengthy to grasp or difficult to convey to others.
As a result, researchers in all fields tend to rely on data visualizations to illustrate their data analysis . Naturally, suppose such visualizations rely on tables and figures like bar charts and diagrams to convey meaning. In that case, researchers need to find ways to "count" the data along established data points, which is a role that coding can fulfill. While a strictly numerical understanding of qualitative research may overlook the finer aspects of social phenomena, researchers ultimately benefit from an analysis of the frequency of codes, combinations of codes, and patterns of codes that can contribute to theory generation. In addition, codes can be visualized in numerous ways to present qualitative insights. From flow charts to semantic networks, codes provide researchers with almost limitless possibilities in choosing how to present their rich qualitative data to different audiences.
Applying codes
To engage in coding, a researcher looks at the data line-by-line and develops a codebook by identifying data segments that can be represented by words or short phrases.

In the example above, a set of three paragraphs is represented by one code displayed in green in the right margin. Without codes, the researcher might have to re-read all of the text to remind themselves what the data is about. Indeed, any researcher who examines the codebook of a project can glean a sense of the data and analysis.
Analyzing codes
Think of a simple example to illustrate the importance of analyzing codes. Suppose you are analyzing survey responses for people's preferences for shopping in brick-and-mortar stores and shopping online. In that case, you might think about marking each survey response as either "prefers shopping in-person" or "prefers shopping online." Once you have applied the relevant codes to each survey response, you can compare the frequencies of both codes to determine where the population as a whole stands on the subject.
Among other things, codes can be analyzed by their frequency or their connection to other codes (or co-occurrence with other codes). In the example above, you may also decide to code the data for the reasons that inform people's shopping habits, applying labels such as "convenience," "value," and "service." Then, the analysis process is simply a matter of determining how often each reason co-occurs with preferences for in-person shopping and online shopping by analyzing the codes applied to the data.
As a result, qualitative coding transforms raw data into a form that facilitates the generation of deeper insights through empirical analysis.
That said, coding is a time-consuming, albeit necessary, task in qualitative research and one that researchers have developed into an array of established methods that are worth briefly looking at.
Years of development of qualitative research methods have yielded multiple methods for assigning codes to data. While all qualitative coding approaches essentially seek to summarize large amounts of information succinctly, there are various approaches you can apply to your coding process.
Inductive coding
Probably the most basic form of coding is to look at the data and reduce it to its salient points of information through coding. Any inductive approach to research involves generating knowledge from the ground up. Inductive coding, as a result, looks to generate insights from the qualitative data itself.
Inductive coding benefits researchers who need to look at the data primarily for its inherent meaning rather than for how external frameworks of knowledge might look at it. Inductive coding can also provide a new perspective that established theory has yet to consider, which would make a theory-driven approach inappropriate.
Deductive coding
A deductive approach to coding is also useful in qualitative research . In contrast with inductive coding, a deductive coding approach applies an existing research framework or previous research study to new data. This means that the researcher applies a set of predefined codes based on established research to the new data.
Researchers can benefit from using both approaches in tandem if their research questions call for a synthesized analysis . Returning to the example of a cookbook, a person may mark the different sections of each recipe because they have prior knowledge about what a typical recipe might look like. On the other hand, if they come across a non-typical recipe (e.g., a recipe that may not have an ingredients section), they might need to create new codes to identify parts of the recipe that seem unusual or novel.
Employing both inductive coding and deductive coding , as a result, can help you achieve a more holistic analysis of your data by building on existing knowledge of a phenomenon while generating new knowledge about the less familiar aspects.
Thematic analysis coding
Whether you decide to apply an inductive coding or deductive coding approach to qualitative data, the coding should also be relevant to your research inquiry in order to be useful and avoid a cumbersome amount of coding that might defeat the purpose of summarizing your data. Let's look at a series of more specific approaches to qualitative coding to get a wider sense of how coding has been applied to qualitative research.
The goal of a thematic analysis arising from coding , as the name suggests, is to identify themes revolving around a particular concept or phenomenon. While concepts in the natural sciences, such as temperature and atomic weight, can be measured with numerical data, concepts in the social sciences often escape easy numerical analysis. Rather than reduce the beauty of a work of art or proficiency in a foreign language down to a number, thematic analysis coding looks to describe these phenomena by various aspects that can be grouped together within common themes.
Looking at the recipe again, we can describe a typical recipe by the sections that appear the most often. The same is true for describing a sport (e.g., rules, strategies, equipment) or a car (e.g., type, price, fuel efficiency, safety rating). While later analysis might be able to numerically measure these themes if they are particular enough, the role of coding along the lines of themes provides a good starting point for recognizing and analyzing relevant concepts.
Process coding
Processes are phenomena that are characterized by action. Think about the act of driving a car rather than describing the car itself. In this case, process coding can be thought of as an extension of thematic coding, except that the major aspects of a process can also be identified by sequences and patterns, on the assumption that some actions may follow other actions. After all, drivers typically turn the key in the ignition before releasing the parking brake or shifting to drive. Capturing the specific phases and sequences is a key objective in process coding.
Structural coding
The "structure" of a recipe in a cookbook is different from that of an essay or a newspaper article. Also, think about how an interview for research might be structured differently from an interview for a TV news program. Researchers can employ structural coding to organize the data according to its distinct structural elements, such as specific elements, the ordering of information, or the purpose behind different structures. This kind of analysis could help, for instance, to achieve a greater understanding of how cultures shape a particular piece of writing or social practice.
Longitudinal coding
Studies that observe people or practices over time do so to capture and understand changes in dynamic environments. The role of longitudinal coding is to also code for relevant contextual or temporal aspects. These can then be analyzed together with other codes to assess how frequencies and patterns change from one observation or interview to the next. This will help researchers empirically illustrate differences or changes over time.

Whatever your approach, code your data with ATLAS.ti
Powerful tools for manual coding and automated coding. Check them out with a free trial.
Qualitative data analysis software should effectively facilitate qualitative coding. Researchers can choose between manual coding and automated coding , where tools can be employed to suggest and apply codes to save time. ATLAS.ti is ideal for both approaches to suit researchers of all needs and backgrounds.
Manual coding
At the core of any qualitative data analysis software is the interface that allows researchers the freedom of assigning codes to qualitative data . ATLAS.ti's interface for viewing data makes it easy to highlight data segments and apply new codes or existing codes quickly and efficiently.

In vivo coding
Interpreting qualitative data to create codes is often a part of the coding process. This can mean that the names of codes may differ from the actual text of the data itself.
However, the best names for codes sometimes come from the textual data itself, as opposed to some interpretation of the text. As a result, there may be a particular word or short phrase that stands out to you in your data set, compelling you to incorporate that word or phrase into your qualitative codes. Think about how social media has slang or acronyms like "YOLO" or "YMMV" which condense a lot of meaning or convey something of importance in the context of the research. Rather than obscuring participants’ meanings or experiences within another layer of interpretation, researchers can build meaningful and rich insights by using participants’ own words to create in vivo codes .

In vivo coding is a handy feature in ATLAS.ti for when you come across a key term or phrase that you want to create a code out of. Simply highlight the desired text and click on "Code in Vivo" to create a new code instantly.
Code Manager
One of the biggest challenges of coding qualitative data is keeping track of dozens or even hundreds of codes, because a lack of organization may hinder researchers in the main objective of succinctly summarizing qualitative data.

Once you have developed and applied a set of codes to your project data, you can open the Code Manager to gain a bird's eye view of all of your codes so you can develop and reorganize them, into hierarchies, groups, or however you prefer. Your list of codes can also be exported to share with others or use in other qualitative or quantitative analysis software .
Use ATLAS.ti for efficient and insightful coding
Intuitive tools to help you code and analyze your data, available starting with a free trial.
Traditionally, qualitative researchers would perform this coding on their data manually by hand, which involves carefully reading each piece of data and attaching codes. For qualitative researchers using pen and paper, they can use highlighters or bookmark flags to mark the key points in their data for later reference. Qualitative researchers also have powerful qualitative data analysis software they can rely on to facilitate all aspects of the coding process.

Although researchers can use qualitative data analysis software to engage in manual coding, there is also now a range of software tools that can even automate the coding process . A number of automated coding tools in ATLAS.ti such as AI Coding, Sentiment Analysis, and Opinion Mining use machine learning and natural language processing to apply useful codes for later analysis. Moreover, other tools in ATLAS.ti rely on pattern recognition to facilitate the creation of descriptive codes throughout your project.
One of the most exciting implications of recent advances in artificial intelligence is its potential for facilitating the research process, especially in qualitative research. The use of machine learning to understand the salient points in data can be especially useful to researchers in all fields.

AI Coding , available in both the Desktop platforms and Web version of ATLAS.ti, performs comprehensive descriptive coding on your qualitative data . It processes data through OpenAI's language models to suggest and apply codes to your project in a fraction of the time that it would take to do manually.
Sentiment Analysis
Participants may often express sentiments that are positive or negative in nature. If you are interested in analyzing the feelings expressed in your data, you can analyze these sentiments . To conduct automated coding for these sentiments, ATLAS.ti employs machine learning to process your data quickly and suggest codes to be applied to relevant data segments.

Opinion Mining
If you want to understand both what participants talked about and how they felt about it, you can conduct Opinion Mining. This tool synthesizes key phrases in your textual data according to whether they are being talked about in a positive or negative manner. The codes generated from Opinion Mining can provide a useful illustration of how language in interviews, focus groups, and surveys is used when discussing certain topics or phenomena.

Code qualitative data with ATLAS.ti
Download a free trial of ATLAS.ti and code your data with ease.
A guide to coding qualitative research data
Last updated
12 February 2023
Reviewed by
Short on time? Get an AI generated summary of this article instead
Each time you ask open-ended and free-text questions, you'll end up with numerous free-text responses. When your qualitative data piles up, how do you sift through it to determine what customers value? And how do you turn all the gathered texts into quantifiable and actionable information related to your user's expectations and needs?
Qualitative data can offer significant insights into respondents’ attitudes and behavior. But to distill large volumes of text / conversational data into clear and insightful results can be daunting. One way to resolve this is through qualitative research coding.
Streamline data coding
Use global data tagging systems in Dovetail so everyone analyzing research is speaking the same language
- What is coding in qualitative research?
This is the system of classifying and arranging qualitative data . Coding in qualitative research involves separating a phrase or word and tagging it with a code. The code describes a data group and separates the information into defined categories or themes. Using this system, researchers can find and sort related content.
They can also combine categorized data with other coded data sets for analysis, or analyze it separately. The primary goal of coding qualitative data is to change data into a consistent format in support of research and reporting.
A code can be a phrase or a word that depicts an idea or recurring theme in the data. The code’s label must be intuitive and encapsulate the essence of the researcher's observations or participants' responses. You can generate these codes using two approaches to coding qualitative data: manual coding and automated coding.
- Why is it important to code qualitative data?
By coding qualitative data, it's easier to identify consistency and scale within a set of individual responses. Assigning codes to phrases and words within feedback helps capture what the feedback entails. That way, you can better analyze and understand the outcome of the entire survey.
Researchers use coding and other qualitative data analysis procedures to make data-driven decisions according to customer responses. Coding in customer feedback will help you assess natural themes in the customers’ language. With this, it's easy to interpret and analyze customer satisfaction .
- How do inductive and deductive approaches to qualitative coding work?
Before you start qualitative research coding, you must decide whether you're starting with some predefined code frames, within which the data will be sorted (deductive approach). Or, you may plan to develop and evolve the codes while reviewing the qualitative data generated by the research (inductive approach). A combination of both approaches is also possible.
In most instances, a combined approach will be best. For example, researchers will have some predefined codes/themes they expect to find in the data, but will allow for a degree of discovery in the data where new themes and codes come to light.
Inductive coding
This is an exploratory method in which new data codes and themes are generated by the review of qualitative data. It initiates and generates code according to the source of the data itself. It's ideal for investigative research, in which you devise a new idea, theory, or concept.
Inductive coding is otherwise called open coding. There's no predefined code-frame within inductive coding, as all codes are generated by reviewing the raw qualitative data.
If you're adding a new code, changing a code descriptor, or dividing an existing code in half, ensure you review the wider code frame to determine whether this alteration will impact other feedback codes. Failure to do this may lead to similar responses at various points in the qualitative data, generating different codes while containing similar themes or insights.
Inductive coding is more thorough and takes longer than deductive coding, but offers a more unbiased and comprehensive overview of the themes within your data.
Deductive coding
This is a hierarchical approach to coding. In this method, you develop a codebook using your initial code frames. These frames may depend on an ongoing research theory or questions. Go over the data once again and filter data to different codes.
After generating your qualitative data, your codes must be a match for the code frame you began with. Program evaluation research could use this coding approach.
Inductive and deductive approaches
Research studies usually blend both inductive and deductive coding approaches. For instance, you may use a deductive approach for your initial set of code sets, and later use an inductive approach to generate fresh codes and recalibrate them while you review and analyze your data.
- What are the practical steps for coding qualitative data?
You can code qualitative data in the following ways:
1. Conduct your first-round pass at coding qualitative data
You need to review your data and assign codes to different pieces in this step. You don't have to generate the right codes since you will iterate and evolve them ahead of the second-round coding review.
Let's look at examples of the coding methods you may use in this step.
Open coding : This involves the distilling down of qualitative data into separate, distinct coded elements.
Descriptive coding : In this method, you create a description that encapsulates the data section’s content. Your code name must be a noun or a term that describes what the qualitative data relates to.
Values coding : This technique categorizes qualitative data that relates to the participant's attitudes, beliefs, and values.
Simultaneous coding : You can apply several codes to a single piece of qualitative data using this approach.
Structural coding : In this method, you can classify different parts of your qualitative data based on a predetermined design to perform additional analysis within the design.
In Vivo coding : Use this as the initial code to represent specific phrases or single words generated via a qualitative interview (i.e., specifically what the respondent said).
Process coding : A process of coding which captures action within data. Usually, this will be in the form of gerunds ending in “ing” (e.g., running, searching, reviewing).
2. Arrange your qualitative codes into groups and subcodes
You can start organizing codes into groups once you've completed your initial round of qualitative data coding. There are several ways to arrange these groups.
You can put together codes related to one another or address the same subjects or broad concepts, under each category. Continue working with these groups and rearranging the codes until you develop a framework that aligns with your analysis.
3. Conduct more rounds of qualitative coding
Conduct more iterations of qualitative data coding to review the codes and groups you've already established. You can change the names and codes, combine codes, and re-group the work you've already done during this phase.
In contrast, the initial attempt at data coding may have been hasty and haphazard. But these coding rounds focus on re-analyzing, identifying patterns, and drawing closer to creating concepts and ideas.
Below are a few techniques for qualitative data coding that are often applied in second-round coding.
Pattern coding : To describe a pattern, you join snippets of data, similarly classified under a single umbrella code.
Thematic analysis coding : When examining qualitative data, this method helps to identify patterns or themes.
Selective coding/focused coding : You can generate finished code sets and groups using your first pass of coding.
Theoretical coding : By classifying and arranging codes, theoretical coding allows you to create a theoretical framework's hypothesis. You develop a theory using the codes and groups that have been generated from the qualitative data.
Content analysis coding : This starts with an existing theory or framework and uses qualitative data to either support or expand upon it.
Axial coding : Axial coding allows you to link different codes or groups together. You're looking for connections and linkages between the information you discovered in earlier coding iterations.
Longitudinal coding : In this method, by organizing and systematizing your existing qualitative codes and categories, it is possible to monitor and measure them over time.
Elaborative coding : This involves applying a hypothesis from past research and examining how your present codes and groups relate to it.
4. Integrate codes and groups into your concluding narrative
When you finish going through several rounds of qualitative data coding and applying different forms of coding, use the generated codes and groups to build your final conclusions. The final result of your study could be a collection of findings, theory, or a description, depending on the goal of your study.
Start outlining your hypothesis , observations , and story while citing the codes and groups that served as its foundation. Create your final study results by structuring this data.
- What are the two methods of coding qualitative data?
You can carry out data coding in two ways: automatic and manual. Manual coding involves reading over each comment and manually assigning labels. You'll need to decide if you're using inductive or deductive coding.
Automatic qualitative data analysis uses a branch of computer science known as Natural Language Processing to transform text-based data into a format that computers can comprehend and assess. It's a cutting-edge area of artificial intelligence and machine learning that has the potential to alter how research and insight is designed and delivered.
Although automatic coding is faster than human coding, manual coding still has an edge due to human oversight and limitations in terms of computer power and analysis.
- What are the advantages of qualitative research coding?
Here are the benefits of qualitative research coding:
Boosts validity : gives your data structure and organization to be more certain the conclusions you are drawing from it are valid
Reduces bias : minimizes interpretation biases by forcing the researcher to undertake a systematic review and analysis of the data
Represents participants well : ensures your analysis reflects the views and beliefs of your participant pool and prevents you from overrepresenting the views of any individual or group
Fosters transparency : allows for a logical and systematic assessment of your study by other academics
- What are the challenges of qualitative research coding?
It would be best to consider theoretical and practical limitations while analyzing and interpreting data. Here are the challenges of qualitative research coding:
Labor-intensive: While you can use software for large-scale text management and recording, data analysis is often verified or completed manually.
Lack of reliability: Qualitative research is often criticized due to a lack of transparency and standardization in the coding and analysis process, being subject to a collection of researcher bias.
Limited generalizability : Detailed information on specific contexts is often gathered using small samples. Drawing generalizable findings is challenging even with well-constructed analysis processes as data may need to be more widely gathered to be genuinely representative of attitudes and beliefs within larger populations.
Subjectivity : It is challenging to reproduce qualitative research due to researcher bias in data analysis and interpretation. When analyzing data, the researchers make personal value judgments about what is relevant and what is not. Thus, different people may interpret the same data differently.
- What are the tips for coding qualitative data?
Here are some suggestions for optimizing the value of your qualitative research now that you are familiar with the fundamentals of coding qualitative data.
Keep track of your codes using a codebook or code frame
It can be challenging to recall all your codes offhand as you code more and more data. Keeping track of your codes in a codebook or code frame will keep you organized as you analyze the data. An Excel spreadsheet or word processing document might be your codebook's basic format.
Ensure you track:
The label applied to each code and the time it was first coded or modified
An explanation of the idea or subject matter that the code relates to
Who the original coder is
Any notes on the relationship between the code and other codes in your analysis
Add new codes to your codebook as you code new data, and rearrange categories and themes as necessary.
- How do you create high-quality codes?
Here are four useful tips to help you create high-quality codes.
1. Cover as many survey responses as possible
The code should be generic enough to aid your analysis while remaining general enough to apply to various comments. For instance, "product" is a general code that can apply to many replies but is also ambiguous.
Also, the specific statement, "product stops working after using it for 3 hours" is unlikely to apply to many answers. A good compromise might be "poor product quality" or "short product lifespan."
2. Avoid similarities
Having similar codes is acceptable only if they serve different objectives. While "product" and "customer service" differ from each other, "customer support" and "customer service" can be unified into a single code.
3. Take note of the positive and the negative
Establish contrasting codes to track an issue's negative and positive aspects separately. For instance, two codes to identify distinct themes would be "excellent customer service" and "poor customer service."
4. Minimize data—to a point
Try to balance having too many and too few codes in your analysis to make it as useful as possible.
What is the best way to code qualitative data?
Depending on the goal of your research, the procedure of coding qualitative data can vary. But generally, it entails:
Reading through your data
Assigning codes to selected passages
Carrying out several rounds of coding
Grouping codes into themes
Developing interpretations that result in your final research conclusions
You can begin by first coding snippets of text or data to summarize or characterize them and then add your interpretative perspective in the second round of coding.
A few techniques are more or less acceptable depending on your study’s goal; there is no right or incorrect way to code a data set.
What is an example of a code in qualitative research?
A code is, at its most basic level, a label specifying how you should read a text. The phrase, "Pigeons assaulted me and took my meal," is an illustration. You can use pigeons as a code word.
Is there coding in qualitative research?
An essential component of qualitative data analysis is coding. Coding aims to give structure to free-form data so one can systematically study it.
Should you be using a customer insights hub?
Do you want to discover previous research faster?
Do you share your research findings with others?
Do you analyze research data?
Start for free today, add your research, and get to key insights faster
Editor’s picks
Last updated: 18 April 2023
Last updated: 27 February 2023
Last updated: 22 August 2024
Last updated: 5 February 2023
Last updated: 16 August 2024
Last updated: 9 March 2023
Last updated: 30 April 2024
Last updated: 12 December 2023
Last updated: 11 March 2024
Last updated: 4 July 2024
Last updated: 6 March 2024
Last updated: 5 March 2024
Last updated: 13 May 2024
Latest articles
Related topics, .css-je19u9{-webkit-align-items:flex-end;-webkit-box-align:flex-end;-ms-flex-align:flex-end;align-items:flex-end;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-flex-direction:row;-ms-flex-direction:row;flex-direction:row;-webkit-box-flex-wrap:wrap;-webkit-flex-wrap:wrap;-ms-flex-wrap:wrap;flex-wrap:wrap;-webkit-box-pack:center;-ms-flex-pack:center;-webkit-justify-content:center;justify-content:center;row-gap:0;text-align:center;max-width:671px;}@media (max-width: 1079px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}}@media (max-width: 799px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}} decide what to .css-1kiodld{max-height:56px;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;}@media (max-width: 1079px){.css-1kiodld{display:none;}} build next, decide what to build next, log in or sign up.
Get started for free
Coding Qualitative Data
- First Online: 02 January 2023
Cite this chapter

- Marla Rogers 4
Part of the book series: Springer Texts in Education ((SPTE))
5918 Accesses
1 Citations
With the advent and proliferation of analysis software (e.g., Nvivo, Atlas.ti), coding data has become much easier in terms of application. Where autocoding algorithms do much to assist and enlighten a researcher in analysis, coding qualitative data remains an act that must largely be undertaken by a human in order to fully address the research question(s) (Kaufmann, A. A., Barcomb, A., & Riehle, D. (2020). Supporting interview analysis with autocoding. HICSS. https://www.semanticscholar.org/paper/Supporting-Interview-Analysis-with-Autocoding-Kaufmann-Barcomb/b6e045859b5ce94e1eb144a9545b26c5e9fa6f32 ). Even seasoned qualitative researchers can find the process of coding their datum corpus to be arduous at times. For novice researchers, the task can quickly become baffling and overwhelming.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or eBook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Compact, lightweight edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Similar content being viewed by others

Analyzing Qualitative Data Using NVivo

Creating Inheritable Digital Codebooks for Qualitative Research Data Analysis

How We Code
Anonymous Author. (2019, July 2). Resolve: Finding a resolution for infertility: Infertility support group and discussion community [online discussion post]. https://www.inspire.com/
Basit, T. N. (2003). Manual or electronic? The role of coding in qualitative data analysis. Educational Research, 45 (2), 143–154.
Article Google Scholar
Braun, V., & Clarke, V. (2006). Using thematic analysis in psychology. Qualitative Research in Psychology, 3 (2), 77–101.
Caulfield, J. (2019, September 6). How to do thematic analysis . www.scribbr.com/methodology/thematicanalysis
Creswell, J. (2015). 30 Essential skills for the qualitative researcher . SAGE.
Google Scholar
Elliot, V. (2018). Thinking about the coding process in qualitative data analysis. The Qualitative Report, 23 (11), 2850–2861. https://nsuworks.nova.edu/tqr/vol23/iss11/14
Kaufmann, A. A., Barcomb, A., & Riehle, D. (2020). Supporting interview analysis with autocoding. HICSS. https://www.semanticscholar.org/paper/Supporting-Interview-Analysis-with-Autocoding-Kaufmann-Barcomb/b6e045859b5ce94e1eb144a9545b26c5e9fa6f32
Saldana, J. (2009). The coding manual for qualitative researchers. SAGE.
Further Readings
Analyzing Qualitative Data: Nvivo 12 Pro for Windows (2 hours). https://www.youtube.com/watch?v=CKPS4LF9G8A
How to Analyze Interview Transcripts. (2 minutes). https://www.rev.com/blog/analyze-interview-transcripts-in-qualitative-research
How to Know You Are Coding Correctly (4 minutes). https://www.youtube.com/watch?v=iL7Ww5kpnIM
Download references
Author information
Authors and affiliations.
University of Saskatchewan, Saskatoon, Canada
Marla Rogers
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Marla Rogers .
Editor information
Editors and affiliations.
Department of Educational Administration, College of Education, University of Saskatchewan, Saskatoon, SK, Canada
Janet Mola Okoko
Scott Tunison
Department of Educational Administration, University of Saskatchewan, Saskatoon, SK, Canada
Keith D. Walker
Rights and permissions
Reprints and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter
Rogers, M. (2023). Coding Qualitative Data. In: Okoko, J.M., Tunison, S., Walker, K.D. (eds) Varieties of Qualitative Research Methods. Springer Texts in Education. Springer, Cham. https://doi.org/10.1007/978-3-031-04394-9_12
Download citation
DOI : https://doi.org/10.1007/978-3-031-04394-9_12
Published : 02 January 2023
Publisher Name : Springer, Cham
Print ISBN : 978-3-031-04396-3
Online ISBN : 978-3-031-04394-9
eBook Packages : Education Education (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 10: Qualitative Data Collection & Analysis Methods
10.6 Qualitative Coding, Analysis, and Write-up: The How to Guide
This section provides an abbreviated set of steps and directions for coding, analyzing, and writing up qualitative data, taking an inductive approach. The following material is adapted from Research Rundowns, retrieved from https://researchrundowns.com/qual/qualitative-coding-analysis/ .
Step 1: Open Coding
At this first level of coding, the researcher is looking for distinct concepts and categories in the data, which will form the basic units of the analysis. In other words, the researcher is breaking down the data into first level concepts, or master headings, and second-level categories, or subheadings.
Researchers often use highlighters to distinguish concepts and categories. For example, if interviewees consistently talk about teaching methods, each time an interviewee mentions teaching methods, or something related to a teaching method, the researcher uses the same colour highlight. Teaching methods would become a concept, and other things related (types, etc.) would become categories – all highlighted in the same colour. It is valuable to use different coloured highlights to distinguish each broad concept and category. At the end of this stage, the transcripts contain many different colours of highlighted text. The next step is to transfer these into a brief outline, with main headings for concepts and subheadings for categories.
Step 2: Axial (Focused) Coding
In open coding, the researcher is focused primarily on the text from the interviews to define concepts and categories. In axial coding, the researcher is using the concepts and categories developed in the open coding process, while re-reading the text from the interviews. This step is undertaken to confirm that the concepts and categories accurately represent interview responses.
In axial coding, the researcher explores how the concepts and categories are related. To examine the latter, you might ask: What conditions caused or influenced concepts and categories? What is/was the social/political context? What are the associated effects or consequences? For example, let us suppose that one of the concepts is Adaptive Teaching , and two of the categories are tutoring and group projects . The researcher would then ask: What conditions caused or influenced tutoring and group projects to occur? From the interview transcripts, it is apparent that participants linked this condition (being able to offer tutoring and group projects) with being enabled by a supportive principle. Consequently, an axial code might be a phrase like our principal encourages different teaching methods . This discusses the context of the concept and/or categories and suggests that the researcher may need a new category labeled “supportive environment.” Axial coding is merely a more directed approach to looking at the data, to help make sure that the researcher has identified all important aspects.
Step 3: Build a Data Table
Table 10.4 illustrates how to transfer the final concepts and categories into a data table. This is a very effective way to organize results and/or discussion in a research paper. While this appears to be a quick process, it requires a lot of time to do it well.
Table 10.4 Major categories and associated concept
| Open Coding | ||
| Axial Coding Themes | ||
| New Category | ||
Step 4: Analysis & Write-Up
Not only is Table 10.4 an effective way to organize the analysis, it is also a good approach for assisting with the data analysis write-up. The first step in the analysis process is to discuss the various categories and describe the associated concepts. As part of this process, the researcher will describe the themes created in the axial coding process (the second step).
There are a variety of ways to present the data in the write-up, including: 1) telling a story; 2) using a metaphor; 3) comparing and contrasting; 4) examining relations among concepts/variables; and 5) counting. Please note that counting should not be a stand-alone qualitative data analysis process to use when writing up the results, because it cannot convey the richness of the data that has been collected. One can certainly use counting for stating the number of participants, or how many participants spoke about a specific theme or category; however, the researcher must present a much deeper level of analysis by drawing out the words of the participants, including the use of direct quotes from the participants´ interviews to demonstrate the validity of the various themes.
Here are some resources for demonstrations on other methods for coding qualitative data:
- Qualitative Data Analysis [PDF]
When writing up the analysis, it is best to “identify” participants through a number, alphabetical letter, or pseudonym in the write-up (e.g. Participant #3 stated …). This demonstrates that you drawing data from all of the participants. Think of it this way, if you were doing quantitative analysis on data from 400 participants, you would present the data for all 400 participants, assuming they all answered a specific question. You will often see in a table of quantitative results (n=400), indicating that 400 people answered the question. This is the researcher’s way of confirming, to the reader, how many participants answered a particular research question. Assigning participant numbers, letters, or pseudonyms serves the same purpose in qualitative analysis.
Research Methods for the Social Sciences: An Introduction Copyright © 2020 by Valerie Sheppard is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Extract insights from Customer & Employee Interviews. At Scale.
Data coding in qualitative research: a step-by-step guide.
Home » Data coding in qualitative research: A step-by-step guide
Qualitative Data Coding serves as a crucial technique in qualitative research, transforming raw data into actionable insights. Researchers often collect vast amounts of unstructured information through interviews, focus groups, or other methods. Without effective coding, this rich data can become overwhelming and difficult to analyze. Qualitative Data Coding provides a systematic approach to categorize and interpret this information, uncovering meaningful patterns and themes that emerge from respondents' experiences.
This process not only helps in organizing data but also facilitates deeper understanding and comparison across different data sets. By assigning labels or codes to various segments of data, researchers can efficiently navigate through responses and draw relevant conclusions. As we move forward in this guide, we will explore detailed steps and strategies to enhance your skills in Qualitative Data Coding, empowering you to uncover valuable insights from your research endeavors.
Understanding Qualitative Data Coding
Qualitative Data Coding is a systematic process that transforms raw qualitative information into organized, analyzable data. This approach enables researchers to identify patterns, themes, and narratives within the data, providing richer insights into human behavior and experiences. Understanding the nuances of this coding process is crucial for successfully interpreting the greater context behind participants' responses.
To effectively grasp qualitative coding, one should consider several key steps. First, familiarize yourself with the different coding techniques—such as open, axial, and selective coding. Each technique serves unique purposes and can enhance analytical depth. Second, ensure that a clear coding framework aligns with your research questions. A well-structured framework aids in maintaining consistency throughout your analysis. Finally, continuously refine your codes as new insights emerge, allowing your research to be adaptive and responsive to the data collected. This iterative approach will contribute significantly to a comprehensive understanding of qualitative data, enriching the overall research findings.
The Importance of Qualitative Data Coding in Research
Qualitative Data Coding plays a pivotal role in transforming raw information into meaningful insights. By systematically organizing this type of data, researchers can identify patterns, themes, and core concepts that inform their analyses. This process enhances the overall quality and reliability of research findings, making it an essential component of qualitative work.
Moreover, qualitative coding helps ensure consistency and accuracy in data interpretation. It allows researchers to group similar information, making it easier to analyze large volumes of qualitative data, such as interviews or open-ended survey responses. When conducted correctly, qualitative data coding not only clarifies the data but also reveals deeper insights that may not be immediately obvious. The structured approach fosters a more robust understanding of participants' perspectives, enriching the research outcomes and providing valuable guidance for decision-making.
Key Concepts in Qualitative Data Coding
Qualitative Data Coding is essential for transforming raw qualitative data into meaningful insights. This process involves identifying themes, patterns, and categories from diverse data sources such as interviews, focus groups, and open-ended survey responses. The first key concept in qualitative data coding is open coding, where researchers assign initial labels to segments of data. This enables them to recognize significant themes as they emerge in the text.
After open coding, researchers engage in axial coding, which refines and correlates these initial codes into broader categories. This helps in developing a more structured understanding of the data. Finally, selective coding focuses on integrating the categorized data to form a coherent narrative that answers the research questions. Overall, a systematic approach to these coding types enhances the accuracy and depth of qualitative analysis, leading to actionable insights. Understanding these concepts is critical for anyone involved in qualitative research.
Steps in the Qualitative Data Coding Process
The qualitative data coding process consists of several key steps that help researchers derive meaningful insights from text or interview data. Initially, researchers must familiarize themselves with the data by reading and re-reading transcripts or notes. This step aids in identifying recurring themes, concepts, or patterns that warrant further exploration. Next, coding involves assigning labels or tags to these themes, allowing researchers to categorize the information systematically.
Following the coding, it is crucial to review and refine these codes to ensure accuracy and consistency. Researchers can then group similar codes into broader categories, which facilitates the organization of data into a coherent narrative. Finally, the coded data can be analyzed and interpreted, resulting in actionable insights. Each step is essential for effective qualitative data coding, ensuring a thorough understanding of the underlying meanings within the data collected.
Preparing Your Data for Coding
Preparing your data for coding is a crucial step in the qualitative data coding process. Begin by gathering all relevant materials, which can include transcripts, notes, and articles. Ensure that these documents are organized and formatted consistently to facilitate smoother analysis. Use a project management tool to maintain clarity and structure as you import data from various sources.
Next, familiarize yourself with the content you'll be coding. Read through each document to identify key themes and concepts. Highlight or annotate significant quotes and insights that might inform your coding framework. This understanding will serve as a valuable foundation as you transition into the coding phase. Ultimately, the objective is to create an accessible and well-prepared dataset that enhances your ability to uncover patterns and themes in your research findings.
Initial Coding: Creating Categories
Initial coding is a crucial phase in qualitative data coding, where researchers begin to organize raw data into meaningful categories. This process involves reviewing transcripts, notes, or other documents to identify recurring themes or significant patterns. By breaking down the data into manageable parts, researchers can create initial codes that represent key concepts or ideas.
During initial coding, it’s helpful to follow specific steps to maintain focus and clarity. First, familiarize yourself with the data by reading it thoroughly. Second, highlight terms or phrases that stand out and resonate with your research objectives. Third, categorize these highlighted items into broader themes based on their similarities. Finally, label each category with a descriptive name that encapsulates its essence. This systematic approach not only aids in data organization but also enhances the overall analysis process, ensuring that crucial insights are not overlooked.
Axial Coding: Identifying Themes
Axial coding is a pivotal step in qualitative data coding, helping researchers refine and interconnect initial codes. At this stage, the aim is to identify central themes that emerge from gathered data, transforming raw information into coherent concepts. This process involves grouping related data excerpts and examining their relationships to ensure a robust understanding of the core issues.
To effectively conduct axial coding, follow these steps:
- Identify Core Categories : Examine the initial codes and determine central themes.
- Organize Data : Reassemble the data around these themes, creating a framework for analysis.
- Explore Relationships : Investigate how different themes interact, helping to reveal patterns and insights.
- Refine Codes : Continuously update and refine codes based on the evolving understanding of the data.
This systematic approach clarifies the narrative within the data, enhancing the depth and quality of qualitative analysis. In turn, it allows researchers to derive reliable insights that inform further studies or practical applications.
Advanced Techniques in Qualitative Data Coding
Advanced techniques in qualitative data coding enhance understanding and interpretation of qualitative research data. By applying these strategic approaches, researchers can identify patterns and themes that might initially go unnoticed. Effective data coding allows for more nuanced insights, fostering a comprehensive analysis that supports robust findings.
One key technique is thematic coding , where researchers categorize data by identifying overarching themes. Another important method is in vivo coding , which utilizes participants' own words to maintain authenticity and context. Additionally, using mixed coding methods can combine approaches for richer analysis. Lastly, collaborative coding encourages multiple researchers to analyze data collectively, enhancing reliability and integrating diverse perspectives. Each technique contributes uniquely to qualitative data coding, enriching the overall research process and outcomes. Such advanced strategies ensure that insights derived are not only detailed but also meaningful to the study's objectives.
Selective Coding: Refining Themes
Selective coding is a vital aspect of qualitative data coding that allows researchers to refine and consolidate identified themes. At this stage, you will focus on the central categories that emerged during preliminary coding, ensuring they accurately reflect the data. Engaging with this process helps illuminate connections among different themes, revealing deeper insights that may not have been apparent initially.
To effectively carry out selective coding, follow these key steps:
Identify Core Categories : Review the themes identified during earlier coding stages, focusing on those that are most relevant to your research questions.
Group Related Themes : Combine themes that share commonalities, creating broader categories to simplify and clarify the findings.
Review and Revise : Continuously revisit these categories to ensure they remain true to the data and reflect any new insights gained during analysis.
Develop a Narrative : Formulate a compelling story that integrates your core categories, helping convey the significance of your findings in a coherent manner.
This approach enhances the clarity and impact of your qualitative findings, ultimately contributing to a more robust analysis.
Ensuring Rigor in Qualitative Data Coding
Ensuring rigor in qualitative data coding is essential for the credibility of research findings. One effective approach is to establish clear coding guidelines before beginning the analysis. This includes determining code definitions and ensuring they align closely with the research questions. A second key aspect is maintaining consistency across coding efforts. Involving multiple coders can help validate the coding process, but it’s important to hold calibration sessions to align their interpretations.
Furthermore, revisiting the data and codes regularly during analysis fosters a deeper understanding of the emerging themes. This iterative process allows researchers to refine codes as new insights come forward. Lastly, using tools that support transparency in coding decisions can enhance rigor. Documenting code applications and interpretations helps ensure that qualitative data coding stands up to scrutiny and supports robust conclusions, empowering researchers to confidently communicate their findings.
Conclusion: Mastering Qualitative Data Coding in Your Research
Mastering qualitative data coding is essential for researchers aiming to extract meaningful insights from their data. This process involves categorizing, comparing, and interpreting qualitative information, allowing researchers to uncover themes and patterns that may not be immediately visible. Through effective coding, researchers can transform raw data into structured findings that can inform decisions and enhance understanding.
Embracing qualitative data coding requires practice and an awareness of potential biases. By employing systematic coding techniques, researchers can ensure a more objective analysis. Ultimately, mastering this skill will not only improve the quality of your research but also empower you to communicate your findings more clearly and convincingly to your audience.
Turn interviews into actionable insights
On this Page
Coding for qualitative research: AI-powered tools
You may also like, improving customer interactions with voice analytics for call centers.

Effective strategies using sentiment analysis in customer feedback
How to choose call center voice analysis software effectively.
Unlock Insights from Interviews 10x faster
- Request demo
- Get started for free
The Coding Manual for Qualitative Researchers (3rd edition)
Qualitative Research in Organizations and Management
ISSN : 1746-5648
Article publication date: 12 June 2017
Wicks, D. (2017), "The Coding Manual for Qualitative Researchers (3rd edition)", Qualitative Research in Organizations and Management , Vol. 12 No. 2, pp. 169-170. https://doi.org/10.1108/QROM-08-2016-1408
Emerald Publishing Limited
Copyright © 2017, Emerald Publishing Limited
The Coding Manual for Qualitative Researchers addresses an important aspect of many qualitative research traditions, the process of attaching meaningful attributes (codes) to qualitative data that allows researchers to engage in a range of analytic processes (e.g. pattern detection, categorization and theory building). It is a book intended to “supplement introductory works in the subject” and provide an extensive collection of coding methods from a range of sources for a variety of purposes. It is a book that is probably best positioned to those in somewhere in the middle of the beginner-experienced continuum of qualitative researchers, especially to those looking for examples of different ways to analyze qualitative data.
Saldaña states that this manual “serves primarily as a reference work” rather than a monograph to be read cover to cover. This is a claim important for a prospective reader to understand, and one that I agree with to a certain extent. A good reference work needs to have widely understood content in order for readers to know what to look for, and in this way the primary organizing scheme of the book into chapters on first and second cycle coding methods (and subsequently into a multitude of subcategories) is difficult to understand without a high degree of familiarity with this terminology. The opening chapter does a good job of exemplifying different approaches to coding and clarifying related terminology (e.g. patterns, codifying, categorization and themes) in a way that is helpful to the novice qualitative researcher. Perhaps less helpful in this part of the manual is the quick reference to dozens of specific coding types that are elaborated upon in later chapters and defined in the glossaries contained in the book’s appendices. Despite what for me is too much material covered in only a surface way to start the manual, it is otherwise well organized, through and thoughtful.
Saldaña’s many examples are very helpful, showing how particular data segments can be coded. Where this was particularly helpful was in the otherwise unclear discussion of selecting the appropriate coding method(s) for a particular study to start Chapter 3. That chapter alone describes 33 choices of “first cycle coding methods,” those that happen during the initial stages of data analysis. Arguably it is difficult to provide a concise answer to that question, because quite obviously the decision rests on many factors related to the researcher and the phenomenon researched. It was therefore interesting to see a short example of how an interview excerpt could be coded using descriptive codes (what is being talked about), in vivo codes (derived from the actual language used) and process coding (conceptual actions relayed by participants), each producing different yet equally valid insights about qualitative data.
Another useful aspect of the manual is the discussion of how computer-aided qualitative data analysis software (CAQDAS) can be used, complete with screen shots from many of these programs. The companion website provides a wide range of online resources, particularly to the CAQDAS options available to researchers. I agree with Saldaña’s claim that manual data analysis processes are perfectly fine for small-scale projects, but can be less than efficient or manageable with larger qualitative data sets. I dislike seeing “manual coding” compared with “CAQDAS coding” because it suggests that a computer does the coding. What appears as an artificial distinction between manual and electronic coding largely disappears as examples are given and emphasis is given to the role of the researcher to provide analytic reflection.
Saldaña does a generally good job of balancing the art and science of coding. From early on in the manual, he makes it clear that coding is “primarily an interpretive act,” one that can be done in a variety of equally compelling ways. He effectively discusses the writing of analytic memos (Chapter 2) in a way that I think is helpful and inspirational for researchers, highlighting how good qualitative research is not only about using good/proper methods, but more importantly about good thinking. By providing a categorization of the ways in which qualitative data can be reflected upon, and indeed become part of a cyclical process of data analysis, readers of all types can likely find new and interesting ways to relate to their data that move them beyond simple description of what is being said and the production of a journalistic account of respondents.
The Coding Manual for Qualitative Researchers seems well positioned to a graduate student or researcher who is looking for a synthesis of the many extant approaches to analyzing qualitative data. Experienced researchers would no doubt glean some techniques and terminology from the manual, but likely ones that make marginal refinements to the approaches they already know and/or use. Novice qualitative researchers, on the other hand, will probably find this manual overwhelming and lacking in a thorough discussion of a manageable number of approaches to coding qualitative data and sometimes awkward integration of coding examples. Researchers and students less familiar with analyzing qualitative data would benefit from reading one of the many good books on the topic, for example David Silverman’s Doing Qualitative Research: A Practical Handbook (Sage), Pushkala Prasad’s Crafting Qualitative Research: Working in the Postpositivist Traditions (Routledge) or Jennifer Mason’s Qualitative Researching (Sage). For those in between, however, the range of examples, suggestions for additional readings, companion website and exercises/activities in the appendices should contribute to expanding the horizons of researchers, educators and students in the social sciences.
Related articles
All feedback is valuable.
Please share your general feedback
Report an issue or find answers to frequently asked questions
Contact Customer Support
Click through the PLOS taxonomy to find articles in your field.
For more information about PLOS Subject Areas, click here .
Loading metrics
Open Access
Peer-reviewed
Research Article
A qualitative study of stressors faced by older stroke patients in a convalescent rehabilitation hospital
Roles Formal analysis, Investigation, Methodology, Writing – original draft
* E-mail: [email protected]
Affiliation Department of Occupational Therapy, Tokyo Bay Rehabilitation Hospital, Narashino, Chiba, Japan
Roles Writing – review & editing
Affiliation Department of Occupational Therapy, Teikyo Heisei University, Toshima, Tokyo, Japan
Affiliation Department of Occupational Therapy, Saitama Medical Center, Kawagoe, Saitama, Japan
Affiliation Faculty of Human Sciences, Graduate School of Comprehensive Human Sciences, University of Tsukuba, Ibaraki, Japan
- Yuta Asada,
- Kaori Nishio,
- Kohei Iitsuka,
- Published: August 26, 2024
- https://doi.org/10.1371/journal.pone.0309457
- Peer Review
- Reader Comments
This study aimed to explore the stressors experienced by older patients with stroke in convalescent rehabilitation wards in Japan. Semi-structured interviews were conducted with four stroke patients aged > 65 years who experienced a stroke for the first time in their lives. The interviews were analyzed using the Steps for Coding and Theorization method for qualitative data analysis. The results of the qualitative analysis demonstrated that patients experienced specific stressors, such as, difficulty in movement of the paralyzed hand, fear of stroke recurrence, and dietary problems. Some stressors were manageable through healthcare professionals’ active and sensitive communication strategies. These stressors were derived from the theoretical framework of “stressors related to hospitalization” and “stressors related to the illness”. Additional stressors emerged from the interaction between these two types within the theoretical framework. The results of this study contribute to a deeper understanding of the specific stressors experienced by older stroke patients during the recovery process.
Citation: Asada Y, Nishio K, Iitsuka K, Yaeda J (2024) A qualitative study of stressors faced by older stroke patients in a convalescent rehabilitation hospital. PLoS ONE 19(8): e0309457. https://doi.org/10.1371/journal.pone.0309457
Editor: Chinh Quoc Luong, Bach Mai Hospital, VIET NAM
Received: February 24, 2024; Accepted: August 13, 2024; Published: August 26, 2024
Copyright: © 2024 Asada et al. This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Data Availability: All relevant data are within the manuscript and its Supporting Information files.
Funding: The author(s) received no specific funding for this work.
Competing interests: The authors have declared that no competing interests exist.
Introduction
Stress is a nonspecific response of the body to external stimuli [ 1 ]. Stress varies as the stressors faced by individuals differ depending on their age, sex, and social role [ 2 ]. Stressors include physical, biological, chemical, psychological, and social factors. The accumulation of these stressors causes stress, which, if not adequately addressed, can lead to physical or mental health problems, such as cardiovascular disease and depression, respectively [ 3 ]. To prevent these stress-related diseases, it is imperative to identify and address the stressors.
Patients often face various stressors in inpatient settings as their physical and human environments differ significantly from those of their regular home settings [ 4 ]. As the length of the hospital stay increases, patients may become particularly vulnerable to stressors such as “concern for family” and “anxiety about financial situation” [ 4 ]. The severity of a stroke, the age of the patient, and the presence of underlying medical conditions are factors that tend to extend the duration of hospitalization [ 5 ]. The incidence of stroke increases with age and is more common among older adults [ 6 ]. Moreover, patients present with a variety of symptoms, such as motor paralysis and higher brain dysfunction, and their ability to perform activities of daily living (ADL) becomes more limited. In particular, convalescent rehabilitation hospitals have a prolonged hospital stay [ 7 ] as one of their goals is to help patients return to the community and their homes.
Much of what is known about stressors related to stroke involves the risk of stroke onset [ 8 , 9 ], and there are insufficient studies on the stressors faced by older stroke patients in hospitals. Clarifying these unspoken stressors can contribute to reducing the stress of hospitalization for older stroke patients during convalescent rehabilitation, meeting their true needs, and enriching their lives after discharge. Few studies have elicited patients’ true feelings regarding stressors in convalescent rehabilitation wards. The purpose of this study is to provide a deeper understanding of the specific stressors experienced by older stroke patients in convalescent rehabilitation wards during their hospital stay.
Materials and methods
We conducted a qualitative study and interviewed each participant separately. The interview transcripts were analyzed according to the “Steps for Coding and Theorization” method (SCAT), a sequential and thematic qualitative data analysis technique [ 10 – 12 ].
This study was conducted in accordance with the Consolidated Criteria for Reporting Qualitative Research (COREQ), a checklist designed to improve the transparency and reliability of qualitative research [ 13 ] (S1 Table in S1 File ).
Preparation for the study
The first author (hereafter, “the author”) is a M.S. student in comprehensive human sciences and male occupational therapist with six years of clinical experience in recovery rehabilitation. Before this study was conducted, the author reviewed the literature on SCAT, conducted an analysis, and attended a workshop for SCAT developers to deepen his understanding of the analysis methods to ensure the accuracy of the analysis [ 10 – 12 ].
Participants
Patients aged 65 years or older, experiencing stroke for the first time, and hospitalized in a recovery center were included in the study. Patients who had difficulty answering the interview questions owing to the effects of aphasia, hospitalized patients in the charge of an interviewer, patients diagnosed with dementia or psychiatric disorders, and patients who were hospitalized for a short period of approximately one month were excluded.
Patients were asked to cooperate in the study and fully informed about the purpose and significance of the study, research methods, voluntary nature of research cooperation and freedom to withdraw, and handling of personal information. Signing a consent form indicated patients’ willingness to cooperate in the study.
Interview procedure
Three interviews were conducted between June and November, 2022. The interviewer asked questions according to an interview guide. Semi-structured in-person interviews were conducted in a private room in the hospital that the author is affiliated with, involving the patients and interviewer only. The first interview was conducted at the time of hospital admission, and subsequent interviews were conducted several times, with a gap of approximately one month. The interviews were recorded with the participants’ consent using the voice recorder function of an iPad and transcribed afterwards. The interview transcripts were not returned to participants for comments or correction. The interviewer recited the patients’ statements to them and made efforts to confirm the content of the statements to ensure data accuracy.
The interview guide was developed based on a preliminary survey of two stroke patients to determine ease of response. The content of the interview guide was first explained to the participants through specific examples to help them fully understand the difference between “stress” and “stressors.” The guide began by explaining, through specific examples, what the stressors in this study were. To investigate the stressors faced by older stroke patients in recovery, we asked, “What comes to mind when you hear the term ‘stressors in hospitalization’?”
Data analysis
We predicted that the outcome of the interviews would be strongly influenced by the participants’ individual characteristics. Therefore, to obtain objective results, we used the SCAT technique that specializes in coding and theorization and can be applied to a small amount of data. The SCAT method consists of the following steps [ 10 – 12 ]:
Step 1: Focus words from within the interview texts.
Step 2: Words outside the text that can replace the words from Step 1.
Step 3: Words that explain the words in Step 1 and Step 2.
Step 4: Themes and constructs, including the process of writing a story and offering theories that weave the themes and constructs together.
As this study was designed to create multiple storylines from a single participant, we integrated those multiple storylines into a single storyline and wrote a theoretical description, ensuring no loss of chronological contextuality and individuality of the storylines. The data analysis and confirmation process were conducted by the author and three other authors who were not involved in the interview process.
Ethical considerations
This study was approved by the Ethical Review Committee (Approval No. 289–2) of Tokyo Bay Rehabilitation Hospital.
Basic attributes of the participants
Five participants who met the inclusion criteria were recruited for the study. One participant (female) was excluded owing to early discharge from the hospital on short notice. Thus, four patients (two male and two female) were included in the study. The participants’ average age was 79.3 years (range: 71–88 years). Their disabilities included cerebral hemorrhage (one patient) and cerebral infarctions (three patients).
The average duration of the series of 12 interviews was 20.3 minutes, ranging from 7.5 to 32.7 minutes.
Storyline and theoretical descriptions
In the sections below, the storylines and theoretical descriptions as well as quotes from each participant, are described.
Case 1: Mr. A, facing an inconvenient situation.
At the time of the first interview, Mr. A experienced stress owing to an inconvenient situation during hospitalization. He was unable to perform the activities he did before the onset of the disease, especially owing to the psychological burden caused by the inability to eat and drink according to his preferences. He also expressed dissatisfaction with the current situation, limitations in leisure-time activities, inconvenience of activities, and a sense of shame caused by assistance with bathing. Limited leisure-time activities resulted from challenges in moving his paralyzed hands. He specifically encountered difficulties in willingly engaging them to act. Furthermore, he was separated from his family as a result of hospitalization. Thus, he faced restrictions in eating and drinking luxury foods, lack of freedom in daily life, and lack of family time.
“ Not being able to do things freely is the biggest stressor. All in all, there’s nothing better than that. I can’t eat what I like, or drink a lot. Even if I have a computer, I can’t use my right hand. I can’t even do my own hobbies. And, it is still significant whether or not you have a wife nearby.”
At the time of the second interview, Mr. A experienced stress regarding eating and drinking, including dissatisfaction with the variety of meals compared to before the disease onset, and the psychological burden owing to meals not being replaced on a daily basis. This was also the minimum element that Mr. A looked for during hospitalization. Other stress factors included a feeling of disappointment owing to limited leisure-time activities, and feelings of activity limitation and resignation owing to the inability to walk independently.
“ The most important thing is the food. Anyway, there’s nothing to do, so at least a meal, you’d think, wouldn’t you? The food is different from when we’re at home. It doesn’t help that I can’t walk. And, I think it’s a bit hard not to have hobbies.”
At the time of the third interview, Mr. A expressed that his biggest stress factor was difficulty moving his paralyzed dominant hand. This significantly impacted his daily self-care, including toileting and grooming. He also encountered limitations in various leisure activities, such as reading books. Eating and drinking induced a significant psychological burden. He felt dissatisfied with the lack of variety in meals as he could not manage to eat as well as previously.
“ Whatever I do, my hands don’t work. For example, when you brush your teeth. It’s the same when you go to the toilet and wipe your bottom. I can’t use my right hand. Also, I like books and I want to read, but I can’t turn the pages. And, unlike in the past, I eat rice and side dishes every day. My eating habits have changed drastically.”
Case 2: Ms. B, facing stressors caused by communal living.
At the time of the first interview, Ms. B faced stressors related to basic lifestyle habits, such as falling asleep and toileting, in the hospital. Variations in individual lifestyles and environmental factors, like noise and room brightness, contributed to sleep deprivation in shared living arrangements. Furthermore, inadequate management of the paralyzed side during sleep led to anxiety and sleep deprivation. Problems related to toileting needs arose owing to overlap in toilet timings with roommates and assisted by staff of the opposite sex.
“ I sometimes have trouble sleeping well at night because of noises or brightness. Everyone is trying to go to the toilet before rehabilitation, so the timing is… And with male nurses, there was a bit of resistance to using the toilet. After all, in shared living arrangements, everyone has a different rhythm of life.”
During the second interview, Ms. B continued to face stress owing to communal living. Stressors included abnormal breathing noises caused by roommates when falling asleep, noise problems during roommates’ movements, and nocturnal awakenings caused by physical environmental factors such as differences in depth of sleep. Additionally, there were case of sleep problems caused by the staff’s response to a roommate’s problematic behavior, and case of nocturnal awakenings caused by noise from staff responses. Other issues included self-perceived persistent distress over defecation problems and dealing with defecation needs in a time-constrained environment, with a roommate.
“ Like last time, in shared living arrangements, everyone has a different rhythm of life, but it can’t be helped. Sleep, you know, because some people go to the toilet at night or early in the morning, so it’s quite noisy and you can’t sleep well. And the nurse puts the patient next to me to sleep, and there are all sorts of noises when she does that. We all have the same desire to go to the toilet before rehabilitation, so we don’t make it in time. Toilets are a perpetual problem.”
At the time of the third interview, Ms. B had problems with how he interacted with his roommates and stressors related to falling asleep at night. Ms. B was dissatisfied with differences in personal characteristics in communal living, and concerned about the deterioration of his relationship with his roommates over defecation. Furthermore, stress was caused by differences in lifestyle in communal living affecting sleep and awakening during the night owing to physical environmental factors such as noises made by roommates. Sudden changes in training hours also caused dissatisfaction.
“ Like how to communicate with people in the room. Like sleeping. Because of the lights and noise when my roommate goes to the toilet at night. Roommates have different living patterns. In rehabilitation, though, there were some questionable things like time changes.”
Case 3: Ms. C, facing an excrement problem and anxiety about stroke recurrence.
At the time of the first interview, Ms. C faced the problem of excrement in communal living. Dissatisfaction was caused by the suppression of excretory behavior and rejection of excretion in communal living, leading to anxiety. There were also conflicts and a psychological burden caused by the staff’s lack of information sharing, which led to restraining from defecating after unpleasant experiences.
“ I don’t like the situation of one toilet for four people. I and others are suffering. I thought it was hard. I didn’t know that you have to press the nurse call. Then I wished they had told me from the beginning. That was a bit of a shock.”
At the time of the second interview, Ms. C expressed dissatisfaction with their lack of independence in elimination. This led to a sense of aversion caused by dealing with the need to defecate frequently during the night and self-consciousness about requests for nighttime defecation assistance, which, in turn, led to resisting the need to defecate, a distressing experience unique to the patient.
“ I feel bad because I have to go to the toilet in the middle of the night. But I try to be patient. If it was during the day, I would ask the nurse to help me, but at night I would still feel sorry. It’s painful. You have to be experienced to understand.”
At the time of the third interview, Ms. C was anxious about the gap between their life at home after discharge and their life in the hospital and about the gradual decline of their brain functions. They also experienced anxiety owing to the fear of stroke recurrence and an undecided medical support system for the prevention of recurrence. These stressors were related to worry caused by a lack of information sharing by the staff and delays in sharing information about discharge from the hospital.
“ I have a little bit of anxiety about my future and my life. Because I’ve got comfortable here. And I don’t know what I would do if I fell ill again. No one is going to talk to me about it. I’m a bit worried about that. That’s what I’m most worried about.”
Case 4: Mr. D, facing a meal problem.
At the time of the first interview, Mr. D expressed their stress that they had to hold their toileting until the hospital staff arrived when they needed to defecate. This occurred as the hospital staff were extremely busy, and they experienced failure in excretory management. However, at the time of the interview, they were able to use the toilet independently.
“ I’ve had a leak before the nurse came. She can’t come right away, she’s too busy. It’s gone now.”
At the time of the second interview, Mr. D had a low appetite owing to low-temperature meals and refused to eat as a result of inappropriate meal temperature. Additionally, there were difficulties with grooming movements around the use of the wash basin and dealing with the need to defecate in communal living.
“ The rice and side dishes are cold. So I feel sorry to leave it. I can eat it beautifully when it’s warm. But when it’s cold, I just can’t. After the meal, I can’t wash my hands because some people wash their hands in their rooms first. When I want to go into the toilet, there are people ahead of me. It can’t be helped.”
In the third interview, Mr. D felt stress when the meal was not hot enough to eat and lost their appetite. He also felt stress when his mealtime was delayed as it that cause would take time for them to do their personal grooming after returning to their room where their roommate occupied t the wash basin.
“ Side dish is cold. Wish it was room temperature. I eat my meals late, so I’m the last one to go back to my room. So, I can’t wash my hands first.”
In this study, semi-structured interviews were conducted to identify the stressors faced by older patients with stroke during convalescent rehabilitation, throughout hospitalization; data analysis was conducted using SCAT.
Based on the storylines and theoretical descriptions, the stressors experienced by stroke patients were categorized into “stressors related to hospitalization” and “stressors related to the illness” [ 4 ].
Stressors related to hospitalization
The results of this study revealed that older stroke patients in convalescent rehabilitation face stressors related to ADLs, such as eating, sleeping, grooming, and toileting; leisure activities; problems with roommates in communal living; and inability to be with their family members. In this study, the first interview was conducted at the time of admission, and stressors were reported by all participants. Stress during hospitalization is caused by the fact that patients are forced to live a life with less freedom than before [ 4 ].
The psychological burden is particularly high for older adults as they have a reduced ability to adapt to changes in the external environment compared with younger patients [ 14 ]. In light of the above, older stroke patients may face a variety of stressors from the early stages of hospitalization compared with younger patients; therefore, intervention against these stressors is necessary from the early stages of hospitalization.
Factors such as relationships with roommates may lead patients to experience discomfort [ 15 ], and the way patients relate to their roommates is considered important. In this study, physical environmental factors caused by differences in lifestyle and the timing of toilet and wash basin use with roommates emerged as stressors. Additionally, these factors affected the participants’ ADL, such as grooming, toileting, and sleeping. Considering these findings, it is important for patients living together to consider each other’s needs. Therefore, it is necessary for patients to communicate with each other to deepen their understanding, and healthcare professionals are expected to play a role in building such relationships.
Furthermore, stressors such as meal variations and meal temperature emerged rather than stressors such as taste and preference. Older people tend to experience a decline in dietary variety owing to a decline in physical and oral functions and appetite [ 16 ]. Moreover, older patients undergoing treatment for cerebrovascular disease are more likely to experience changes in food preferences than younger patients [ 17 ], which is not consistent with the results of the present study. Given that the amount of food intake in a hospital setting is linked to the quality of food, including taste and the dining environment [ 18 , 19 ], there is a need for further research on qualitative aspects of meal preparation, such as food variations and appropriate temperatures. However, studies on meal variations and temperature are limited. In the future, these should be investigated in detail as characteristic stressors faced by older stroke patients during convalescent rehabilitation.
Stressors related to the disease
The results revealed that older stroke patients in rehabilitation face stressors such as difficulty moving the hand affected by motor paralysis, recurrent strokes, lack of information given by healthcare providers, and inappropriate actions or words of healthcare providers. Approximately 50% of stroke survivors experience unilateral motor paralysis [ 20 ]. Improvement in motor paralysis of the upper limbs and fingers contributes to greater independence in ADL [ 21 , 22 ]. It not only affects ADL but a wide range of activities, such as housework and leisure activities [ 23 , 24 ].
In this study, there were patients whose hobbies were limited by difficulty in moving the paralyzed hand. Additionally, based on the interviews at the time of admission, activity limitation caused by paralysis was a stressor faced from the time of admission itself. Therefore, early interventions and psychological support are needed for patients with paralysis.
A lack of information about the disease may also increase patient anxiety and cause dissatisfaction among healthcare providers [ 4 ]. Stroke recurs at a rate of 2.2% to25.4% within one year of disease onset, 12.9% within two years, and approximately 16% within five years [ 25 ]. Therefore, it is important to support stroke patients to prevent recurrence [ 26 ]. The participants were interviewed before discharge from the hospital about stressors such as recurrent stroke and lack of information provided by healthcare providers. This suggests that providing information to older patients with stroke undergoing convalescent rehabilitation to prevent recurrence is very important, especially for patients who are about to be discharged from the hospital, and that a lack of information can cause stress. Furthermore, communication between stroke patients and healthcare professionals does not always match [ 27 ]. Efforts should be made to prevent a lack of information, considering the patient’s cognitive function and the degree of higher brain dysfunction.
Additionally, stressors such as the personal care of patients by healthcare professionals of the opposite sex, and behaviors and words caused by misunderstandings on the part of healthcare professionals emerged. Patients may experience discomfort and high psychological distress owing to factors such as the attitudes and actions of healthcare workers [ 16 , 28 ]. An inadequate explanation or lack of consideration of shame may also arouse anger in patients [ 29 ]. Stroke patients are placed in a situation where they are prone to feelings of shame owing to assistance with ADL such as bathing and toileting. Therefore, healthcare professionals must be sensitive to patients when providing daily care. Stress can be prevented through appropriate attitude and information sharing.
Various symptoms, such as motor paralysis, sensory disturbance, higher brain dysfunction, and cognitive decline, appear as post-effects of stroke. The complex interplay between these symptoms causes a decline in the ability to perform ADL [ 30 – 32 ]. In this study, there were patients for whom difficulty in achieving independence in ADL was a stressor. Patients with higher levels of ADL independence had higher self-efficacy, and successful experiences were effective in forming self-efficacy [ 33 ]. This principle should be applicable to older stroke patients in convalescent rehabilitation hospitals. The positive outcomes of their hospital experience may be partially attributed to reduced stress.
Additionally, some patients faced limitations in self-care, stressors related to hospitalization owing to the aftereffects of stroke, and stressors related to illness. Given these findings, it was suggested that stroke patients may have been stressed by the interaction of “stressors related to the disease” and “stressors related to hospitalization.” However, if one of these stressors can be adequately addressed, it is likely that related stressors can be reduced.
Limitations
In conclusion, we clarified the stressors faced by older stroke patients in convalescent for rehabilitation. However, this study has some limitations. First, the study was severely limited by the small number of patients, which prevents us from drawing some important conclusions. The SCAT method can be used to analyze data from a small number of people because it provides a theoretical description from the participants’ storylines; however, the number of participants in this study was not sufficient to generalize the findings. Second, this study did not fully consider the participants’ individual characteristics, such as personality and background, nor did it analyze the patients in terms of their pathology and sequelae. Therefore, the results obtained should be interpreted carefully, as individual bias was not sufficiently eliminated. In future, it is necessary to select other participants and data analysis methods that consider participants’ individual characteristics and the aftereffects of stroke and recruit more participants to elucidate the stressors faced by older stroke patients in convalescent rehabilitation.
Stressors specific to older stroke patients were identified, including difficulty moving the paralyzed hand, recurrent stroke, and diet-related stressors. Stressors identified in this study can be broadly classified into “stressors related to hospitalization” and “stressors related to the disease,” consistent with previous studies [ 4 ]. However, it was found that stress is also caused by the interaction between “stressors related to hospitalization” and “stressors related to the disease.” To the best of our knowledge, thus far, no reports have identified the specific stressors faced by older stroke patients. Therefore, this study provides valuable information from a first-hand perspective that will lead to a deeper understanding of the specific stressors experienced by older stroke patients during recovery. Future studies should explore how various stressors lead to stress in older stroke patients at various types of rehabilitation hospitals.
Supporting information
S1 file. consolidated criteria for reporting qualitative studies (coreq): a 32-item checklist..
https://doi.org/10.1371/journal.pone.0309457.s001
Acknowledgments
We thank all the participants who agreed to be interviewed for this study. We also thank the members of the Rehabilitation Science Degree Program, Graduate School of Comprehensive Human Sciences, University of Tsukuba, for their guidance and encouragement during this study.
- View Article
- PubMed/NCBI
- Google Scholar
No products in the cart.
NVivo 15: Grow Your Research Team with Qualitative Data Analysis Software (QDA Software)

The Most Trusted QDA Software is Even Better
We're thrilled to announce the release of NVivo 15, the latest version of Lumivero's most trusted qualitative data analysis (QDA) software*. This release is designed to revolutionize the way researchers analyze qualitative data, incorporating advanced Lumivero AI Assistant features and new tools that enhance efficiency across the board.
Driven by customer feedback, NVivo 15 addresses the growing need for more streamlined workflows and efficient qualitative research methods, ensuring researchers can achieve insightful and accurate results with greater ease and speed. With NVivo 15, researchers can organize and explore data from any source, visualize connections that are difficult to find manually, and use our Lumivero AI Assistant to start to dive into the details.
Continue reading to learn more about NVivo 15 or request a demo to see for yourself!
SEE NVIVO IN ACTION
Contact us to learn how you can provide NVivo to all researchers at your college or university and be assured that they are using the most widely cited QDA software in the world.
Revolutionizing Qualitative Data Analysis with AI
The standout feature of NVivo 15 is its groundbreaking Lumivero AI Assistant. This powerful tool is designed to enhance data analysis efficiency and accuracy, giving researchers more time to focus on data analysis for their research project.
New Features with NVivo 15’s Lumivero AI Assistant:
- Unpack Jargon or Technical Language: Leverage AI text summarization to explain unfamiliar terms or local idioms, saving you time from searching for answers. Quickly select the text and have NVivo 15 summarize the selection which is then added to the document as an annotation.
- Dive into Reflective Thinking: Enjoy diving into the depths of rich data but need a break from reading endless pages? NVivo’s AI document summarization brings memoing to the forefront of analysis. Seamlessly select any type of document or document(s) within NVivo 15 and summarize each of them in seconds allowing you to get a sense of each document immediately. The summaries are added in a memo linked to its document where you can reflect further, iteratively returning to each document for further insights and/or start to develop a coding framework.
- Fine tune your coding: Ever lose the rhythm when coding for a while? Dig deeper into codes you already created by using NVivo’s AI coding suggestions to suggest finer level codes. The Lumivero AI Assistant shows the evidence for the proposed codes, giving the researcher total control over what to accept. With NVivo, nothing is cast in stone, giving you the freedom to explore your data dynamically and intuitively.
All your data stays your data when using NVivo 15’s Lumivero AI Assistant. Once the AI completes its task, the information is sent to your NVivo project and deleted from the local servers.
Enhanced Data Organization: Unclutter Your Desktop, Unclutter Your Mind
Working with qualitative data can be messy, but NVivo makes organizing your data a breeze. With NVivo, you can keep all your data organized and accessible, allowing you to pull out insights as needed for effective qualitative analysis. This organizational capability helps to maintain a clear mind and a focused research process, making it easier to manage complex data sets and ensure nothing is overlooked.
Intelligent Data Analysis: Differences Analyzed and Patterns Revealed
NVivo excels in providing deeper insights into your data. It gives a voice to every data point, enabling intricate comparisons not only among respondents but also their organizations or any unit under analysis. Cases, classifications, and attributes highlight differences and unexpected similarities, providing a richer understanding of your data.
For those not satisfied with one-dimensional analysis, NVivo’s crosstabs feature uncovers hidden patterns by contrasting differences among respondents. This tool for qualitative data analysis offers profound insights and clarity, and for those needing more statistical analysis, NVivo allows for exporting data to Lumivero’s XLSTAT . Additionally, NVivo offers the most comprehensive set of text analysis tools and coding queries, enabling you to cut your data in myriad ways to reveal hidden patterns and fresh insights.
Prioritizing Data Privacy and Security in Qualitative Data Analysis Software
As with all Lumivero solutions, NVivo 15 prioritizes data privacy and security. The Lumivero AI Assistant ensures that all your data remains secure throughout the analysis process. Once the AI completes its task, the information is securely sent to your NVivo project and deleted from local servers, preventing any data from residing on outside servers. This ensures that your data stays confidential and protected.
QDA Tools for Enhanced Cross-Platform Compatibility
Beyond its innovative AI features, NVivo 15 excels in cross-platform compatibility, allowing seamless syncing of projects across Mac and Windows. This functionality goes beyond eliminating the file conversion process, enabling users to effortlessly open and manage projects on both operating systems.
With NVivo 15, users can not only open work on projects across both Mac and Windows with ease but also all Mac teams can use NVivo Collaboration Cloud . This ensures greater flexibility and productivity in their qualitative data analysis.
Try NVivo 15 for Your Qualitative Research Today
NVivo 15 is more than just an update; it's a revolution in qualitative data analysis. With the advanced Lumivero AI Assistant and user-centric enhancements, NVivo 15 empowers researchers to achieve more insightful and accurate results in less time. Embrace the future of qualitative data analysis with NVivo 15.
Need help choosing QDA software for your research? Request your free trial of NVivo 15 or request a free demo to see NVivo in action!
*(Scopus Database, NVivo citations compared with competitors 2010-2023)
Recent Articles
- Open access
- Published: 25 August 2024
Navigating sexual minority identity in sport: a qualitative exploration of sexual minority student-athletes in China
- Meng Xiang 1 , 2 ,
- Kim Geok Soh 2 ,
- Yingying Xu 3 ,
- Seyedali Ahrari 4 &
- Noor Syamilah Zakaria 5
BMC Public Health volume 24 , Article number: 2304 ( 2024 ) Cite this article
103 Accesses
Metrics details
Sexual minority student-athletes (SMSAs) face discrimination and identity conflicts in intercollegiate sport, impacting their participation and mental health. This study explores the perceptions of Chinese SMSAs regarding their sexual minority identities, aiming to fill the current gap in research related to non-Western countries.
A qualitative methodology was adopted, utilising the Interpretive Phenomenological Analysis (IPA) approach with self-categorization theory as the theoretical framework. Participants were recruited through purposive and snowball sampling, and data were collected via semi-structured interviews, documents, and field notes. Sixteen former and current Chinese SMSAs participated in this study.
The study reveals four themes: hidden truths, prioritisation of athlete identity, self-stereotyping, and attempt. The results revealed that while SMSAs were common in intercollegiate sport, their identities were often concealed and not openly discussed. The predominant focus on athlete identity in sport overshadowed their sexual minority identities. Additionally, SMSAs developed self-stereotypes that influenced their thoughts and behaviours. The non-heterosexual team atmosphere in women’s teams led to the development of intimate relationships among teammates.
Conclusions
The findings from this study could be incorporated into existing sport policies to ensure the safe participation of SMSAs in Chinese intercollegiate sports. This research offers valuable insights for the development and implementation of inclusive policies. Future research in China could investigate the attitudes of coaches and heterosexual student-athletes toward sexual minority identities to inform targeted interventions.
Peer Review reports
Collegiate sport serves as a conduit for hope, competition, learning, success, and enhanced well-being for students [ 1 , 2 ]. Within this context, situated at the intersection of student-athlete and sexual minority identities [ 3 ], sexual minority student-athletes (SMSAs) experience more challenges than their heterosexual counterparts. Sexual minority constitutes a group of individuals whose sexual and affectual orientation, romantic attraction, or sexual characteristics differ from that of heterosexuals. Sexual minority persons are inclusive of lesbian, gay, bi+, and asexual-identified individuals [ 4 ].
In an effort to enhance the support of SMSAs in sport, Team DC, the association of sexual minorities sport club, awarded seven SMSAs the 2023 Team DC College Scholarship [ 5 ]. Besides the Team DC scholarship, there are the Rambler Scholarship, US Lacrosse SMSAs Inclusion Scholarship, NCAA Women’s Athletics Scholarship and Ryan O’Callaghan Foundation [ 6 , 7 , 8 ]. These scholarships were set up to make sport a more welcoming and safer environment for SMSAs. In particular, the Sexual Minority Scholarship echoes the International Olympic Committee’s framework of equity, inclusion, and non-discrimination, which states that everyone has the right to participate in sport without discrimination and in a manner that respects their health, safety and dignity [ 9 , 10 ].
Despite efforts by educational and sport organisations to foster inclusivity, research shows that the sport environment remains hostile to sexual minority individuals [ 11 , 12 ]. In intercollegiate sport, empirical evidence points to persistent negative attitudes [ 13 , 14 , 15 , 16 , 17 ], which are expressed through marginalisation, exclusion, use of homophobic language, discrimination, and harassment [ 17 , 18 , 19 , 20 ]. SMSAs frequently confront the difficult choice of disclosing their identity, often opting for concealment. Denison et al. found that SMSAs who disclose their identity to their teams may face increased discrimination [ 21 ]. Pariera et al. also observed deep-rooted fears among SMSAs of being marginalised by their teams upon revealing their sexual orientation [ 22 ]. Consequently, the hostile environment led to lower participation rates among sexual minority youth compared to their heterosexual counterparts [ 23 ].
In China, there is a lack of clear public policies related to the sexual minority population [ 24 ]. Despite homosexuality being removed from the Chinese Classification of Mental Disorders-3 in 2001 [ 25 ]. China’s stance towards sexual minority issues remains ambiguous. Many scholars describe this attitude as “no approval, no disapproval, and no promotion” [ 26 , 27 , 28 , 29 ]. Due to the lack of legal protection, sexual minorities frequently encounter discrimination. A Chinese national survey revealed that only 5.1% of sexual minority individuals felt comfortable being open about their gender and sexual identity in China [ 30 ]. This discrimination is particularly severe among Chinese sexual minority youth, who are at higher risk of bullying in school and college [ 31 , 32 ]. These youths face childhood victimisation [ 33 , 34 , 35 ], which heightens their risk of mental and behavioural health issues [ 36 , 37 , 38 ], including non-medical use of prescription drugs [ 39 ], depression [ 40 , 41 ], and suicide [ 42 ].
While sports participation is crucial for the well-being of sexual minority individuals, research on the sports participation of sexual minority youth in China is limited. The literature highlights a significant gap in understanding the status and circumstances of SMSAs in China. Most existing studies focus on Western populations [ 43 , 44 , 45 ], overlooking the unique sociocultural interactions affecting SMSAs in non-Western contexts, making it challenging for China to apply these findings. Furthermore, the lack of reliable research on the interactions between sexual minorities and institutions in Chinese higher education hampers a comprehensive understanding of SMSAs’ situations. This research gap impedes the development of effective interventions to foster inclusivity. Persistent discrimination and inadequate protective policies underscore the urgent need for academic, policy, and practical advancements to support sexual minorities in China [ 46 ]. Therefore, the aim of this study was to explore SMSAs’ perceptions of their sexual minority identity in Chinese sports, providing insights to guide the creation of supportive educational and organisational strategies.
Homonegativity and discrimination in sport
Homonegativity refers to any prejudicial attitude or discriminatory behaviour directed towards an individual because of their homosexual orientation [ 47 ]. Compared to the more common term “homophobia,” [ 48 ] “homonegativity” more accurately describes negative attitudes towards homosexuality [ 49 ] because the fear is not irrational but is learned from parents, peers, teachers, coaches, and the daily interaction environment [ 50 ]. Sport context is an integral part of society, and an extensive body of research has consistently demonstrated the presence of homonegativity in sport [ 12 , 21 , 51 , 52 , 53 , 54 , 55 , 56 , 57 , 58 , 59 ].
Homonegativity can manifest in forms such as verbal harassment, physical violence, or discriminatory behaviours. The “Out on the Fields” survey, conducted in 2015, represents the first large-scale international study focusing on homophobia in sports [ 60 ]. Participants were from six countries: Canada, Australia, Ireland, the United States, New Zealand, and the United Kingdom. It revealed extensive discrimination in sport, with a high percentage of gay men and lesbians experiencing verbal slander, bullying, threats, and physical assault. The OUTSPORT project, completed in 2019 and funded by the European Union, is the first comprehensive EU-wide study on homophobia and transphobia in sport. The project collected data from over 5500 sexual minority individuals across all 28 EU member countries [ 61 ]. The results revealed that a significant portion of participants faced adverse experiences in sport contexts related to their sexual orientation and gender identity, including verbal abuse, structural discrimination, physical boundary crossing, and violence. An overwhelming majority of respondents (92.9%) view homophobia and transphobia in sport as current issues. Additionally, 20% of respondents reported avoiding participation in sport due to concerns about their sexual orientation or gender identity, while 16% of active participants experienced at least one related negative incident in the past year. Notably, male student-athletes exhibited higher levels of homophobic attitudes compared to their female counterparts and non-physical education students [ 15 , 16 , 62 ]. Conversely, female athletes reported experiencing less fear of exclusion and a more inclusive team environment [ 22 , 63 , 64 ], highlighting significant gender disparities in homonegativity in sport.
Group and individual identity
The distinct team interaction inherent in sport may enhance or support expressions of homonegativity and discrimination, as Social Identity Theory posits that negative beliefs about certain groups may develop group identity [ 65 , 66 , 67 ]. This phenomenon is particularly noticeable in intercollegiate sport, where a strong emphasis on physical attributes and abilities often results in prejudices against those who deviate from established norms [ 16 ]. Such discrimination and mistreatment of SMSAs frequently stem from their teammates and coaches. Many SMSAs choose to conceal their sexual orientation due to fear of ostracism [ 60 ], with team members often identified as the primary perpetrators of discrimination [ 61 ].
Therefore, navigating sexual identity within intercollegiate sport is challenging for SMSAs, as their minority status becomes a focal point, impacting their overall experience [ 68 , 69 ]. They encounter a unique psychological and emotional burden, striving to reconcile societal norms and expectations with their true selves. This constant negotiation and management of their identity across different contexts further complicates their experiences, frequently leading to difficulties in maintaining authenticity [ 19 ]. Therefore, SMSAs in intercollegiate sport face intricate challenges in balancing their authentic identity with societal norms, significantly impacting their experience and sense of self.
Theoretical framework
Self-categorisation theory (SCT), an extension of Social Identity Theory, provides a valuable perspective for examining the perceptions of SMSAs in China, focusing on intragroup processes and individual navigation of personal and social identities [ 70 , 71 ]. Key principles of SCT, including self-categorisation, salience, depersonalisation, and individuality [ 67 ], are instrumental in understanding how SMSAs navigate their sexual identities within the confines of sport norms. Applying SCT, this study could explore the complex interplay of intragroup relations and identity processes among SMSAs in the Chinese sport context, underscoring how contextual factors distinctly shape their identity.
Purpose of the study
The purpose of this study is to explore SMSAs’ perceptions of their sexual minority identity within the Chinese sports context and understand how this identity influences their participation in sports. By illuminating the specific challenges and issues related to sexual minority identity in Chinese intercollegiate sports, this study provides a deeper understanding of the experiences of sexual minorities in this field.
Research design
This study was conducted with the interpretivist paradigm, which emphasises understanding the subjective experiences and meanings that individuals assign to their world. It posits that reality is not objective but is constructed through individual perceptions and social interactions [ 72 ]. Given the aim of exploring the perceptions of sexual minority identity in sport from SMSAs’ perspectives, a qualitative research approach is appropriate. In line with the purpose of the study, the Interpretative Phenomenological Analysis (IPA) was adopted in this study, an approach aimed at understanding people’s lived experiences and how they make sense of these experiences in the context of their personal and social worlds [ 73 ]. IPA research encompasses phenomenology, hermeneutics, and idiography and emphasises the personal significance of self-reflection among individuals with a shared experience in a specific context [ 74 ]. Additionally, IPA is particularly suitable for research focusing on identity and self-awareness [ 75 ]. The features and focus of IPA are consistent with the purpose of this study. Therefore, IPA was considered a suitable approach to explore the SMSAs’ perceptions of their sexual minority identity within the sport context in China.
Researcher characteristics and reflexivity
During the data collection phase of this study, the first researcher was a Ph.D. candidate and had obtained her Ph.D. by the time of this manuscript’s submission. Her doctoral committee continuously supervised the research. The first researcher’s doctoral committee members are proficient in qualitative research. The first researcher and the second coder have received systematic qualitative training, are skilled in qualitative analysis software (NVivo), and have published empirical studies using the IPA approach. Although none of the research team members were SMSAs, the first researcher and the second coder maintained long-term contact with SMSAs through their involvement in sport teams. The first researcher was a former student-athlete and is currently working as a coach. Given her background, she has had extensive time to interact with and understand SMSAs within student teams.
Participants and procedures
Purposive and snowball sampling methods were employed to recruit a homogeneous sample for this study, as recommended by Smith and Nizza [ 73 ]. Following approval from Universiti Putra Malaysia’s Human Research Review Committee, the researcher initially reached out to SMSAs within her network, subsequently expanding outreach through social media to reach a broader pool of potential participants. The participants were selected based on specific inclusion criteria (Table 1 ), ensuring relevance to the study’s focus. Of the 22 individuals contacted, 16 agreed to participate, while six individuals declined participation due to concerns regarding potential exposure. The sample included a diverse representation of sexual minority subgroups: one asexual man, four bisexual women, three gay men, and eight lesbians. Given the relatively low prevalence of asexual individuals [ 76 , 77 ], we only had one participant from this subgroup. Strict confidentiality measures were enforced, with participants assigned pseudonyms and their college affiliations omitted for anonymity. The demographic details of the participants are outlined in Table 2 .
In phenomenological research, the focus is on rich individual experiences rather than data saturation [ 78 ]. Similarly, IPA research aims to explore participants’ personal and social worlds through detailed, in-depth analysis [ 79 ]. Smith and Nizza [ 73 ] also highlighted that in IPA research, sample size is less crucial because of the emphasis on detailed analysis in small, homogeneous samples. Therefore, the richness of data and the depth of insight into each participant’s experience are more important than the number of participants or reaching data saturation. This study utilised IPA’s in-depth analytical approach with sixteen participants to provide detailed data. This methodological approach allows for a comprehensive exploration of individual experiences, aligning with the study’s objectives.
Data collection
Data for this study were collected through semi-structured interviews (Appendix A), allowing participants to choose the mode, time, and location, including face-to-face or online sessions on Chinese social networks. Each interview’s length is detailed in Table 2 , with an average duration of 63 min. Before each interview, participants signed informed consent forms following a detailed briefing on the study’s purpose and procedures. Given the sensitive nature of the research, the interviews were conducted solely between the researcher and the participant to ensure a safe and comfortable environment, fostering open and honest communication.
The methods of data collection exhibited some qualitative differences. In face-to-face interviews, participants were often cautious and hesitant to share personal experiences. Conversely, online interviews proved more effective, as participants felt more relaxed, leading to quicker rapport and greater openness. This difference likely stems from the reduced perceived risk of exposure in an online setting. Due to the clear objectives of the study and the structured interview guide, there were no differences between the data from current SMSAs and former SMSAs.
Notably, one participant provided data through written essays instead of a semi-structured interview due to concerns about exposure and discomfort. After discussing the matter, the participant agreed to respond to interview questions in written form. The first researcher sent the interview questions to the participant, who then provided written responses. Follow-up questions were asked based on these initial responses, resulting in four sets of essay responses. This approach, which aligns with the conventions of phenomenological research [ 80 ], allowed the participant to express their experiences comfortably. The essay data were analysed alongside the semi-structured interview data, with common themes identified across all responses.
Documents and field notes supplemented the data collection. Documents included photographs, videos, and diaries. With participant consent, these documents were analysed for relevance to the research purpose. Field notes captured contextual information during both face-to-face and online interviews, including keywords and participants’ pauses and intonations, with immediate elaboration post-interview to avoid biases [ 81 , 82 ]. These detailed notes contextualised data analysis [ 74 ] and contributed to the research’s credibility.
Data analysis
The data analysis in this study followed a seven-step process aligned with IPA research guidelines and contemporary IPA terminology. The data analysis procedure is depicted in Fig. 1 . The IPA analysis is iterative and inductive [ 83 ], involving the organisation of data into a structured format for easy tracking through various stages – from initial exploratory notes on transcripts to the development of empirical statements, theme clustering, and final group theme structure. The theoretical framework was incorporated at the final stage of empirical theme development.
To enhance the study’s validity, the first author invited another Ph.D. candidate to participate in the data analysis process. After the interview recordings were translated into transcripts using audio software, the first researcher listened to the recordings repeatedly to correct the transcripts. The second coder reviewed the recordings to ensure the transcriptions were accurate and verbatim. The first author employed NVivo software (released in March 2020) for coding, and the second coder utilised manual coding. All data were analysed in Chinese to maintain linguistic integrity and then translated into English for theme presentation.

Data Analysis Procedure. Adapted from Smith et al. ( 74 )
The procedures of this study adhered to the COREQ Checklist [ 84 ] (Appendix B) and the IPA Quality Evaluation Guide [ 85 ] to ensure rigour. The research met the good quality requirements for IPA studies as outlined by Smith [ 85 ] (Table 3 ). Throughout the research, emphasis was placed on internal validity, external validity, and reliability to maintain the study’s rigour and quality. The methods employed to address these aspects are summarised in Table 4 .
This study explored SMSAs’ perceptions of sexual minority identity within intercollegiate sport in China. From the perspective of SCT, the results uncovered four key themes from SMSA’s team-based interactive experiences. The research themes, along with their corresponding sub-themes and occurrences, are presented in Table 5 .
Hidden truths
The hidden truths refer to facts, scenarios, or knowledge that are not commonly known or readily available. In this study, the existence of SMSAs in intercollegiate sport was undeniable, yet it remained concealed due to the prevailing lack of transparency.
SMSAs are common in sport
This research uncovered the extensive existence of SMSAs in Chinese sport. Almost all participants acknowledged the ubiquity of sexual minorities in sport, with 12 out of the 16 participants specifically highlighting the presence of SMSAs in collegiate sport:
I think everyone is generally aware of sexual minorities; all people are aware of them to a greater or lesser extent. It is generally agreed that the existence of sexual minorities is a common phenomenon in modern society, and even more so in Sport, as anyone involved in sport knows that (Adam).
Participants frequently described the presence of SMSAs in intercollegiate sport, using terms like “widespread”, “common”, “normal”, and “quite many”. Several participants also provided specific details about the number of SMSAs in their respective teams. Jackie remarked, “At that time, half of my teammates were lesbians” (Jackie). Similarly, Zoe noted the significant presence of SMSAs in her team, “I think it (the number of SMSAs) was almost half of the team at that time. But I don’t know about the senior players; almost half of our junior players were SMSAs” (Zoe).
Silent identity
Participants noted the prevalence of SMSAs in sport but also emphasised the difficulty of openly discussing sexual minority identity in this context. They described the sport environment as reserved and lacking open conversations about SMSAs and their experiences.
The reticent nature of sport teams regarding sexual minority identity was evident in their attitudes. William observed, “I feel like most of my teammates just don’t take a stand. They don’t want to make a statement about SMSAs. Nor did they say they supported it or didn’t support it” (William). Similarly, Mia considered sexual minority identity as a personal issue, inappropriate for open discussion.
No one wants to ask or discuss this openly…we live in a very conservative environment all the time, and none of this content is something that teammates should be concerned about, and people would feel offended if you don’t handle it well (Mia).
Some SMSAs viewed avoiding discussions on sexual minorities in sport as respectful to teammates, aiming for a comfortable, stress-free environment. Joy said, “We came here to play, right? I don’t think any of the other players want to feel phased by who you are” (Joy). Mia echoed this sentiment:
…in team training, the game is the game, and I rarely bring other emotions into it…. In the company of most of our teammates, we don’t interact with each other in that way. It’s probably a default rule that respect is distance, I guess (Mia).
Charlotte, involved in volleyball and basketball, recounted a teammate’s public derogation due to her sexual minority identity, an incident not openly addressed by the team. She perceived sexual identity as a “taboo” topic. The narratives revealed a cautious approach among SMSAs towards expressing their sexual minority identity in sport. They felt compelled to carefully manage their sexual orientation, minimising its disclosure. This hesitancy likely stemmed from the existing reticence and limited acceptance of SMSAs in sport, fostering a sense of invisibility and concern over potential negative consequences.
Prioritisation of athlete identity
The theme of prioritisation of athlete identity suggests that for SMSAs, their identity as an athlete may play a more prominent or influential role in shaping their self-conception compared to their sexual minority identity.
Be an athlete
Several participants believed their primary role as student-athletes was to engage in sport, and they valued this aspect of their identity significantly. Joy expressed this sentiment, “I love volleyball very much … I don’t care much about relationships; I just love volleyball, and I think we are all here to do this, and nothing else matters. You don’t need to stress about it (sexual minority identity)” (Joy).
Emma echoed a similar perspective, noting, “I think my teammates are very professional; our program requires a high technical standard, and we spend most of our time training; other than that, things don’t seem that important” (Emma). When queried about the importance of sexual minority identity, she responded, “Yes, at least not concerning sport performance, or maybe it will have a bad effect” (Emma). Additionally, some participants felt that in the context of sport, sexual minority identity might be sidelined. Adam commented:
“We don’t share it (sexual minority identity) unless someone asks. We’re a team first, and then we’re individuals, and for me, I’m important personally, but in the team, we all probably need to sacrifice some of ourselves to make the team more united and stronger” (Adam).
Participants’ views as both student-athletes and sexual minorities highlighted contrasts in the intercollegiate sport environment. Their student-athlete identity was key in shaping self-perception and fostering a sense of community, while their sexual minority identity was often marginalised in aspects of interpersonal relations, team support, and self-identity development.
Sport performance first norms
In team sport, leaders are crucial in creating inclusive spaces for SMSAs and setting behavioural and attitudinal standards, including those towards SMSAs. In this study, some participants believed that coaches’ criteria for acceptance of sexual minority individuals or intra-team romantic relationships were based on athletic performance.
Some coaches firmly believe that team relationships negatively impact team performance and, therefore, strictly prohibit romantic relationships between teammates. Joy recalled,
She couldn’t accept that… she thinks being an athlete like that is ridiculous. It would make a mess; her team would be in a mess. She said you two are dating and that playing will affect your emotions, which means she meant to say there is no way I can treat another girl as a normal teammate… (Joy).
In contrast, some coaches adopt a more tolerant attitude. Jackie’s coach believes that if the team’s overall performance is not affected, issues such as sexual orientation or team relationships can be ignored. Jackie stated, “My coach is male and old, but he should know what’s going on, especially since our captain has dated several teammates and the coach pretends not to know. He would only care if we were winning games” (Jackie).
Whether it instructs prohibition or an indifferent attitude, both narratives reflect that the team’s norms for inclusivity are based on sport performance. These norms also influence how SMSAs assess their own sexual minority identity within the team, as Adam said:
As of now, I have someone in the team that I have a crush on and haven’t dated. Maybe if he and I argued over training or a game, it would affect the performance of the team and the relationship between teammates…. I don’t think I could let that happen (Adam).
The participants’ narratives emphasise how the “Sports Performance First” norms influence the attitudes and behaviours of coaches and SMSAs within the team. These norms not only shape the team culture but also profoundly affect how SMSAs navigate their identities and relationships in the team environment.
However, the excessive focus on sport performance highlights the athletic identity of student-athletes while neglecting their other identities, especially those of sexual minorities. This singular focus leads to the neglect of the personal needs and diverse identities of athletes. Although these measures may seem to ensure the overall performance of the team, they overlook the psychological health and holistic development needs of the individuals.
Self-stereotyping
Self-stereotyping denotes the tendency of SMSAs to describe themselves using stereotypical attributes in the sport context. These descriptions frequently align with stereotypical perceptions prevalent in the external environment. SMSAs tend to be perceived as having specific physical traits or behavioural tendencies.
Specific physical traits
Sophia provided an illustrative example of self-stereotyping through her personal experience. She commented:
In the beginning, I would think that if you are an SMSA, you must fit some characteristics. For example, at that time, I saw some lesbians in my team who had short hair or wore baggy t-shirts; I was a bit frustrated by my long hair and feminine appearance…and I felt that I might not quite fit those criteria. So, then I cut my hair and even wore a wrapping bra to the training ground (Sophia). Sophia’s narrative underscores how the pressure to conform to certain physical traits led her to change her appearance to fit the stereotypical image of an SMSA within the sport context.
Behavioural tendencies
In addition to physical traits, SMSAs also feel compelled to conform to certain behavioural tendencies that are stereotypically associated with SMSAs. Zoe explained, “Because of who I am (T), I felt I should have to perform stronger, so I put up with much training…. I felt I should be there to protect the other players; if I were vulnerable, I would look down on myself” (Zoe). This indicates a sense of obligation among some female SMSAs to embody strength, aligning with the stereotypical image of female SMSAs in sport. Conversely, male SMSAs in men’s teams often faced stereotypes of being fragile, weak, or exhibiting feminine traits. Royal noted that behaviours of some male SMSAs, like engaging in non-sport-related banter, led to gossip and negative perceptions within men’s sport. To avoid these stereotypes, Royal aimed to mimic the mannerisms of heterosexual athletes, as he explained:
I try to avoid being close to the team’s prominent male SMSAs and try to stay out of related conversations; I don’t want to be a standard gay; I want to have the same college life as the rest of the team (heterosexuality) (Royal).
Stereotypes in sport often forced SMSAs into roles incongruent with their authentic identities, significantly impacting their self-expression and identity. The pressure to conform to societal norms in sport settings created internal conflicts for SMSAs, challenging their ability to maintain their true sense of self.
This theme addresses situations where student-athletes engage in intra-team intimacy or mimic being SMSAs in sport. This attempt has two key elements: prolonged contact leading to intimacy and influence from sexual minority teammates.
Prolonged contact leading to intimacy
Participants noted that extensive training and competition schedules in sport fostered close bonds among team members. Lucas shared, “When we were preparing for the tournament, we trained together every morning and evening…the game spanned for almost a month, and after that, we felt as close as family to our teammates” (Lucas). Similarly, Ruby pointed out, “Back then, we were training every afternoon until late at night; it was quite hard (the training was very strenuous) … it lasted for six months” (Ruby). These prolonged interactions sometimes led to the development of more profound attractions among student-athletes.
“I think we had many moments of trust and intimacy together on the field that built up some heartfelt feelings. These feelings made me feel emotions beyond that of a teammate…. Then I realised that gender might not be so important because it’s hard to build that kind of relationship in a typical romance” (Savannah).
Influence from sexual minority teammates
Participants also described how interactions with sexual minority teammates led them to explore their own sexual identities, as illustrated by Ava’s recounting of her initial same-gender relationship experience:
That time we went out to a tournament, and I found that four of my teammates, three of them were lesbians…we didn’t have games at night, so they had been talking to their girlfriends every night on the phone, and I just felt as if that was not too bad. Probably influenced by them, I got a girlfriend at that tournament as well…. Even though we broke up when we returned, I could accept girls (Ava).
Mia described a similar experience:
There were some lesbians in my team, and then it just seemed natural that I got close to one of them…. Well, I was thinking about whether that relationship would affect the team. But then I found out that there were other couples on the team. So, I feel like I wasn’t doing anything wrong (Mia).
The phenomenon highlights the significant role of peer influence in team settings. When individuals are around many teammates in same-gender relationships, it fosters an environment that normalises such relationships. Notably, this influence is not coercive but stems from observing and interacting with teammates who are comfortable with their sexual orientations. This environment helps individuals feel accepted and more confident in exploring their identities and relationships.
This study explored the perceptions of SMSAs regarding their sexual identity within intercollegiate sport in China. Its importance lies in its contribution to understanding the complex realities of SMSAs in China, an area that has lacked depth in the literature. By reaffirming the necessity of examining these athletes’ experiences, this study reveals the intricate conflict between adhering to team norms and expressing personal characteristics within the context of the Chinese social and cultural background.
The results show that SMSAs are a recognised reality in Chinese intercollegiate sport, consistent with findings from Western countries. While precise figures of sexual minorities in sport may vary across countries, it is acknowledged that they are present at all competitive levels, from school and college sport to the professional sphere [ 22 , 86 , 87 , 88 , 89 , 90 , 91 ]. Although no national census on sexual minorities in China or in sports environments exists, related research indicates that many college and university students self-identify as sexual minorities. For instance, an online survey conducted across 26 colleges and universities in 10 Chinese provinces found that over 8% of students identify as sexual minorities [ 36 ]. Additionally, another national survey revealed that nearly a quarter of college students identify as non-heterosexual [ 92 ]. Recognising and addressing the unique challenges faced by sexual minority youth, who make up a notable percentage of the student population, is essential for sport and educational institutions.
Despite the apparent prevalence of SMSAs, the study confirms that their identities often remain hidden in the context of Chinese intercollegiate sport. This can be attributed to two main reasons: First is the concern about discrimination if exposed. Chinese sexual minorities frequently report experiencing abuse or discrimination in families, schools, and workplaces [ 93 ]. Additionally, conversion therapies and discriminatory counselling practices persist in mental health services [ 94 ], creating an environment where discrimination is a significant concern, thereby reducing the likelihood of SMSAs coming out in the sports environment. The second reason is the constraint of traditional Chinese culture. The dominant Confucian culture in China emphasises harmony, internalised homonegativity, and conformity [ 95 , 96 ], often at the expense of individual expression and identity development. This cultural backdrop influences how sexual minorities perceive their own identities [ 97 ] and creates an ideological constraint that leads to social rejection and resistance towards sexual minorities [ 98 ], thereby reducing the visibility of sexual orientation-related topics in the Chinese sport context.
Moreover, SMSAs in China often prioritise their athlete identity over their sexual minority identity, influenced by the attitudes of team leaders. This tendency is reinforced by coaches who primarily focus on the biological sex of athletes and lack training or understanding related to sexual minority issues [ 99 ]. Consequently, the Chinese coaches’ lack of knowledge about sex and sexual orientation exacerbates the silence surrounding sexual minority identities in the Chinese collegiate sport environment and intensifies the identity conflict for SMSAs. Emphasising athletic performance is central in sport but should not overshadow the holistic development of student-athletes. McCavanagh and Cadaret [ 100 ] noted that student-athletes might face challenges in reconciling various aspects of their identity in a heteronormative sport context. The suppression of sexual minority identity can lead to isolation from potential support systems that nurture positive sexual and gender identities. Prioritising athletic success over broader student development in sport departments limits growth opportunities for all students, including SMSAs. Chavez et al. [ 101 ] emphasised that student development requires recognising and valuing diversity, suggesting that a singular focus on athletic prowess can diminish the benefits of diversity among student-athletes. Embracing diversity is not only a personal journey but also one that can enhance the collective experience within sport settings.
In addition, self-stereotyping within SCT involves aligning one’s self-concept with the characteristics of valued social categories [ 102 ]. Latrofa [ 103 ] suggests that members of low-status groups, like SMSAs in sport, may self-stereotype to align more closely with their group, reflecting recognition of lower status and self-perception through peers. This study revealed SMSAs shape their self-identity based on the attitudes prevalent in their sport environment, with influences from peers and coaches being internalised as personal attitudes [ 104 ]. Such self-stereotyping supports maintaining a favourable social identity and adhering to group norms but can reinforce negative stereotypes and prejudices within sport.
Internalising stereotypes may lead SMSAs to develop prejudices against themselves and others, perpetuating discrimination. It can also hinder individual development, impacting self-esteem and confidence. For example, aligning with negative stereotypes could cause SMSAs to doubt their worth and capabilities, affecting emotional well-being and satisfaction. Liu and Song’s [ 105 ] survey of Chinese college students illustrated the direct impact of gender self-stereotypes on life satisfaction, highlighting the significant effects of self-stereotyping on individual well-being.
Furthermore, in the context of traditional and reserved Chinese culture, intercollegiate sport offers a relatively free and open space for sexual minority women. The results of this study suggest that the visibility of sexual minority women in teams and the long time spent together allow these athletes to explore and establish intimate relationships. These results are similar to findings in Spanish studies [ 103 ], which highlighted the protective and liberating role of sports teams in the sexual exploration of female sexual minority athletes. Research by Organista and Kossakowski on Polish female footballers [ 106 ] and Xiong and Guo [ 96 ] on Chinese women’s basketball teams also revealed a climate of non-heteronormativity in women’s sport. These climates provide a sanctuary from heterosexual pressures, allowing sexual minority athletes to engage in sport free from traditional constraints. Such environments help female sexual minority athletes navigate and subvert heteronormative norms by cultivating supportive subcultural networks within their teams.
This study addresses the lack of in-depth research on the experiences of SMSAs in Chinese intercollegiate sport. It fills the gap by exploring the complex realities of SMSAs, focusing on their identity conflicts and the influence of the Chinese social and cultural background. Specifically, this study provides valuable insights that align with SCT [ 71 ]. This study addresses a notable gap in the existing literature regarding sexual minority sport participation, as rarely have these perceptions been explored. Drawing from the lens of SCT, the results of this study revealed several valuable insights into how their sexual minority identity impacts their participation in sport. These findings not only enhance our understanding of how SCT applies to the sport experiences of sexual minority individuals but also contribute to the advancement of SCT in research on sexual minority sport participation. The themes uncovered in this study closely align with central SCT concepts such as identity salience, self-stereotyping, and depersonalisation, illuminating the ways SMSAs comprehend and express their sexual minority identity within the intercollegiate sport context. SCT, with its focus on both intragroup and intergroup relations within the multifaceted construct of the self, offers valuable insights into the complexities of SMSAs’ self-perceptions and the intricacies involved in developing and manifesting their identities in the realm of sport.
Based on the results, more effort needs to be put into understanding sexual minority identities in intercollegiate sport. By examining the perspectives and experiences of SMSAs, we can gain insights into the interactions and influences of sexual minority individuals in the sport context. The interplay between an individual’s self-perception and situational dynamics results in a self-identity that mirrors the collective. In addition, the prevalent pressures and normative prejudices inherent in the sport system significantly influence their self-identity. Therefore, valuing SMSAs’ understanding of their self-identity shows respect for each person’s differences and rights. We hope the findings will be incorporated into existing sport policies to promote inclusivity and ensure safe participation for sexual minority students. To encourage and support the full development of SMSAs, college athletics and related institutions should prioritise understanding and respecting their perceptions of their sexual minority identity. By doing so, institutions can create a more inclusive and supportive environment that acknowledges and addresses the unique challenges faced by SMSAs.
Nevertheless, caution should be exercised when generalizing the findings, especially for subgroups with low representation, such as asexual individuals. While the study provides valuable insights into SMSAs’ perceptions of their sexual minority identity within the Chinese sport context, the limited number of asexual participants means their unique perspectives may not be fully captured. Therefore, these findings may not fully represent all sexual minority subgroups.
Future research could focus on exploring the perceptions and experiences among various sexual minority subgroups within sport participation in China. Additionally, considering the cultural diversity across China’s vast geographic regions, it would be valuable to examine how SMSAs perceive their minority identity in different cultural contexts. Given the scarcity of related studies in China, it is also important to survey other stakeholders in the sport environment, such as coaches and heterosexual student-athletes, to gain a broader understanding of perceptions of sexual minority identities. These insights can inform the development of targeted interventions aimed at ensuring the safe and inclusive participation of SMSAs in intercollegiate sport.
Data availability
The datasets generated and/or analysed during the current study are not publicly available due to ethical considerations but are available from the corresponding author on reasonable request.
Gallup. A STUDY OF NCAA, STUDENT-ATHLETES. : Undergraduate Experiences and Post-College Outcomes. 2020.
Graupensperger S, Panza MJ, Budziszewski R, Evans MB. Growing into us: trajectories of Social Identification with College Sport teams Predict Subjective Well-Being. Appl Psychol Health Well Being. 2020;12(3):787–807.
Article PubMed PubMed Central Google Scholar
Gohn LA, Albin GR. Understanding college student subpopulations: a guide for student affairs professionals. NASPA Student Affairs Administrators In HIgher Education; 2006.
American Psychological Association. APA Task Force on Psychological Practice with Sexual Minority Persons. Guidelines for Psychological Practice with Sexual Minority Persons. American Psychologist. 2021.
Team DC. 2023 Scholarship Recipients-Team DC awarded the following seven student-athletes with scholarships in 2023: Team DC; 2023 [cited 2023 July, 22]. https://teamdc.org/scholarships/
Porter M. Check out these LGBTQ student-athlete scholarship opportunities: Various organizations give out scholarships to LGBTQ students and student-athletes 2021 [updated Mar 31, 2021. https://www.outsports.com/lgbtq-high-school-athlete-resources/2021/3/31/22310564/lgbtq-student-athlete-scholarship-list
lacrosse U. USA LACROSSE LGBTQ + INCLUSION SCHOLARSHIP 2023 [ https://www.usalacrosse.com/lgbtq-plus-scholarship
National Collegiate Athletic Association. Ethnic Minority and Women’s Enhancement Graduate Scholarship 2023 [ https://www.ncaa.org/sports/2013/11/21/ethnic-minority-and-women-s-enhancement-graduate-scholarship.aspx
Pigozzi F, Bigard X, Steinacker J, Wolfarth B, Badtieva V, Schneider C, et al. Joint position statement of the International Federation of Sports Medicine (FIMS) and European Federation of Sports Medicine Associations (EFSMA) on the IOC framework on fairness, inclusion and non-discrimination based on gender identity and sex variations. BMJ Open Sport Exerc Med. 2022;8(1):e001273.
International Olympic Committee. IOC Framework on fairness, inclusion and non-discrimination on the basis of gender identity and sex variations. 2021.
Denison E, Bevan N, Jeanes R. Reviewing evidence of LGBTQ + discrimination and exclusion in sport. Sport Manage Rev. 2020;24(3):389–409.
Article Google Scholar
Symons CM, O’Sullivan GA, Polman R. The impacts of discriminatory experiences on lesbian, gay and bisexual people in sport. Annals Leisure Res. 2017;20(4):467–89.
Anderson AR, Smith CM, Stokowski SE. The impact of Religion and Ally Identity on individual sexual and gender prejudice at an NCAA Division II institution. J Issues Intercoll Athletics. 2019(12):154–77.
Toomey RB, McGeorge CR, Carlson TS. Athletes’ perceptions of the climate for sexual and gender minority athletes and their intervention in bias. J Study Sports Athletes Educ. 2018;12(2):133–54.
Roper EA, Halloran E. Attitudes toward Gay men and lesbians among Heterosexual male and female student-athletes. Sex Roles. 2007;57(11):919–28.
O’Brien KS, Shovelton H, Latner JD. Homophobia in physical education and sport: the role of physical/sporting identity and attributes, authoritarian aggression, and social dominance orientation. Int J Psychol. 2013;48(5):891–9.
Article PubMed Google Scholar
Gill DL, Morrow RG, Collins KE, Lucey AB, Schultz AM. Perceived climate in physical activity settings. J Homosex. 2010;57(7):895–913.
Petty L, Trussell DE. Experiences of identity development and sexual stigma for lesbian, gay, and bisexual young people in sport: ‘Just survive until you can be who you are’. Qualitative Res Sport Exerc Health. 2018;10(2):176–89.
Anderson AR, Stokowski S, Smith CML, Turk MR. You have to validate it: experiences of female sexual minority student-athletes. J Homosex. 2021:1–22.
Storr R, Nicholas L, Robinson K, Davies C. Game to play?’: barriers and facilitators to sexuality and gender diverse young people’s participation in sport and physical activity. Sport Educ Soc. 2022;27(5):604–17.
Denison E, Jeanes R, Faulkner N, O’Brien KS. The relationship between ‘Coming out’ as Lesbian, Gay, or bisexual and experiences of homophobic Behaviour in Youth Team sports. Sexuality Res Social Policy. 2021;18(3):765–73.
Pariera K, Brody E, Scott DT. Now that they’re out: experiences of College Athletics Teams with openly LGBTQ players. J Homosex. 2021;68(5):733–51.
Kulick A, Wernick LJ, Espinoza MAV, Newman TJ, Dessel AB. Three strikes and you’re out: culture, facilities, and participation among LGBTQ youth in sports. Sport Educ Soc. 2019;24(9):939–53.
Jeffreys E. Public policy and LGBT people and activism in mainland China. Routledge handbook of the Chinese communist party. Routledge; 2017. pp. 283–96.
Chinese Classification of Mental Disorders. Classification and diagnostic criteria of Mental disorders in China. Shandong: Shandong Publishing House of Science and Technology; 2001.
Google Scholar
Wei W. The normalization project: the Progress and limitations of promoting LGBTQ Research and Teaching in Mainland China. J Homosex. 2020;67(3):335–45.
Shaw G, Zhang X. Cyberspace and gay rights in a digital China: Queer documentary filmmaking under state censorship. China Inform. 2018;32(2):270–92.
Zhao P, Cao B, Bien-Gund CH, Tang W, Ong JJ, Ding Y, et al. Identifying MSM-competent physicians in China: a national online cross-sectional survey among physicians who see male HIV/STI patients. BMC Health Serv Res. 2018;18(1):1–9.
Article CAS Google Scholar
Xu G, Wang X, Budge SL, Sun S. We don’t have a template to follow: sexual identity development and its facilitative factors among sexual minority men in the context of China. J Couns Psychol. 2022.
Suen YT, Chan RCH, Badgett MVL. The experiences of sexual and gender minorities in employment: evidence from a large-scale survey of Lesbian, Gay, Bisexual, Transgender and Intersex People in China. China Q. 2021;245:142–64.
Liu X, Peng C, Huang Y, Yang M, Wen L, Qiu X, et al. Association between sexual orientation and school bullying behaviors among senior high school students. Chin J Public Health. 2020;36(6):880–3.
Wang Y, Yu H, Yang Y, Li R, Wilson A, Wang S, et al. The victim-bully cycle of sexual minority school adolescents in China: prevalence and the association of mood problems and coping strategies. Epidemiol Psychiatr Sci. 2020;29:e179.
Li X, Zheng H, Tucker W, Xu W, Wen X, Lin Y et al. Research on relationships between sexual identity, adverse childhood experiences and Non-suicidal Self-Injury among Rural High School Students in Less developed areas of China. Int J Environ Res Public Health. 2019;16(17).
Zhao M, Xiao D, Wang W, Wu R, Zhang W, Guo L, et al. Association among Maltreatment, Bullying and Mental Health, Risk Behavior and sexual attraction in Chinese students. Acad Pediatr. 2021;21(5):849–57.
Zhao J, Teng S, Zhang X, Yang X, Chen J. Change in sexual orientation identity and its influencing factors among college students. Chin J Public Health. 2018;34(4):563–6.
Zhang Y, Fu F. Investigation on Mental Health Status of Sexual Minority College Students based on National Samples of China. Chin J Clin Psychol. 2019;27(5):997–1002.
Wen G, Zheng L. The influence of internalized Homophobia on Health-related quality of life and life satisfaction among Gay and Bisexual men in China. Am J Mens Health. 2019;13(4):1557988319864775.
Xu W, Zheng L, Xu Y, Zheng Y. Internalized homophobia, mental health, sexual behaviors, and outness of gay/bisexual men from Southwest China. Int J Equity Health. 2017;16(1):36.
Li P, Huang Y, Guo L, Wang W, Xi C, Lei Y, et al. Sexual attraction and the nonmedical use of opioids and sedative drugs among Chinese adolescents. Drug Alcohol Depend. 2018;183:169–75.
Shi J, Dewaele A, Lai W, Lin Z, Chen X, Li Q, et al. Gender differences in the association of sexual orientation with depressive symptoms: a national cross-sectional study among Chinese college students. J Affect Disord. 2022;302:1–6.
Guo M, Wang Y, Duan Z, Wei L, Li S, Yan H. Depressive symptoms, perceived social support and their correlation among adolescent lesbians. Chin J Public Health. 2021;37(12):1805–8.
Huang Y, Li P, Guo L, Gao X, Xu Y, Huang G, et al. Sexual minority status and suicidal behaviour among Chinese adolescents: a nationally representative cross-sectional study. BMJ Open. 2018;8(8):e020969.
Denison E, Bevan N, Jeanes R. Reviewing evidence of LGBTQ + discrimination and exclusion in sport. Sport Manage Rev. 2021;24(3):389–409.
Abreu RL, Audette L, Mitchell YL, Simpson I, Ward J, Ackerman L, et al. LGBTQ student experiences in schools from 2009–2019: a systematic review of study characteristics and recommendations for prevention and intervention in school psychology journals. Psychol Sch. 2021;59(1):115–51.
Mann M, Krane V. Inclusion or illusion? Lesbians’ experiences in sport. Sex, gender, and sexuality in Sport. Routledge; 2019. pp. 69–86.
Tang R, Feng Y. Bibliometric analysis of studies on homosexuality in the Chinese psychology. J Jiangxi Normal University(Philosophy Social Sci Edition). 2018;56(6):108–14.
MORRISON TG, McLEOD LD, MORRISON MA, ANDERSON D, O’CONNOR WE. Gender stereotyping, Homonegativity, and misconceptions about sexually coercive behavior among adolescents. Youth Soc. 1997;28(3):351–82.
Weinberg GH. Society and the healthy homosexual. New York: St. Martin; 1972.
HEREK GM. On heterosexual masculinity:some Psychical consequences of the Social Construction of Gender and sexuality. Am Behav Sci. 1986;29(5):563–77.
Barber H, Krane V. Creating a positive climate for Lesbian, Gay, Bisexual, and Transgender youths. J Phys Educ Recreation Dance. 2007;78(7):6–52.
Anderson E. Openly Gay athletes:contesting hegemonic masculinity in a homophobic environment. Gend Soc. 2002;16(6):860–77.
Lenskyj H. Power and play: gender and sexuality issues in Sport and Physical Activity. Int Rev Sociol Sport. 1990;25(3):235–45.
Smith M, Cuthbertson S, Gale N. Out for sports -tackling Homophobia and Transphobia in Sport Content. Edinburgh, Edinburgh: Equality Network; 2012.
Anderson E, Bullingham R. Openly lesbian team sport athletes in an era of decreasing homohysteria. Int Rev Sociol Sport. 2015;50(6):647–60.
Saraç L, McCullick B. The life of a gay student in a university physical education and sports department: a case study in Turkey. Sport Educ Soc. 2017;22(3):338–54.
Kavasoğlu İ, Anderson E. Gay men and masculinity in a homohysteric Turkish body building culture. J Gend Stud. 2021;31(7):812–24.
Morales L, White AJ. Perception versus reality: Gay male American athletes and coming-out stories from outsports. Com. LGBT athletes in the sports media. 2019:27–50.
Scandurra C, Braucci O, Bochicchio V, Valerio P, Amodeo AL. Soccer is a matter of real men? Sexist and homophobic attitudes in three Italian soccer teams differentiated by sexual orientation and gender identity. Int J Sport Exerc Psychol. 2019;17(3):285–301.
Rollè L, Cazzini E, Santoniccolo F, Trombetta T. Homonegativity and sport: a systematic review of the literature. J Gay Lesbian Social Serv. 2022;34(1):86–111.
Denison E, Kitchen A. Out on the fields: The first international study on homophobia in sport. Nielsen Sport, Bingham Cup 2014, Sydney Convicts, Sport Australia; 2015.
Menzel T, Braumüller B, Hartmann-Tews I. The relevance of sexual orientation and gender identity in sport in Europe: findings from the outsport survey. Cologne: German Sport University Colognen, Istitute of Sociology and Gender Studies; 2019.
Tseng Y-H, Sum RK-W. Attitudes of Taiwan and Hong Kong collegiate student athletes towards homosexuality in sport participation. Asia Pac J Sport Social Sci. 2017;6(3):267–80.
Velez L, Piedra J. Does sexuality play in the stadium? Climate of tolerance/rejection towards sexual diversity among soccer players in Spain. Soccer Soc. 2018;21(1):29–38.
Halbrook MK, Watson JC, Voelker DK. High School coaches’ experiences with openly lesbian, Gay, and bisexual athletes. J Homosex. 2019;66(6):838–56.
Hunter JA, Kypri K, Stokell NM, Boyes M, O’Brien KS, McMenamin KE. Social identity, self-evaluation and in-group bias: the relative importance of particular domains of self-esteem to the in-group. Br J Soc Psychol. 2004;43(1):59–81.
Tajfel H, Turner JC. The social identity theory of intergroup behavior. Political psychology: Psychology; 2004. pp. 276–93.
Trepte S, Loy LS. Social Identity Theory and Self-Categorization Theory. In: Rössler P, Hoffner CA, Zoonen L, editors. The International Encyclopedia of Media Effects2017. pp. 1–13.
Rankin SS, Merson D. 2012 LGBTQ National College Athlete Report. Charlotte, NC: Campus Pride; 2012.
Fynes JM, Fisher LA. Is authenticity and Integrity possible for sexual minority athletes? Lesbian Student-Athlete experiences of U.S. NCAA Division I Sport. Women Sport Phys Activity J. 2016;24(1):60–9.
Ellemers N, Haslam SA. Social identity theory. Handb Theor Social Psychol. 2012;2:379–98.
Turner JC, Hogg MA, Oakes PJ, Reicher SD, Wetherell MS. Rediscovering the social group: A self-categorization theory. Cambridge, MA, US: Basil Blackwell; 1987. x, 239-x, p.
Creswell JW, Poth CN. Qualitative inquiry and research design: choosing among five approaches. Sage; 2016.
Smith JA, Nizza IE. Essentials of interpretative phenomenological analysis. Washington, DC, US: American Psychological Association; 2022. viii, 94-viii, p.
Smith JA, Flowers P, Larkin M. Interpretative Phenomenological Analysis: Theory, Method and Research. London: SAGE Publications Ltd; 2021. http://digital.casalini.it/9781529780796
Eatough V, Smith JA. Interpretative phenomenological analysis. The Sage handbook of qualitative research in psychology. 2017:193–209.
Rothblum ED, Krueger EA, Kittle KR, Meyer IH. Asexual and Non-asexual respondents from a U.S. Population-based study of sexual minorities. Arch Sex Behav. 2020;49(2):757–67.
Aicken CR, Mercer CH, Cassell JA. Who reports absence of sexual attraction in Britain? Evidence from national probability surveys. Asexuality and Sexual Normativity: Routledge; 2015. pp. 10–24.
Van Manen M, Higgins I, van der Riet P. A conversation with Max Van Manen on phenomenology in its original sense. Nurs Health Sci. 2016;18(1):4–7.
Smith JA, Flower P, Larkin M. Interpretative phenomenological analysis: theory, Method and Research. Qualitative Res Psychol. 2009;6(4):346–7.
Groenewald T. A Phenomenological Research Design Illustrated. Int J Qualitative Methods. 2004;3(1):42–55.
Asplund M, Welle CG. Advancing Science: how Bias holds us back. Neuron. 2018;99(4):635–9.
Article PubMed CAS Google Scholar
Lofland J, Lofland LH. Data logging in observation: Fieldnotes. London: Sage; 1999.
Smith JA. Hermeneutics, human sciences and health: linking theory and practice. Int J Qualitative Stud Health Well-being. 2007;2(1):3–11.
Tong A, Sainsbury P, Craig J. Consolidated criteria for reporting qualitative research (COREQ): a 32-item checklist for interviews and focus groups. Int J Qual Health Care. 2007;19(6):349–57.
Smith JA. Evaluating the contribution of interpretative phenomenological analysis. Health Psychol Rev. 2011;5(1):9–27.
Georgiou YS, Patsantaras N, Kamberidou I. Homophobia predictors–A case study in Greece: heterosexual physical education student attitudes towards male and female homosexuality. J Phys Educ Sport. 2018;18:1209–16.
Halbrook M, Watson JC. High school coaches’ perceptions of their efficacy to work with lesbian, gay, and bisexual athletes. Int J Sports Sci Coaching. 2018;13(6):841–8.
Atteberry-Ash B, Woodford MR. Support for policy protecting LGBT Student athletes among heterosexual students participating in Club and Intercollegiate sports. Sexuality Res Social Policy. 2017;15(2):151–62.
Mullin EM, Cook S. Collegiate coach attitudes towards lesbians and gay men. Int J Sports Sci Coaching. 2020;16(3):519–27.
Cassidy WP. Sports journalism and women athletes: Coverage of coming out stories. Springer Nature; 2019.
Martos-Garcia D, Garcia-Puchades W, Soler S, Vilanova A. From the via Crucis to Paradise. The experiences of women football players in Spain surrounding gender and homosexuality. Int Rev Sociol Sport. 2023;0(0):10126902231153349.
China Family Planning Association. 2019–2020 National College Student sexual and Reproductive Health Survey Report. China Family Planning Association; 2020.
United Nations Development Programme. Being LGBTI in China - A National Survey on Social Attitudes towards Sexual Orientation, Gender Identity and Gender Expression. 2016.
Suen YT, Chan RCH. A nationwide cross-sectional study of 15,611 lesbian, gay and bisexual people in China: disclosure of sexual orientation and experiences of negative treatment in health care. Int J Equity Health. 2020;19(1):46.
Nguyen T, Angelique H. Internalized Homonegativity, Confucianism, and self-esteem at the emergence of an LGBTQ Identity in Modern Vietnam. J Homosex. 2017;64(12):1617–31.
United States Census Bureau. US and World Population Clock 2020 [ https://www.census.gov/popclock/world
Hu X, Wang Y. LGB identity among young Chinese: the influence of traditional culture. J Homosex. 2013;60(5):667–84.
Xu L, Bao Y. Study on the influence of traditional confucianism on the Social attitude of homosexuality in Contemporary China. Chin Med Ethics. 2019;32(6):733–6.
Tseng Y-h, Sum RK-W. The attitudes of collegiate coaches toward gay and lesbian athletes in Taiwan, Hong Kong, and China. Int Rev Sociol Sport. 2020;56(3):416–35.
McCavanagh TM, Cadaret MC. Creating safe spaces for lesbian, gay, bisexual, transgender, and queer (LGBTQ+) student–athletes. Affirming LGBTQ + students in higher education. Perspectives on sexual orientation and gender diversity. Washington, DC, US: American Psychological Association; 2022. pp. 141–59.
Chavez AF, Guido-DiBrito F, Mallory SL. Learning to value the other: a framework of individual diversity development. J Coll Student Dev. 2003;44(4):453–69.
Turner JC, Reynolds KJ, Self-Categorization T. 2012 2023/06/09. In: Handbook of Theories of Social Psychology [Internet]. London: SAGE Publications Ltd. https://sk.sagepub.com/reference/hdbk_socialpsychtheories2
Latrofa M, Vaes J, Cadinu M. Self-stereotyping: the central role of an ingroup threatening identity. J Soc Psychol. 2012;152(1):92–111.
Seddig D. Individual attitudes toward deviant behavior and perceived attitudes of friends: self-stereotyping and Social Projection in Adolescence and Emerging Adulthood. J Youth Adolesc. 2020;49(3):664–77.
Liu Y, Song J. The relationship between gender self-stereotyping and life satisfaction: the Mediation Role of Relational Self-Esteem and Personal Self-Esteem. Front Psychol. 2022;12.
Organista N, Kossakowski R. Enclaved non-heteronormativity and pragmatic acceptance. The experiences of Polish female football players. Int Rev Sociol Sport. 2023;0(0):10126902231180402.
Download references
Acknowledgements
Not applicable.
No funding.
Author information
Authors and affiliations.
Department of Public Sports and Art Teaching, Hefei University, Hefei, China
Department of Sport Studies, Faculty of Educational Studies, Universiti Putra Malaysia, Seri Kembangan, Malaysia
Meng Xiang & Kim Geok Soh
Department of Marxism, West Anhui University, Luan, China
Yingying Xu
Department of Professional Development and Continuing Education, Faculty of Educational Studies, Universiti Putra Malaysia, Seri Kembangan, Malaysia
Seyedali Ahrari
Department of Counsellor Education and Counselling Psychology, Faculty of Educational Studies, Universiti Putra Malaysia, Seri Kembangan, Malaysia
Noor Syamilah Zakaria
You can also search for this author in PubMed Google Scholar
Contributions
Conceptualisation, MX.; methodology, MX; data collection, MX and YX.; data analysis, MX and YX; data curation, MX; writing—original draft preparation, MX; writing—review and editing, KS, SA, and NZ; supervision, KS, SA, and NZ. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Correspondence to Kim Geok Soh .
Ethics declarations
Ethics approval and consent to participate.
This study involving human participants was conducted in accordance with the ethical standards of the institutional research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards. The research was approved by the Ethics Committee of Universiti Putra Malaysia.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Supplementary Material 1
Supplementary material 2, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/ .
Reprints and permissions
About this article
Cite this article.
Xiang, M., Soh, K.G., Xu, Y. et al. Navigating sexual minority identity in sport: a qualitative exploration of sexual minority student-athletes in China. BMC Public Health 24 , 2304 (2024). https://doi.org/10.1186/s12889-024-19824-9
Download citation
Received : 23 January 2024
Accepted : 17 August 2024
Published : 25 August 2024
DOI : https://doi.org/10.1186/s12889-024-19824-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Identity conflicts
- Interpretive phenomenological analysis
- Mental health
- Team interaction
- Self-categorization theory
BMC Public Health
ISSN: 1471-2458
- General enquiries: [email protected]
Information
- Author Services
Initiatives
You are accessing a machine-readable page. In order to be human-readable, please install an RSS reader.
All articles published by MDPI are made immediately available worldwide under an open access license. No special permission is required to reuse all or part of the article published by MDPI, including figures and tables. For articles published under an open access Creative Common CC BY license, any part of the article may be reused without permission provided that the original article is clearly cited. For more information, please refer to https://www.mdpi.com/openaccess .
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world. Editors select a small number of articles recently published in the journal that they believe will be particularly interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the most exciting work published in the various research areas of the journal.
Original Submission Date Received: .
- Active Journals
- Find a Journal
- Proceedings Series
- For Authors
- For Reviewers
- For Editors
- For Librarians
- For Publishers
- For Societies
- For Conference Organizers
- Open Access Policy
- Institutional Open Access Program
- Special Issues Guidelines
- Editorial Process
- Research and Publication Ethics
- Article Processing Charges
- Testimonials
- Preprints.org
- SciProfiles
- Encyclopedia
Article Menu

- Subscribe SciFeed
- Recommended Articles
- Google Scholar
- on Google Scholar
- Table of Contents
Find support for a specific problem in the support section of our website.
Please let us know what you think of our products and services.
Visit our dedicated information section to learn more about MDPI.
JSmol Viewer
Investigating the effectiveness of endogenous and exogenous drivers of the sustainability (re)orientation of family smes in slovenia: qualitative content analysis approach.

1. Introduction
2. literature review, 2.1. legal framework on sustainable corporate governance (with a focus on smes), 2.1.1. corporate sustainability reporting directive, 2.1.2. corporate sustainability due diligence directive, 2.1.3. scope of the csddd for smes, 2.2. drivers of the family businesses’ (re)orientation towards sustainability, 2.3. endogenous drivers, 2.3.1. the protection of sew, 2.3.2. ownership and management composition, 2.3.3. values, beliefs and attitudes of family owner-managers, 2.3.4. transgenerational continuity and long-term orientation, 2.3.5. knowledge of sustainability, 2.4. exogenous drivers, 2.4.1. stakeholders pressure, 2.4.2. the impact of institutional environment and local communities, 3. empirical research, 3.1. institutional context of slovenia, 3.2. research method, 3.3. sampling and data collection, 3.4. data analysis, 4.1. results of the final coding of the family businesses’ sustainability (re)orientation, 4.2. references to responsibility, preserving (natural) environment and sustainability/sustainable development in the analysed statements, 4.3. family businesses with a higher level of sustainability awareness and orientation, 5. discussion, 5.1. sustainability awareness and readiness of investigated family smes to comply with the new eu legal framework, 5.2. the effectiveness of endogenous and exogenous drivers of family businesses’ sustainability (re)orientation, 6. conclusions, author contributions, institutional review board statement, informed consent statement, data availability statement, conflicts of interest.
- Communication from the Commission to the European Parliament, the Council, the European Economic and Social Committee and the Committee of The Regions, An SME Strategy for a sustainable and digital Europe, COM/2020/103 final. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=COM%3A2020%3A103%3AFIN (accessed on 25 June 2024).
- Al Malki, M.A. Review of Sustainable Growth challenges faced by Small and Medium Enterprises. Int. J. Glob. Acad. Sci. Res. 2023 , 2 , 35–43. [ Google Scholar ] [ CrossRef ]
- European Parliament and the Council. Directive (EU) 2022/2464 of the European Parliament and of the Council of 14 December 2022 amending Regulation (EU) No 537/2014, Directive 2004/109/EC, Directive 2006/43/EC, and Directive 2013/34/EU. OJ L 322, 16.12.2022, 15–80. Available online: https://eur-lex.europa.eu/eli/dir/2022/2464 (accessed on 21 August 2024).
- Fogarty, V.; Flucker, S. Sustainability. In Data Centre Essentials: Design, Construction, and Operation of Data Centres for the Non-expert ; Wiley Online Library: Hoboken, NJ, USA, 2023. [ Google Scholar ] [ CrossRef ]
- Primec, A.; Belak, J. Sustainable CSR: Legal and Managerial Demands of the New EU Legislation (CSRD) for the Future Corporate Governance Practices. Sustainability 2022 , 14 , 16648. [ Google Scholar ] [ CrossRef ]
- Umantsiv, H. Reporting on sustainable development in the context of corporate social responsibility. Cientia Ructuosa 2023 , 149 , 59–71. [ Google Scholar ] [ CrossRef ]
- European Parliament and the Council. Directive of the European Parliament and of the Council on Corporate Sustainability Due Diligence and amending Directive (EU) 2019/1937 and Regulation (EU) 2023/2859. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CONSIL:PE_9_2024_REV_1 (accessed on 25 June 2024).
- Proposal for a Directive on Corporate Sustainability Due Diligence and amending Directive (EU) 2019/1937. COM/2022/71 final. Available online: https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52022PC0071 (accessed on 29 June 2024).
- Sørensen, K.E. Corporate Sustainability Due Diligence in Groups of Companies. Eur. Co. Law 2022 , 19 , 119–130. [ Google Scholar ] [ CrossRef ]
- Arena, C.; Michelon, G. A matter of control or identity? Family firms’ environmental reporting decisions along the corporate life cycle. Bus. Strategy Environ. 2018 , 27 , 1596–1608. [ Google Scholar ] [ CrossRef ]
- Dekker, J.; Hasso, T. Environmental Performance Focus in Private Family Firms: The Role of Social Embeddedness. J. Bus. Ethics 2016 , 136 , 293–309. [ Google Scholar ] [ CrossRef ]
- Sharma, P.; Sharma, S. The Role of Family Firms in Corporate Sustainability. In The Oxford Handbook of Management Ideas ; Sturdy, A., Hueskinveld, S., Reay, T., Strang, D., Eds.; Oxford Handbooks Online: Oxford, UK, 2019; pp. 1–18. Available online: https://www.academia.edu/44598484/The_Role_of_Family_Firms_in_Corporate_Sustainability (accessed on 10 October 2023).
- European Family Business Barometer. EFB and KPMG Enterprise. Available online: http://www.europeanfamilybusinesses.eu/uploads/Modules/Publications/european-family-business-barometer7ed.pdf (accessed on 25 January 2023).
- Report on family businesses in Europe. Brussel: Committee on Industry, Research and Energy. Available online: https://www.europarl.europa.eu/doceo/document/TA-8-2015-0290_EN.pdf (accessed on 1 June 2024).
- Berrone, P.; Cruz, C.; Gomez-Mejia, L.R.; Larraza-Kintana, M. Socioemotional Wealth and Corporate Responses to Institutional Pressures: Do Family-Controlled Firms Pollute Less? Adm. Sci. Q. 2010 , 55 , 82–113. [ Google Scholar ] [ CrossRef ]
- Canavati, S. Corporate social performance in family firms: A meta-analysis. J. Fam. Bus. Manag. 2018 , 8 , 235–273. [ Google Scholar ] [ CrossRef ]
- Dyer, W.G.; Whetten, D.A. Family Firms and Social Responsibility: Preliminary Evidence from the S&P 500. Entrep. Theory Pract. 2006 , 30 , 785–802. [ Google Scholar ] [ CrossRef ]
- Cruz, C.; Larraza-Kintana, M.; Garcés-Galdeano, L.; Berrone, P. Are Family Firms Really More Socially Responsible? Entrep. Theory Pract. 2014 , 38 , 1295–1316. [ Google Scholar ] [ CrossRef ]
- Le Breton-Miller, I.; Miller, D. Family firms and practices of sustainability: A contingency view. J. Fam. Bus. Strategy 2016 , 7 , 26–33. [ Google Scholar ] [ CrossRef ]
- Samara, G.; Jamalia, D.; Sierrac, V.; Paradab, M.J. Who are the best performers? The environmental social performance of family firms. J. Fam. Bus. Strategy 2018 , 9 , 33–43. [ Google Scholar ] [ CrossRef ]
- Dal Maso, L.; Basco, R.; Bassetti, T.; Lattanzi, N. Family ownership and environmental performance: The mediation effect of human resource practices. Bus. Strategy Environ. 2020 , 29 , 1548–1562. [ Google Scholar ] [ CrossRef ]
- Dou, J.; Su, E.; Wang, S. When Does Family Ownership Promote Proactive Environmental Strategy? The Role of the Firm’s Long-Term Orientation. J. Bus. Ethics 2019 , 158 , 81–95. [ Google Scholar ] [ CrossRef ]
- Graafland, J. Family business ownership and cleaner production: Moderation by company size and family management. J. Clean. Prod. 2020 , 255 , 1–10. [ Google Scholar ] [ CrossRef ]
- Miroshnychenko, I.; De Massis, A.; Barontini, R.; Testa, F. Family Firms and Environmental Performance: A Meta-Analytic Review. Fam. Bus. Rev. 2022 , 35 , 68–90. [ Google Scholar ] [ CrossRef ]
- Van Gils, A.; Dibrell, C.; Neubaum, D.O.; Craig, J.B. Social Issues in the Family Enterprise. Fam. Bus. Rev. 2014 , 27 , 193–205. [ Google Scholar ] [ CrossRef ]
- Kim, J.; Fairclough, S.; Dibrell, C. Attention, Action, and Greenwash in Family-Influenced Firms? Evidence From Polluting Industries. Organ. Environ. 2017 , 30 , 304–323. [ Google Scholar ] [ CrossRef ]
- Sharma, P.; Sharma, S. Drivers of Proactive Environmental Strategy in Family Firms. Bus. Ethics Q. 2011 , 21 , 309–334. [ Google Scholar ] [ CrossRef ]
- Roxas, B.; Coetzer, A. Institutional Environment, Managerial Attitudes and Environmental Sustainability Orientation of Small Firms. J. Bus. Ethics 2012 , 111 , 461–476. [ Google Scholar ] [ CrossRef ]
- Vourvachis, P.; Woodward, T. Content analysis in social and environmental reporting research: Trends and challenges. J. Appl. Account. Res. 2015 , 16 , 166–195. [ Google Scholar ] [ CrossRef ]
- Eriksson, P.; Kovalainen, A. Qualitative Methods in Business Research , 2nd ed.; SAGE: Thousand Oak, CA, USA, 2016. [ Google Scholar ]
- Schreier, M. Qualitative Content Analysis in Practice ; SAGE: London, UK, 2012. [ Google Scholar ]
- Antončič, B.; Auer Antončič, J.; Juričič, D. Družinsko Podjetništvo: Značilnosti v Sloveniji (Family Entrepreneurship: Characteristics in Slovenia) ; EY: Ljubljana, Slovenia, 2015. [ Google Scholar ]
- Berrone, P.; Cruz, C.; Gomez-Mejia, L.R. Socioemotional Wealth in Family Firms: Theoretical Dimensions, Assessment Approaches, and Agenda for Future Research. Fam. Bus. Rev. 2012 , 25 , 258–279. [ Google Scholar ] [ CrossRef ]
- Gómez-Mejía, L.R.; Takács Haynes, K.; Núñez-Nickel, M.; Jacobson, K.J.L.; Moyano-Fuentes, J. Socioemotional Wealth and Business Risks in Family-controlled Firms: Evidence from Spanish Olive Oil Mills. Adm. Sci. Q. 2007 , 52 , 106–137. [ Google Scholar ] [ CrossRef ]
- Darnall, N.; Henriques, I.; Sadorsky, P. Adopting Proactive Environmental Strategy: The Influence of Stakeholders and Firm Size. J. Manag. Stud. 2010 , 47 , 1072–1094. [ Google Scholar ] [ CrossRef ]
- Gómez-Mejía, L.R.; Cruz, C.; Berrone, P.; De Castro, J. The Bind that Ties: Socioemotional Wealth Preservation in Family Firms. Acad. Manag. Ann. 2011 , 5 , 653–707. [ Google Scholar ] [ CrossRef ]
- Studdert, J.; Govender, V.; Spies, J.; Jarque Branguli, M.; Nievas, S.; Roca Silva, M.F.; Zhu, W.; Diebschlag, P.; Sassine, R.; Cilliers, W.; et al. United Nations Global Compact. Available online: https://unglobalcompact.org/what-is-gc/mission/principles (accessed on 17 March 2024).
- Primec, A.; Tičar, B. A new challenge in corporate governance—the new legal regulation of nonfinancial reporting. In Recent Challenges in Corporate Governance ; Bohinc, R., Ed.; Fakulteta za družbene vede, Založba FDV: Ljubljana, Slovenia, 2023; pp. 91–112. [ Google Scholar ] [ CrossRef ]
- Primec, A. Nefinančno poročanje kot pravni institut za vzpostavljanje korporativne družbene odgovornosti. Podjet. Delo 2023 , 6–7 , 1231–1240. Available online: https://www.dlib.si/details/URN:NBN:SI:doc-MF5DYSLE (accessed on 21 August 2024).
- Pacces, A.M. Civil Liability in the EU Corporate Sustainability Due Diligence Directive Proposal: A Law & Economics Analysis. European Corporate Governance Institute - Law Working Paper No. 691/2023, Amsterdam Law School Research Paper No. 2023-14, Amsterdam Center for Law & Economics Working Paper No. 2023-02. Forthcoming in Ondernemingsrecht. [ CrossRef ]
- Delmas, M.A.; Gergaud, O. Sustainable Certification for Future Generations: The Case of Family Business. Fam. Bus. Rev. 2014 , 27 , 228–243. [ Google Scholar ] [ CrossRef ]
- Bingham, J.B.; Dyer, W.G., Jr.; Smith, I.; Adams, G.L. A Stakeholder Identity Orientation Approach to Corporate Social Performance in Family Firms. J. Bus. Ethics 2010 , 99 , 565–585. [ Google Scholar ] [ CrossRef ]
- Cennamo, C.; Berrone, P.; Cruz, C.; Gomez-Mejia, L.R. Socioemotional Wealth and Proactive Stakeholder Engagement: Why Family-Controlled Firms Care More About Their Stakeholders. Entrep. Theory Pract. 2012 , 36 , 1153–1173. [ Google Scholar ] [ CrossRef ]
- Duh, M.; Tominc, P. Pomen, značilnosti in prihodnost družinskih podjetij (Importance, characteristics and future of family businesses). In Slovenski Podjetniški Observatorij 2004 , 2nd ed.; Rebernik, M., Tominc, P., Duh, M., Krošlin, T., Radonjič, G., Eds.; Inštitut za podjetništvo in management malih podjetij, Ekonomsko-poslovna fakulteta, Univerza v Mariboru: Maribor, Slovenia, 2005; pp. 19–31. [ Google Scholar ]
- Mandl, I. Overview of Family Business Relevant Issues. Final Report, Austrian Institute for SME Research: Vienna. Available online: https://ec.europa.eu/docsroom/documents/10389/attachments/1/translations/en/renditions/native (accessed on 1 February 2023).
- Sachs, J.D.; Kroll, C.; Lafortune, G.; Fuller, G.; Woelm, F. Sustainable Development Report 2021: Includes the SDG Index and Dashboards ; The Decade of Action for the Sustainable Development Goal; SDSN, Bertelsmann Stiftung, Cambridge University Press: Cambridge, UK, 2021. [ Google Scholar ] [ CrossRef ]
- Sachs, J.D.; Lafortune, G.; Fuller, G. The SDGs and the UN Summit of the Future. Sustainable Development Report 2024 ; SDSN: Paris, France; Dublin University Press: Dublin, Ireland, 2024. [ Google Scholar ] [ CrossRef ]
- UMAR. Poročilo o Razvoju 2023 (Report on Development 2023). Ljubljana: Urad RS za Makroekonomske Analize in Razvoj. Available online: https://www.umar.gov.si/fileadmin/user_upload/razvoj_slovenije/2023/slovenski/POR2023-splet.pdf (accessed on 10 April 2024).
- Creswell, J.W. Qualitative Inquiry and Research Design: Choosing among Five Approaches ; SAGE: Thousand Oaks, CA, USA, 2013. [ Google Scholar ]
- Myers, M.D. Qualitative Research in Business & Management ; SAGE: Thousand Oaks, CA, USA, 2013. [ Google Scholar ]
- De Massis, A.; Kotlar, A. The case study method in family business research: Guidelines for qualitative scholarship. J. Fam. Bus. Strategy 2014 , 5 , 15–29. [ Google Scholar ] [ CrossRef ]
- Campopiano, G.; De Massis, A. Corporate Social Responsibility Reporting: A Content Analysis in Family and Nonfamily. J. Bus. Ethics 2015 , 129 , 511–534. [ Google Scholar ] [ CrossRef ]
- Craig, J.; Dibrell, C. The Natural Environment, Innovation, and Firm Performance: A Comparative Study. Fam. Bus. Rev. 2006 , 19 , 275–288. [ Google Scholar ] [ CrossRef ]
- Sharma, P.; Chrisman, J.J.; Chua, J.H. Predictors of satisfaction with the succession process in family firms. J. Bus. Ventur. 2003 , 18 , 667–687. [ Google Scholar ] [ CrossRef ]
- Whittingham, K.L.; Earle, A.G.; Leyva-de la Hiz, D.I.; Argiolas, A. The impact of the United Nations Sustainable Development Goals on corporate sustainability reporting. Bus. Res. Q. 2023 , 26 , 45–61. [ Google Scholar ] [ CrossRef ]
- Cabrera-Suárez, K. Leadership transfer and the successor’s development in the family firm. Leadership Quarterly 2005 , 16 , 71–96. [ Google Scholar ] [ CrossRef ]
- Rus, D.; Močnik, D.; Crnogaj, K. Podjetniška Demografija in Značilnosti Startup in Scaleup Podjetij: Slovenski Podjetniški Observatorij 2022 (Business Demographics and Characteristics of Startup and Scaleup Companies: Slovenian Entrepreneurship Observatory 2022) ; niverza v Mariboru, Univerzitetna založba: Maribor, Slovenia, 2023. [ Google Scholar ]
- Data base of Slovenian exporters. Available online: https://www.sloexport.si/ (accessed on 30 August 2023).
- Bizi. Data base of financial and contact data of Slovenian companies. Available online: https://www.bizi.si/ (accessed on 30 August 2023).
- Family Business Slovenia 2019. Ljubljana: EY. Available online: https://www.ey.com/en_si/family-enterprise/familiy-business-book-slovenia-2019 (accessed on 30 November 2023).
- Family Business Slovenia 2020. Ljubljana: EY. Available online: https://www.ey.com/en_si/family-enterprise/family-business-book-slovenia-2021 (accessed on 30 November 2023).
- Family Business Slovenia 2021. Ljubljana: EY. Available online: https://www.ey.com/en_si/family-enterprise/family-business-book-slovenia-2020 (accessed on 30 November 2023).
- Payne, G.T.; Brigham, K.H.; Broberg, J.C.; Moss, T.W.; Short, J.C. Organizational Virtue Orientation and Family Firms. Bus. Ethics Q. 2011 , 21 , 257–285. [ Google Scholar ] [ CrossRef ]
- Schreier, M. Qualitative Content Analysis. In The SAGE Handbook of Qualitative Data Analysis ; Flick, U., Ed.; SAGE: Thousand Oaks, CA, USA, 2014; pp. 170–183. [ Google Scholar ]
- Müller-Stewens, G.; Lechner, C. Strategisches Management, 5. Auflage ; Schäffer-Poeschel Verlag: Stuttgart, Germany, 2016. [ Google Scholar ]
- Wheelen, T.L.; Hunger, J.D. Strategic Management and Business Policy. Toward Global Sustainability , 13th ed.; Prentice Hall, Pearson: New Jersey, NJ, USA, 2012. [ Google Scholar ]
- WCED. Our Common Future. Report of the World Commission on Environment and Development. Available online: https://sustainabledevelopment.un.org/content/documents/5987our-common-future.pdf (accessed on 1 October 2021).
- Sjåfjell, B. Reforming EU company law to secure the future of European business. Eur. Co. Financ. Law Rev. 2021 , 18 , 190–217. [ Google Scholar ] [ CrossRef ]
| No. of Category | Category Name and Its Definition | No. of Subcat. | Subcategory |
|---|---|---|---|
| C1 | Vision Describe what a firm would like to become. | C1.1 | Reference to sustainability/sustainable development |
| C1.2 | Reference to preserving (natural) environment | ||
| C1.3 | Reference to a position in market(s) and/or industry | ||
| C1.4 | Reference to the characteristics of products | ||
| C1.5 | Miscellaneous | ||
| C2 | Mission Defines the purpose and reason why a firm exists. | C2.1 | Reference to sustainability/sustainable development |
| C2.2 | Reference to preserving (natural) environment | ||
| C2.3 | Reference to the characteristics of products | ||
| C2.4 | Reference to the customers’ needs | ||
| C3 | Goals The result of planned activities, can be quantified or open-ended statement with no quantification. | C3.1 | Reference to sustainability/sustainable development |
| C3.2 | Reference to a position in market(s) and/or industry | ||
| C3.3 | Miscellaneous | ||
| C4 | Values Consider what should be and what is desirable. | C4.1 | Reference to sustainability/sustainable development |
| C4.2 | Reference to preserving (natural) environment | ||
| C4.3 | Reference to responsibility | ||
| C4.4 | Miscellaneous | ||
| C5 | Strategies or strategic directions State how a company is going to achieve its vision, mission and goals. | C5.1 | Reference to sustainability/sustainable development |
| C5.2 | Reference to preserving (natural) environment | ||
| C5.3 | References to (expansion to) new markets | ||
| C6 | Specific of functioning Activities, processes, behaviour. | C6.1 | Reference to sustainability/sustainable development |
| C6.2 | Reference to preserving (natural) environment | ||
| C6.3 | Reference to the characteristics of products | ||
| C6.4 | Reference to competitive strengths | ||
| C6.5 | Miscellaneous |
| Unit of Analysis (A Family Business) | C1 Vision | C2 Mission | C3 Goals | C4 Values | C5 Strategies or Strategic Directions | C6 Specifics of Functioning |
|---|---|---|---|---|---|---|
| U1 | C1.1 | C2.1 | C3.2 | C5.1 | ||
| U2 | C5.3 | C6.4 | ||||
| U3 | C6.2 | |||||
| U4 | C2.4 | C3.2 | ||||
| U5 | C1.3 | C3.2 | C5.2 | |||
| U6 | C1.3 | C2.4 | ||||
| U7 | C3.2 | C6.3 | ||||
| U8 | C1.1 | C4.3 | C6.1 | |||
| U9 | C1.3 | C2.2 | C5.3 | C6.2 | ||
| U10 | C1.4 | |||||
| U11 | C3.2 | |||||
| U12 | C3.2 | C4.2 | C6.2 | |||
| U13 | C4.1 | C6.2 | ||||
| U14 | C1.2 | C2.3 | C6.4 | |||
| U15 | C1.4 | C2.3 | ||||
| U16 | C1.1 | C6.1 | ||||
| U17 | C6.4 | |||||
| U18 | C1.5 | C4.2 | ||||
| U19 | C1.2 | C3.3 | C6.2 | |||
| U20 | C6.3 | |||||
| U21 | C1.3 | C2.4 | C4.2 | |||
| U22 | C1.3 | C4.2 | C6.2 | |||
| U23 | C1.1 | C4.4 | C5.1 | C6.1 | ||
| U24 | C1.3 | C4.3 | C6.4 | |||
| U25 | C1.1 | C2.2 | C3.1 | C5.1 | C6.2 | |
| U26 | C6.4 | |||||
| Family businesses with published statement (number) | 16 | 8 | 8 | 8 | 6 | 17 |
| Family businesses with reference to sustainability and protection of natural environment, responsibility (number) | 7 | 3 | 1 | 7 | 4 | 10 |
| U1 | U8 | U23 | U25 | |
|---|---|---|---|---|
| Family name in in the name of a company | no | no | no | no |
| Ownership (generation, number of family owners, % of family ownership) | first and second generation (father, two sons), 100% | first generation (founder), 100% | first generation (husband and wife), 100% | first generation (founder), 100% |
| Management (generation, number of family managers) | second generation (two sons) | first generation (founder’s wife) | first and second generation (husband, wife, and both children) | first and second generation (founder—father, daughter) |
| Size | small | medium-sized | medium-sized | medium-sized |
| Main activity and markets | wholesale and retail trade; market: Slovenia | manufacturing; markets: Slovenia, other countries | manufacturing; markets: Slovenia, other countries | manufacturing; markets: Slovenia, other countries |
| The year of establishment | 1990 | 1989 | 1995 | 1992 |
| Family Name in the Name of a Company | Ownership (Generation, % of Family Ownership) | Management (Generation) | Size | Main Activity | The Year of Establishment | |
|---|---|---|---|---|---|---|
| U2 | no | first and second, 100% | second | small | manufacturing | 1993 |
| U4 | yes | third, 100% | third | small | manufacturing | 1992 |
| U6 | no | second, 100% | second | small | manufacturing | 1995 |
| U7 | yes | first, 100% | first | small | wholesale and retail trade | 1993 |
| U10 | no | first, 100% | first | micro | service activities | 2009 |
| U11 | no | third, 100% | third | small | wholesale and retail trade | 1960 |
| U15 | no | first and second, 100% | first and second | small | agriculture | 1991 |
| U17 | no | first, 100% | first and second | micro | agriculture | 2007 |
| U20 | yes | first, 100% | first and second | small | manufacturing | 1982 |
| U26 | yes | Second, 100% | second | medium-sized | wholesale and retail trade | 1988 |
| The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Share and Cite
Duh, M.; Primec, A. Investigating the Effectiveness of Endogenous and Exogenous Drivers of the Sustainability (Re)Orientation of Family SMEs in Slovenia: Qualitative Content Analysis Approach. Sustainability 2024 , 16 , 7285. https://doi.org/10.3390/su16177285
Duh M, Primec A. Investigating the Effectiveness of Endogenous and Exogenous Drivers of the Sustainability (Re)Orientation of Family SMEs in Slovenia: Qualitative Content Analysis Approach. Sustainability . 2024; 16(17):7285. https://doi.org/10.3390/su16177285
Duh, Mojca, and Andreja Primec. 2024. "Investigating the Effectiveness of Endogenous and Exogenous Drivers of the Sustainability (Re)Orientation of Family SMEs in Slovenia: Qualitative Content Analysis Approach" Sustainability 16, no. 17: 7285. https://doi.org/10.3390/su16177285
Article Metrics
Article access statistics, further information, mdpi initiatives, follow mdpi.
Subscribe to receive issue release notifications and newsletters from MDPI journals
IMAGES
COMMENTS
Learn what qualitative data coding is, why it's important, and how to do it with examples. Explore different types of coding approaches (deductive, inductive, hybrid) and the coding process (initial and line by line).
An introduction to the analytical process of coding qualitative data. Learn how to take data from qualitative methods and interpret, organize, and structure your observations and interpretations into meaningful theories.
This manual serves as a reference to supplement existing works in qualitative research design and fieldwork. It focuses exclusively on codes and coding and how they play a role in the qualitative data analytic process. For newcomers to qualitative inquiry it presents a repertoire of coding methods in broad brushstrokes.
General knowledge about qualitative data analysis, how to code qualitative data and decisions concerning related research design in the analytical process are all important for novice researchers.
Coding is a qualitative data analysis strategy in which some aspect of the data is assigned a descriptive label that allows the researcher to identify related content across the data. How you decide to code - or whether to code- your data should be driven by your methodology. But there are rarely step-by-step descriptions, and you'll have to ...
This chapter provides an overview of selected qualitative data analytic strategies with a particular focus on codes and coding. Preparatory strategies for a qualitative research study and data management are first outlined. Six coding methods are then profiled using comparable interview data: process coding, in vivo coding, descriptive coding ...
A starting guide for coding qualitative data manually and automatically. Learn to build a coding frame and find significant themes in your data!
This chapter introduces you to the process of qualitative data analysis and the basic concept of coding, while the following chapter (chapter 19) will take you further into the various kinds of codes and how to use them effectively. To those who have not yet conducted a qualitative study, the sheer amount of collected data will be a surprise.
The Coding Manual for Qualitative Researchers Welcome to the companion website for The Coding Manual for Qualitative Research, third edition, by Johnny Saldaña. This website offers a wealth of additional resources to support students and lecturers including: CAQDAS links giving guidance and links to a variety of qualitative data analysis software.
In The Coding Manual for Qualitative Researchers, Johnny Saldaña presents a. developmental summary of qualitative coding techniques (2021). The fourt h edition is reformatted. to fifteen chapters ...
Saldana presents a range of coding options with advantages and disadvantages to help researchers to choose the most appropriate approach for their project, reinforcing their perspective with real world examples, used to show step-by-step processes and to demonstrate important skills. Chapter 2: Fundamental Coding Methods and Techniques.
Coding qualitative data Qualitative coding is almost always a necessary part of the qualitative data analysis process. Coding provides a way to make the meaning of the data clear to you and to your research audience. What is a code? A code in the context of qualitative data analysis is a summary of a larger segment of text. Imagine applying a couple of sticky notes to a collection of recipes ...
Abstract Coding is an integral part of qualitative research for many scholars that use interview or focus group data. However, current practices in coding require transcription of audio/visual data prior to coding. Transcription before the coding process is an essential process for data analysis and even with meticulous detail, the nuances of nonverbal behavior found in audio and video data ...
Deductive and Inductive Coding You create codes because you deem the identified topics/concepts/ideas as important and relevant to your study. Deductive Coding Codes emerge from your research question and/or the literature review. Inductive Coding Codes emerge through engagement with your actual data sources and/or data set.
Learn why coding qualitative data is important, understand the different approaches to coding, and get tips for doing it yourself.
Thematic Analysis Process The principles of the thematic analysis technique, such as coding of data, searching for themes, refining the themes, and reporting the findings, are relatable to other qualitative methods, such as discourse analysis ( Flick, 2022 ). Thematic analysis is a method to analyze qualitative data.
This course consists of the second half of the course, and covers what to do with the data once you have started collecting it. This will include transcribing data, creating codes and codebooks, coding data, analyzing codes, and how to make sense of your analysis using existing and new theory. You may have encountered other forms of data ...
With the advent and proliferation of analysis software (e.g., Nvivo, Atlas.ti), coding data has become much easier in terms of application. Where autocoding algorithms do much to assist and enlighten a researcher in analysis, coding qualitative data remains an act...
10.6 Qualitative Coding, Analysis, and Write-up: The How to Guide This section provides an abbreviated set of steps and directions for coding, analyzing, and writing up qualitative data, taking an inductive approach.
Qualitative Data Coding. ABSTRACT. In the quest to address a research problem, meeting the purpose of the study, and answer ing. qualitative research question (s), we actively look for the right ...
The living codebook has implications for other types of qualitative data analysis, such as the coding of interview data. Coding interview data similarly organizes text—transcripts—into patterns to uncover common themes. However, we also recognize differences in coding interviews versus the coding of documents.
Qualitative Data Coding serves as a crucial technique in qualitative research, transforming raw data into actionable insights. Researchers often collect vast amounts of unstructured information through interviews, focus groups, or other methods. Without effective coding, this rich data can become overwhelming and difficult to analyze.
The Coding Manual for Qualitative Researchers addresses an important aspect of many qualitative research traditions, the process of attaching meaningful attributes (codes) to qualitative data that allows researchers to engage in a range of analytic processes (e.g. pattern detection, categorization and theory building). It is a book intended to "supplement introductory works in the subject ...
The aim of qualitative research is to gather in-depth data from participants regarding their thoughts, ideas, opinions, and lived experiences in relation to certain issues or social phenomena. Researchers often gather participants' experiences utilising a variety of qualitative techniques, including focus groups, interviews, and observation ...
This study aimed to explore the stressors experienced by older patients with stroke in convalescent rehabilitation wards in Japan. Semi-structured interviews were conducted with four stroke patients aged > 65 years who experienced a stroke for the first time in their lives. The interviews were analyzed using the Steps for Coding and Theorization method for qualitative data analysis. The ...
Driven by customer feedback, NVivo 15 addresses the growing need for more streamlined workflows and efficient qualitative research methods, ensuring researchers can achieve insightful and accurate results with greater ease and speed. With NVivo 15, researchers can organize and explore data from any source, visualize connections that are ...
Methods: Semistructured interviews were carried out with 20 experts (stakeholders in direct contact with young people, researchers, and institutional actors) specializing in sexual health, health promotion, peer education, youth, internet, and social media. After coding with N'Vivo, data were subjected to qualitative thematic analysis.
Background Sexual minority student-athletes (SMSAs) face discrimination and identity conflicts in intercollegiate sport, impacting their participation and mental health. This study explores the perceptions of Chinese SMSAs regarding their sexual minority identities, aiming to fill the current gap in research related to non-Western countries. Methods A qualitative methodology was adopted ...
Due to the exploratory nature of our research, we applied a qualitative case study research method where the qualitative content analysis was used in the process of analysing data. Content analysis is often applied in the research on environmental and sustainability reporting [ 10 , 29 ] and we find it as an adequate approach for addressing the ...