Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Sampling Methods | Types, Techniques & Examples

Sampling Methods | Types, Techniques & Examples
Published on September 19, 2019 by Shona McCombes . Revised on June 22, 2023.
When you conduct research about a group of people, it’s rarely possible to collect data from every person in that group. Instead, you select a sample . The sample is the group of individuals who will actually participate in the research.
To draw valid conclusions from your results, you have to carefully decide how you will select a sample that is representative of the group as a whole. This is called a sampling method . There are two primary types of sampling methods that you can use in your research:
- Probability sampling involves random selection, allowing you to make strong statistical inferences about the whole group.
- Non-probability sampling involves non-random selection based on convenience or other criteria, allowing you to easily collect data.
You should clearly explain how you selected your sample in the methodology section of your paper or thesis, as well as how you approached minimizing research bias in your work.
Table of contents
Population vs. sample, probability sampling methods, non-probability sampling methods, other interesting articles, frequently asked questions about sampling.
First, you need to understand the difference between a population and a sample , and identify the target population of your research.
- The population is the entire group that you want to draw conclusions about.
- The sample is the specific group of individuals that you will collect data from.
The population can be defined in terms of geographical location, age, income, or many other characteristics.

It is important to carefully define your target population according to the purpose and practicalities of your project.
If the population is very large, demographically mixed, and geographically dispersed, it might be difficult to gain access to a representative sample. A lack of a representative sample affects the validity of your results, and can lead to several research biases , particularly sampling bias .
Sampling frame
The sampling frame is the actual list of individuals that the sample will be drawn from. Ideally, it should include the entire target population (and nobody who is not part of that population).
Sample size
The number of individuals you should include in your sample depends on various factors, including the size and variability of the population and your research design. There are different sample size calculators and formulas depending on what you want to achieve with statistical analysis .
Prevent plagiarism. Run a free check.
Probability sampling means that every member of the population has a chance of being selected. It is mainly used in quantitative research . If you want to produce results that are representative of the whole population, probability sampling techniques are the most valid choice.
There are four main types of probability sample.

1. Simple random sampling
In a simple random sample, every member of the population has an equal chance of being selected. Your sampling frame should include the whole population.
To conduct this type of sampling, you can use tools like random number generators or other techniques that are based entirely on chance.
2. Systematic sampling
Systematic sampling is similar to simple random sampling, but it is usually slightly easier to conduct. Every member of the population is listed with a number, but instead of randomly generating numbers, individuals are chosen at regular intervals.
If you use this technique, it is important to make sure that there is no hidden pattern in the list that might skew the sample. For example, if the HR database groups employees by team, and team members are listed in order of seniority, there is a risk that your interval might skip over people in junior roles, resulting in a sample that is skewed towards senior employees.
3. Stratified sampling
Stratified sampling involves dividing the population into subpopulations that may differ in important ways. It allows you draw more precise conclusions by ensuring that every subgroup is properly represented in the sample.
To use this sampling method, you divide the population into subgroups (called strata) based on the relevant characteristic (e.g., gender identity, age range, income bracket, job role).
Based on the overall proportions of the population, you calculate how many people should be sampled from each subgroup. Then you use random or systematic sampling to select a sample from each subgroup.
4. Cluster sampling
Cluster sampling also involves dividing the population into subgroups, but each subgroup should have similar characteristics to the whole sample. Instead of sampling individuals from each subgroup, you randomly select entire subgroups.
If it is practically possible, you might include every individual from each sampled cluster. If the clusters themselves are large, you can also sample individuals from within each cluster using one of the techniques above. This is called multistage sampling .
This method is good for dealing with large and dispersed populations, but there is more risk of error in the sample, as there could be substantial differences between clusters. It’s difficult to guarantee that the sampled clusters are really representative of the whole population.
In a non-probability sample, individuals are selected based on non-random criteria, and not every individual has a chance of being included.
This type of sample is easier and cheaper to access, but it has a higher risk of sampling bias . That means the inferences you can make about the population are weaker than with probability samples, and your conclusions may be more limited. If you use a non-probability sample, you should still aim to make it as representative of the population as possible.
Non-probability sampling techniques are often used in exploratory and qualitative research . In these types of research, the aim is not to test a hypothesis about a broad population, but to develop an initial understanding of a small or under-researched population.

1. Convenience sampling
A convenience sample simply includes the individuals who happen to be most accessible to the researcher.
This is an easy and inexpensive way to gather initial data, but there is no way to tell if the sample is representative of the population, so it can’t produce generalizable results. Convenience samples are at risk for both sampling bias and selection bias .
2. Voluntary response sampling
Similar to a convenience sample, a voluntary response sample is mainly based on ease of access. Instead of the researcher choosing participants and directly contacting them, people volunteer themselves (e.g. by responding to a public online survey).
Voluntary response samples are always at least somewhat biased , as some people will inherently be more likely to volunteer than others, leading to self-selection bias .
3. Purposive sampling
This type of sampling, also known as judgement sampling, involves the researcher using their expertise to select a sample that is most useful to the purposes of the research.
It is often used in qualitative research , where the researcher wants to gain detailed knowledge about a specific phenomenon rather than make statistical inferences, or where the population is very small and specific. An effective purposive sample must have clear criteria and rationale for inclusion. Always make sure to describe your inclusion and exclusion criteria and beware of observer bias affecting your arguments.
4. Snowball sampling
If the population is hard to access, snowball sampling can be used to recruit participants via other participants. The number of people you have access to “snowballs” as you get in contact with more people. The downside here is also representativeness, as you have no way of knowing how representative your sample is due to the reliance on participants recruiting others. This can lead to sampling bias .
5. Quota sampling
Quota sampling relies on the non-random selection of a predetermined number or proportion of units. This is called a quota.
You first divide the population into mutually exclusive subgroups (called strata) and then recruit sample units until you reach your quota. These units share specific characteristics, determined by you prior to forming your strata. The aim of quota sampling is to control what or who makes up your sample.
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
- Quartiles & Quantiles
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Prospective cohort study
Research bias
- Implicit bias
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hindsight bias
- Affect heuristic
- Social desirability bias
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

A sample is a subset of individuals from a larger population . Sampling means selecting the group that you will actually collect data from in your research. For example, if you are researching the opinions of students in your university, you could survey a sample of 100 students.
In statistics, sampling allows you to test a hypothesis about the characteristics of a population.
Samples are used to make inferences about populations . Samples are easier to collect data from because they are practical, cost-effective, convenient, and manageable.
Probability sampling means that every member of the target population has a known chance of being included in the sample.
Probability sampling methods include simple random sampling , systematic sampling , stratified sampling , and cluster sampling .
In non-probability sampling , the sample is selected based on non-random criteria, and not every member of the population has a chance of being included.
Common non-probability sampling methods include convenience sampling , voluntary response sampling, purposive sampling , snowball sampling, and quota sampling .
In multistage sampling , or multistage cluster sampling, you draw a sample from a population using smaller and smaller groups at each stage.
This method is often used to collect data from a large, geographically spread group of people in national surveys, for example. You take advantage of hierarchical groupings (e.g., from state to city to neighborhood) to create a sample that’s less expensive and time-consuming to collect data from.
Sampling bias occurs when some members of a population are systematically more likely to be selected in a sample than others.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2023, June 22). Sampling Methods | Types, Techniques & Examples. Scribbr. Retrieved August 18, 2024, from https://www.scribbr.com/methodology/sampling-methods/
Is this article helpful?

Shona McCombes
Other students also liked, population vs. sample | definitions, differences & examples, simple random sampling | definition, steps & examples, sampling bias and how to avoid it | types & examples, what is your plagiarism score.
Educational resources and simple solutions for your research journey

What are Sampling Methods? Techniques, Types, and Examples
Every type of research includes samples from which inferences are drawn. The sample could be biological specimens or a subset of a specific group or population selected for analysis. The goal is often to conclude the entire population based on the characteristics observed in the sample. Now, the question comes to mind: how does one collect the samples? Answer: Using sampling methods. Various sampling strategies are available to researchers to define and collect samples that will form the basis of their research study.
In a study focusing on individuals experiencing anxiety, gathering data from the entire population is practically impossible due to the widespread prevalence of anxiety. Consequently, a sample is carefully selected—a subset of individuals meant to represent (or not in some cases accurately) the demographics of those experiencing anxiety. The study’s outcomes hinge significantly on the chosen sample, emphasizing the critical importance of a thoughtful and precise selection process. The conclusions drawn about the broader population rely heavily on the selected sample’s characteristics and diversity.
Table of Contents
What is sampling?
Sampling involves the strategic selection of individuals or a subset from a population, aiming to derive statistical inferences and predict the characteristics of the entire population. It offers a pragmatic and practical approach to examining the features of the whole population, which would otherwise be difficult to achieve because studying the total population is expensive, time-consuming, and often impossible. Market researchers use various sampling methods to collect samples from a large population to acquire relevant insights. The best sampling strategy for research is determined by criteria such as the purpose of the study, available resources (time and money), and research hypothesis.
For example, if a pet food manufacturer wants to investigate the positive impact of a new cat food on feline growth, studying all the cats in the country is impractical. In such cases, employing an appropriate sampling technique from the extensive dataset allows the researcher to focus on a manageable subset. This enables the researcher to study the growth-promoting effects of the new pet food. This article will delve into the standard sampling methods and explore the situations in which each is most appropriately applied.

What are sampling methods or sampling techniques?
Sampling methods or sampling techniques in research are statistical methods for selecting a sample representative of the whole population to study the population’s characteristics. Sampling methods serve as invaluable tools for researchers, enabling the collection of meaningful data and facilitating analysis to identify distinctive features of the people. Different sampling strategies can be used based on the characteristics of the population, the study purpose, and the available resources. Now that we understand why sampling methods are essential in research, we review the various sample methods in the following sections.
Types of sampling methods
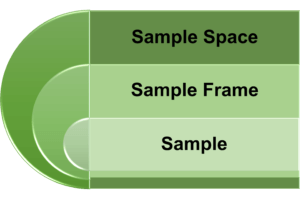
Before we go into the specifics of each sampling method, it’s vital to understand terms like sample, sample frame, and sample space. In probability theory, the sample space comprises all possible outcomes of a random experiment, while the sample frame is the list or source guiding sample selection in statistical research. The sample represents the group of individuals participating in the study, forming the basis for the research findings. Selecting the correct sample is critical to ensuring the validity and reliability of any research; the sample should be representative of the population.
There are two most common sampling methods:
- Probability sampling: A sampling method in which each unit or element in the population has an equal chance of being selected in the final sample. This is called random sampling, emphasizing the random and non-zero probability nature of selecting samples. Such a sampling technique ensures a more representative and unbiased sample, enabling robust inferences about the entire population.
- Non-probability sampling: Another sampling method is non-probability sampling, which involves collecting data conveniently through a non-random selection based on predefined criteria. This offers a straightforward way to gather data, although the resulting sample may or may not accurately represent the entire population.
Irrespective of the research method you opt for, it is essential to explicitly state the chosen sampling technique in the methodology section of your research article. Now, we will explore the different characteristics of both sampling methods, along with various subtypes falling under these categories.
What is probability sampling?
The probability sampling method is based on the probability theory, which means that the sample selection criteria involve some random selection. The probability sampling method provides an equal opportunity for all elements or units within the entire sample space to be chosen. While it can be labor-intensive and expensive, the advantage lies in its ability to offer a more accurate representation of the population, thereby enhancing confidence in the inferences drawn in the research.
Types of probability sampling
Various probability sampling methods exist, such as simple random sampling, systematic sampling, stratified sampling, and clustered sampling. Here, we provide detailed discussions and illustrative examples for each of these sampling methods:

- Simple random sampling: In simple random sampling, each individual has an equal probability of being chosen, and each selection is independent of the others. Because the choice is entirely based on chance, this is also known as the method of chance selection. In the simple random sampling method, the sample frame comprises the entire population.
For example, A fitness sports brand is launching a new protein drink and aims to select 20 individuals from a 200-person fitness center to try it. Employing a simple random sampling approach, each of the 200 people is assigned a unique identifier. Of these, 20 individuals are then chosen by generating random numbers between 1 and 200, either manually or through a computer program. Matching these numbers with the individuals creates a randomly selected group of 20 people. This method minimizes sampling bias and ensures a representative subset of the entire population under study.

- Systematic sampling: The systematic sampling approach involves selecting units or elements at regular intervals from an ordered list of the population. Because the starting point of this sampling method is chosen at random, it is more convenient than essential random sampling. For a better understanding, consider the following example.
For example, considering the previous model, individuals at the fitness facility are arranged alphabetically. The manufacturer then initiates the process by randomly selecting a starting point from the first ten positions, let’s say 8. Starting from the 8th position, every tenth person on the list is then chosen (e.g., 8, 18, 28, 38, and so forth) until a sample of 20 individuals is obtained.

- Stratified sampling: Stratified sampling divides the population into subgroups (strata), and random samples are drawn from each stratum in proportion to its size in the population. Stratified sampling provides improved representation because each subgroup that differs in significant ways is included in the final sample.
For example, Expanding on the previous simple random sampling example, suppose the manufacturer aims for a more comprehensive representation of genders in a sample of 200 people, consisting of 90 males, 80 females, and 30 others. The manufacturer categorizes the population into three gender strata (Male, Female, and Others). Within each group, random sampling is employed to select nine males, eight females, and three individuals from the others category, resulting in a well-rounded and representative sample of 200 individuals.
- Clustered sampling: In this sampling method, the population is divided into clusters, and then a random sample of clusters is included in the final sample. Clustered sampling, distinct from stratified sampling, involves subgroups (clusters) that exhibit characteristics similar to the whole sample. In the case of small clusters, all members can be included in the final sample, whereas for larger clusters, individuals within each cluster may be sampled using the sampling above methods. This approach is referred to as multistage sampling. This sampling method is well-suited for large and widely distributed populations; however, there is a potential risk of sample error because ensuring that the sampled clusters truly represent the entire population can be challenging.

For example, Researchers conducting a nationwide health study can select specific geographic clusters, like cities or regions, instead of trying to survey the entire population individually. Within each chosen cluster, they sample individuals, providing a representative subset without the logistical challenges of attempting a nationwide survey.
Use s of probability sampling
Probability sampling methods find widespread use across diverse research disciplines because of their ability to yield representative and unbiased samples. The advantages of employing probability sampling include the following:
- Representativeness
Probability sampling assures that every element in the population has a non-zero chance of being included in the sample, ensuring representativeness of the entire population and decreasing research bias to minimal to non-existent levels. The researcher can acquire higher-quality data via probability sampling, increasing confidence in the conclusions.
- Statistical inference
Statistical methods, like confidence intervals and hypothesis testing, depend on probability sampling to generalize findings from a sample to the broader population. Probability sampling methods ensure unbiased representation, allowing inferences about the population based on the characteristics of the sample.
- Precision and reliability
The use of probability sampling improves the precision and reliability of study results. Because the probability of selecting any single element/individual is known, the chance variations that may occur in non-probability sampling methods are reduced, resulting in more dependable and precise estimations.
- Generalizability
Probability sampling enables the researcher to generalize study findings to the entire population from which they were derived. The results produced through probability sampling methods are more likely to be applicable to the larger population, laying the foundation for making broad predictions or recommendations.
- Minimization of Selection Bias
By ensuring that each member of the population has an equal chance of being selected in the sample, probability sampling lowers the possibility of selection bias. This reduces the impact of systematic errors that may occur in non-probability sampling methods, where data may be skewed toward a specific demographic due to inadequate representation of each segment of the population.
What is non-probability sampling?
Non-probability sampling methods involve selecting individuals based on non-random criteria, often relying on the researcher’s judgment or predefined criteria. While it is easier and more economical, it tends to introduce sampling bias, resulting in weaker inferences compared to probability sampling techniques in research.
Types of Non-probability Sampling
Non-probability sampling methods are further classified as convenience sampling, consecutive sampling, quota sampling, purposive or judgmental sampling, and snowball sampling. Let’s explore these types of sampling methods in detail.
- Convenience sampling: In convenience sampling, individuals are recruited directly from the population based on the accessibility and proximity to the researcher. It is a simple, inexpensive, and practical method of sample selection, yet convenience sampling suffers from both sampling and selection bias due to a lack of appropriate population representation.

For example, imagine you’re a researcher investigating smartphone usage patterns in your city. The most convenient way to select participants is by approaching people in a shopping mall on a weekday afternoon. However, this convenience sampling method may not be an accurate representation of the city’s overall smartphone usage patterns as the sample is limited to individuals present at the mall during weekdays, excluding those who visit on other days or never visit the mall.
- Consecutive sampling: Participants in consecutive sampling (or sequential sampling) are chosen based on their availability and desire to participate in the study as they become available. This strategy entails sequentially recruiting individuals who fulfill the researcher’s requirements.
For example, In researching the prevalence of stroke in a hospital, instead of randomly selecting patients from the entire population, the researcher can opt to include all eligible patients admitted over three months. Participants are then consecutively recruited upon admission during that timeframe, forming the study sample.
- Quota sampling: The selection of individuals in quota sampling is based on non-random selection criteria in which only participants with certain traits or proportions that are representative of the population are included. Quota sampling involves setting predetermined quotas for specific subgroups based on key demographics or other relevant characteristics. This sampling method employs dividing the population into mutually exclusive subgroups and then selecting sample units until the set quota is reached.

For example, In a survey on a college campus to assess student interest in a new policy, the researcher should establish quotas aligned with the distribution of student majors, ensuring representation from various academic disciplines. If the campus has 20% biology majors, 30% engineering majors, 20% business majors, and 30% liberal arts majors, participants should be recruited to mirror these proportions.
- Purposive or judgmental sampling: In purposive sampling, the researcher leverages expertise to select a sample relevant to the study’s specific questions. This sampling method is commonly applied in qualitative research, mainly when aiming to understand a particular phenomenon, and is suitable for smaller population sizes.

For example, imagine a researcher who wants to study public policy issues for a focus group. The researcher might purposely select participants with expertise in economics, law, and public administration to take advantage of their knowledge and ensure a depth of understanding.
- Snowball sampling: This sampling method is used when accessing the population is challenging. It involves collecting the sample through a chain-referral process, where each recruited candidate aids in finding others. These candidates share common traits, representing the targeted population. This method is often used in qualitative research, particularly when studying phenomena related to stigmatized or hidden populations.

For example, In a study focusing on understanding the experiences and challenges of individuals in hidden or stigmatized communities (e.g., LGBTQ+ individuals in specific cultural contexts), the snowball sampling technique can be employed. The researcher initiates contact with one community member, who then assists in identifying additional candidates until the desired sample size is achieved.
Uses of non-probability sampling
Non-probability sampling approaches are employed in qualitative or exploratory research where the goal is to investigate underlying population traits rather than generalizability. Non-probability sampling methods are also helpful for the following purposes:
- Generating a hypothesis
In the initial stages of exploratory research, non-probability methods such as purposive or convenience allow researchers to quickly gather information and generate hypothesis that helps build a future research plan.
- Qualitative research
Qualitative research is usually focused on understanding the depth and complexity of human experiences, behaviors, and perspectives. Non-probability methods like purposive or snowball sampling are commonly used to select participants with specific traits that are relevant to the research question.
- Convenience and pragmatism
Non-probability sampling methods are valuable when resource and time are limited or when preliminary data is required to test the pilot study. For example, conducting a survey at a local shopping mall to gather opinions on a consumer product due to the ease of access to potential participants.
Probability vs Non-probability Sampling Methods
| Selection of participants | Random selection of participants from the population using randomization methods | Non-random selection of participants from the population based on convenience or criteria |
| Representativeness | Likely to yield a representative sample of the whole population allowing for generalizations | May not yield a representative sample of the whole population; poor generalizability |
| Precision and accuracy | Provides more precise and accurate estimates of population characteristics | May have less precision and accuracy due to non-random selection |
| Bias | Minimizes selection bias | May introduce selection bias if criteria are subjective and not well-defined |
| Statistical inference | Suited for statistical inference and hypothesis testing and for making generalization to the population | Less suited for statistical inference and hypothesis testing on the population |
| Application | Useful for quantitative research where generalizability is crucial | Commonly used in qualitative and exploratory research where in-depth insights are the goal |
Frequently asked questions
- What is multistage sampling ? Multistage sampling is a form of probability sampling approach that involves the progressive selection of samples in stages, going from larger clusters to a small number of participants, making it suited for large-scale research with enormous population lists.
- What are the methods of probability sampling? Probability sampling methods are simple random sampling, stratified random sampling, systematic sampling, cluster sampling, and multistage sampling.
- How to decide which type of sampling method to use? Choose a sampling method based on the goals, population, and resources. Probability for statistics and non-probability for efficiency or qualitative insights can be considered . Also, consider the population characteristics, size, and alignment with study objectives.
- What are the methods of non-probability sampling? Non-probability sampling methods are convenience sampling, consecutive sampling, purposive sampling, snowball sampling, and quota sampling.
- Why are sampling methods used in research? Sampling methods in research are employed to efficiently gather representative data from a subset of a larger population, enabling valid conclusions and generalizations while minimizing costs and time.
R Discovery is a literature search and research reading platform that accelerates your research discovery journey by keeping you updated on the latest, most relevant scholarly content. With 250M+ research articles sourced from trusted aggregators like CrossRef, Unpaywall, PubMed, PubMed Central, Open Alex and top publishing houses like Springer Nature, JAMA, IOP, Taylor & Francis, NEJM, BMJ, Karger, SAGE, Emerald Publishing and more, R Discovery puts a world of research at your fingertips.
Try R Discovery Prime FREE for 1 week or upgrade at just US$72 a year to access premium features that let you listen to research on the go, read in your language, collaborate with peers, auto sync with reference managers, and much more. Choose a simpler, smarter way to find and read research – Download the app and start your free 7-day trial today !
Related Posts

What are the Best Research Funding Sources

What are Experimental Groups in Research
Sampling Methods & Strategies 101
Everything you need to know (including examples)
By: Derek Jansen (MBA) | Expert Reviewed By: Kerryn Warren (PhD) | January 2023
If you’re new to research, sooner or later you’re bound to wander into the intimidating world of sampling methods and strategies. If you find yourself on this page, chances are you’re feeling a little overwhelmed or confused. Fear not – in this post we’ll unpack sampling in straightforward language , along with loads of examples .
Overview: Sampling Methods & Strategies
- What is sampling in a research context?
- The two overarching approaches
Simple random sampling
Stratified random sampling, cluster sampling, systematic sampling, purposive sampling, convenience sampling, snowball sampling.
- How to choose the right sampling method
What (exactly) is sampling?
At the simplest level, sampling (within a research context) is the process of selecting a subset of participants from a larger group . For example, if your research involved assessing US consumers’ perceptions about a particular brand of laundry detergent, you wouldn’t be able to collect data from every single person that uses laundry detergent (good luck with that!) – but you could potentially collect data from a smaller subset of this group.
In technical terms, the larger group is referred to as the population , and the subset (the group you’ll actually engage with in your research) is called the sample . Put another way, you can look at the population as a full cake and the sample as a single slice of that cake. In an ideal world, you’d want your sample to be perfectly representative of the population, as that would allow you to generalise your findings to the entire population. In other words, you’d want to cut a perfect cross-sectional slice of cake, such that the slice reflects every layer of the cake in perfect proportion.
Achieving a truly representative sample is, unfortunately, a little trickier than slicing a cake, as there are many practical challenges and obstacles to achieving this in a real-world setting. Thankfully though, you don’t always need to have a perfectly representative sample – it all depends on the specific research aims of each study – so don’t stress yourself out about that just yet!
With the concept of sampling broadly defined, let’s look at the different approaches to sampling to get a better understanding of what it all looks like in practice.

The two overarching sampling approaches
At the highest level, there are two approaches to sampling: probability sampling and non-probability sampling . Within each of these, there are a variety of sampling methods , which we’ll explore a little later.
Probability sampling involves selecting participants (or any unit of interest) on a statistically random basis , which is why it’s also called “random sampling”. In other words, the selection of each individual participant is based on a pre-determined process (not the discretion of the researcher). As a result, this approach achieves a random sample.
Probability-based sampling methods are most commonly used in quantitative research , especially when it’s important to achieve a representative sample that allows the researcher to generalise their findings.
Non-probability sampling , on the other hand, refers to sampling methods in which the selection of participants is not statistically random . In other words, the selection of individual participants is based on the discretion and judgment of the researcher, rather than on a pre-determined process.
Non-probability sampling methods are commonly used in qualitative research , where the richness and depth of the data are more important than the generalisability of the findings.
If that all sounds a little too conceptual and fluffy, don’t worry. Let’s take a look at some actual sampling methods to make it more tangible.
Need a helping hand?
Probability-based sampling methods
First, we’ll look at four common probability-based (random) sampling methods:
Importantly, this is not a comprehensive list of all the probability sampling methods – these are just four of the most common ones. So, if you’re interested in adopting a probability-based sampling approach, be sure to explore all the options.
Simple random sampling involves selecting participants in a completely random fashion , where each participant has an equal chance of being selected. Basically, this sampling method is the equivalent of pulling names out of a hat , except that you can do it digitally. For example, if you had a list of 500 people, you could use a random number generator to draw a list of 50 numbers (each number, reflecting a participant) and then use that dataset as your sample.
Thanks to its simplicity, simple random sampling is easy to implement , and as a consequence, is typically quite cheap and efficient . Given that the selection process is completely random, the results can be generalised fairly reliably. However, this also means it can hide the impact of large subgroups within the data, which can result in minority subgroups having little representation in the results – if any at all. To address this, one needs to take a slightly different approach, which we’ll look at next.
Stratified random sampling is similar to simple random sampling, but it kicks things up a notch. As the name suggests, stratified sampling involves selecting participants randomly , but from within certain pre-defined subgroups (i.e., strata) that share a common trait . For example, you might divide the population into strata based on gender, ethnicity, age range or level of education, and then select randomly from each group.
The benefit of this sampling method is that it gives you more control over the impact of large subgroups (strata) within the population. For example, if a population comprises 80% males and 20% females, you may want to “balance” this skew out by selecting a random sample from an equal number of males and females. This would, of course, reduce the representativeness of the sample, but it would allow you to identify differences between subgroups. So, depending on your research aims, the stratified approach could work well.

Next on the list is cluster sampling. As the name suggests, this sampling method involves sampling from naturally occurring, mutually exclusive clusters within a population – for example, area codes within a city or cities within a country. Once the clusters are defined, a set of clusters are randomly selected and then a set of participants are randomly selected from each cluster.
Now, you’re probably wondering, “how is cluster sampling different from stratified random sampling?”. Well, let’s look at the previous example where each cluster reflects an area code in a given city.
With cluster sampling, you would collect data from clusters of participants in a handful of area codes (let’s say 5 neighbourhoods). Conversely, with stratified random sampling, you would need to collect data from all over the city (i.e., many more neighbourhoods). You’d still achieve the same sample size either way (let’s say 200 people, for example), but with stratified sampling, you’d need to do a lot more running around, as participants would be scattered across a vast geographic area. As a result, cluster sampling is often the more practical and economical option.
If that all sounds a little mind-bending, you can use the following general rule of thumb. If a population is relatively homogeneous , cluster sampling will often be adequate. Conversely, if a population is quite heterogeneous (i.e., diverse), stratified sampling will generally be more appropriate.
The last probability sampling method we’ll look at is systematic sampling. This method simply involves selecting participants at a set interval , starting from a random point .
For example, if you have a list of students that reflects the population of a university, you could systematically sample that population by selecting participants at an interval of 8 . In other words, you would randomly select a starting point – let’s say student number 40 – followed by student 48, 56, 64, etc.
What’s important with systematic sampling is that the population list you select from needs to be randomly ordered . If there are underlying patterns in the list (for example, if the list is ordered by gender, IQ, age, etc.), this will result in a non-random sample, which would defeat the purpose of adopting this sampling method. Of course, you could safeguard against this by “shuffling” your population list using a random number generator or similar tool.

Non-probability-based sampling methods
Right, now that we’ve looked at a few probability-based sampling methods, let’s look at three non-probability methods :
Again, this is not an exhaustive list of all possible sampling methods, so be sure to explore further if you’re interested in adopting a non-probability sampling approach.
First up, we’ve got purposive sampling – also known as judgment , selective or subjective sampling. Again, the name provides some clues, as this method involves the researcher selecting participants using his or her own judgement , based on the purpose of the study (i.e., the research aims).
For example, suppose your research aims were to understand the perceptions of hyper-loyal customers of a particular retail store. In that case, you could use your judgement to engage with frequent shoppers, as well as rare or occasional shoppers, to understand what judgements drive the two behavioural extremes .
Purposive sampling is often used in studies where the aim is to gather information from a small population (especially rare or hard-to-find populations), as it allows the researcher to target specific individuals who have unique knowledge or experience . Naturally, this sampling method is quite prone to researcher bias and judgement error, and it’s unlikely to produce generalisable results, so it’s best suited to studies where the aim is to go deep rather than broad .

Next up, we have convenience sampling. As the name suggests, with this method, participants are selected based on their availability or accessibility . In other words, the sample is selected based on how convenient it is for the researcher to access it, as opposed to using a defined and objective process.
Naturally, convenience sampling provides a quick and easy way to gather data, as the sample is selected based on the individuals who are readily available or willing to participate. This makes it an attractive option if you’re particularly tight on resources and/or time. However, as you’d expect, this sampling method is unlikely to produce a representative sample and will of course be vulnerable to researcher bias , so it’s important to approach it with caution.
Last but not least, we have the snowball sampling method. This method relies on referrals from initial participants to recruit additional participants. In other words, the initial subjects form the first (small) snowball and each additional subject recruited through referral is added to the snowball, making it larger as it rolls along .
Snowball sampling is often used in research contexts where it’s difficult to identify and access a particular population. For example, people with a rare medical condition or members of an exclusive group. It can also be useful in cases where the research topic is sensitive or taboo and people are unlikely to open up unless they’re referred by someone they trust.
Simply put, snowball sampling is ideal for research that involves reaching hard-to-access populations . But, keep in mind that, once again, it’s a sampling method that’s highly prone to researcher bias and is unlikely to produce a representative sample. So, make sure that it aligns with your research aims and questions before adopting this method.
How to choose a sampling method
Now that we’ve looked at a few popular sampling methods (both probability and non-probability based), the obvious question is, “ how do I choose the right sampling method for my study?”. When selecting a sampling method for your research project, you’ll need to consider two important factors: your research aims and your resources .
As with all research design and methodology choices, your sampling approach needs to be guided by and aligned with your research aims, objectives and research questions – in other words, your golden thread. Specifically, you need to consider whether your research aims are primarily concerned with producing generalisable findings (in which case, you’ll likely opt for a probability-based sampling method) or with achieving rich , deep insights (in which case, a non-probability-based approach could be more practical). Typically, quantitative studies lean toward the former, while qualitative studies aim for the latter, so be sure to consider your broader methodology as well.
The second factor you need to consider is your resources and, more generally, the practical constraints at play. If, for example, you have easy, free access to a large sample at your workplace or university and a healthy budget to help you attract participants, that will open up multiple options in terms of sampling methods. Conversely, if you’re cash-strapped, short on time and don’t have unfettered access to your population of interest, you may be restricted to convenience or referral-based methods.
In short, be ready for trade-offs – you won’t always be able to utilise the “perfect” sampling method for your study, and that’s okay. Much like all the other methodological choices you’ll make as part of your study, you’ll often need to compromise and accept practical trade-offs when it comes to sampling. Don’t let this get you down though – as long as your sampling choice is well explained and justified, and the limitations of your approach are clearly articulated, you’ll be on the right track.

Let’s recap…
In this post, we’ve covered the basics of sampling within the context of a typical research project.
- Sampling refers to the process of defining a subgroup (sample) from the larger group of interest (population).
- The two overarching approaches to sampling are probability sampling (random) and non-probability sampling .
- Common probability-based sampling methods include simple random sampling, stratified random sampling, cluster sampling and systematic sampling.
- Common non-probability-based sampling methods include purposive sampling, convenience sampling and snowball sampling.
- When choosing a sampling method, you need to consider your research aims , objectives and questions, as well as your resources and other practical constraints .
If you’d like to see an example of a sampling strategy in action, be sure to check out our research methodology chapter sample .
Last but not least, if you need hands-on help with your sampling (or any other aspect of your research), take a look at our 1-on-1 coaching service , where we guide you through each step of the research process, at your own pace.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...

Excellent and helpful. Best site to get a full understanding of Research methodology. I’m nolonger as “clueless “..😉

Excellent and helpful for junior researcher!

Grad Coach tutorials are excellent – I recommend them to everyone doing research. I will be working with a sample of imprisoned women and now have a much clearer idea concerning sampling. Thank you to all at Grad Coach for generously sharing your expertise with students.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
- En español – ExME
- Em português – EME
What are sampling methods and how do you choose the best one?
Posted on 18th November 2020 by Mohamed Khalifa

This tutorial will introduce sampling methods and potential sampling errors to avoid when conducting medical research.
Introduction to sampling methods
Examples of different sampling methods, choosing the best sampling method.
It is important to understand why we sample the population; for example, studies are built to investigate the relationships between risk factors and disease. In other words, we want to find out if this is a true association, while still aiming for the minimum risk for errors such as: chance, bias or confounding .
However, it would not be feasible to experiment on the whole population, we would need to take a good sample and aim to reduce the risk of having errors by proper sampling technique.
What is a sampling frame?
A sampling frame is a record of the target population containing all participants of interest. In other words, it is a list from which we can extract a sample.
What makes a good sample?
A good sample should be a representative subset of the population we are interested in studying, therefore, with each participant having equal chance of being randomly selected into the study.
We could choose a sampling method based on whether we want to account for sampling bias; a random sampling method is often preferred over a non-random method for this reason. Random sampling examples include: simple, systematic, stratified, and cluster sampling. Non-random sampling methods are liable to bias, and common examples include: convenience, purposive, snowballing, and quota sampling. For the purposes of this blog we will be focusing on random sampling methods .
Example: We want to conduct an experimental trial in a small population such as: employees in a company, or students in a college. We include everyone in a list and use a random number generator to select the participants
Advantages: Generalisable results possible, random sampling, the sampling frame is the whole population, every participant has an equal probability of being selected
Disadvantages: Less precise than stratified method, less representative than the systematic method

Example: Every nth patient entering the out-patient clinic is selected and included in our sample
Advantages: More feasible than simple or stratified methods, sampling frame is not always required
Disadvantages: Generalisability may decrease if baseline characteristics repeat across every nth participant

Example: We have a big population (a city) and we want to ensure representativeness of all groups with a pre-determined characteristic such as: age groups, ethnic origin, and gender
Advantages: Inclusive of strata (subgroups), reliable and generalisable results
Disadvantages: Does not work well with multiple variables

Example: 10 schools have the same number of students across the county. We can randomly select 3 out of 10 schools as our clusters
Advantages: Readily doable with most budgets, does not require a sampling frame
Disadvantages: Results may not be reliable nor generalisable

How can you identify sampling errors?
Non-random selection increases the probability of sampling (selection) bias if the sample does not represent the population we want to study. We could avoid this by random sampling and ensuring representativeness of our sample with regards to sample size.
An inadequate sample size decreases the confidence in our results as we may think there is no significant difference when actually there is. This type two error results from having a small sample size, or from participants dropping out of the sample.
In medical research of disease, if we select people with certain diseases while strictly excluding participants with other co-morbidities, we run the risk of diagnostic purity bias where important sub-groups of the population are not represented.
Furthermore, measurement bias may occur during re-collection of risk factors by participants (recall bias) or assessment of outcome where people who live longer are associated with treatment success, when in fact people who died were not included in the sample or data analysis (survivors bias).
By following the steps below we could choose the best sampling method for our study in an orderly fashion.
Research objectiveness
Firstly, a refined research question and goal would help us define our population of interest. If our calculated sample size is small then it would be easier to get a random sample. If, however, the sample size is large, then we should check if our budget and resources can handle a random sampling method.
Sampling frame availability
Secondly, we need to check for availability of a sampling frame (Simple), if not, could we make a list of our own (Stratified). If neither option is possible, we could still use other random sampling methods, for instance, systematic or cluster sampling.
Study design
Moreover, we could consider the prevalence of the topic (exposure or outcome) in the population, and what would be the suitable study design. In addition, checking if our target population is widely varied in its baseline characteristics. For example, a population with large ethnic subgroups could best be studied using a stratified sampling method.
Random sampling
Finally, the best sampling method is always the one that could best answer our research question while also allowing for others to make use of our results (generalisability of results). When we cannot afford a random sampling method, we can always choose from the non-random sampling methods.
To sum up, we now understand that choosing between random or non-random sampling methods is multifactorial. We might often be tempted to choose a convenience sample from the start, but that would not only decrease precision of our results, and would make us miss out on producing research that is more robust and reliable.
References (pdf)

Mohamed Khalifa
Leave a reply cancel reply.
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
No Comments on What are sampling methods and how do you choose the best one?

Thank you for this overview. A concise approach for research.

really helps! am an ecology student preparing to write my lab report for sampling.

I learned a lot to the given presentation.. It’s very comprehensive… Thanks for sharing…

Very informative and useful for my study. Thank you

Oversimplified info on sampling methods. Probabilistic of the sampling and sampling of samples by chance does rest solely on the random methods. Factors such as the random visits or presentation of the potential participants at clinics or sites could be sufficiently random in nature and should be used for the sake of efficiency and feasibility. Nevertheless, this approach has to be taken only after careful thoughts. Representativeness of the study samples have to be checked at the end or during reporting by comparing it to the published larger studies or register of some kind in/from the local population.

Thank you so much Mr.mohamed very useful and informative article
Subscribe to our newsletter
You will receive our monthly newsletter and free access to Trip Premium.
Related Articles

How to read a funnel plot
This blog introduces you to funnel plots, guiding you through how to read them and what may cause them to look asymmetrical.

Internal and external validity: what are they and how do they differ?
Is this study valid? Can I trust this study’s methods and design? Can I apply the results of this study to other contexts? Learn more about internal and external validity in research to help you answer these questions when you next look at a paper.

Cluster Randomized Trials: Concepts
This blog summarizes the concepts of cluster randomization, and the logistical and statistical considerations while designing a cluster randomized controlled trial.
Sampling Methods in Research Methodology; How to Choose a Sampling Technique for Research
10 Pages Posted: 31 Jul 2018
Hamed Taherdoost
Hamta Group
Date Written: April 10, 2016
In order to answer the research questions, it is doubtful that researcher should be able to collect data from all cases. Thus, there is a need to select a sample. This paper presents the steps to go through to conduct sampling. Furthermore, as there are different types of sampling techniques/methods, researcher needs to understand the differences to select the proper sampling method for the research. In the regards, this paper also presents the different types of sampling techniques and methods.
Keywords: Sampling Method, Sampling Technique, Research Methodology, Probability Sampling, Non-Probability Sampling
Suggested Citation: Suggested Citation
Hamed Taherdoost (Contact Author)
Hamta group ( email ).
Vancouver Canada
Do you have a job opening that you would like to promote on SSRN?
Paper statistics, related ejournals, political behavior: voting & public opinion ejournal.
Subscribe to this fee journal for more curated articles on this topic
Sampling Methods In Reseach: Types, Techniques, & Examples
Saul McLeod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul McLeod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
Sampling methods in psychology refer to strategies used to select a subset of individuals (a sample) from a larger population, to study and draw inferences about the entire population. Common methods include random sampling, stratified sampling, cluster sampling, and convenience sampling. Proper sampling ensures representative, generalizable, and valid research results.
- Sampling : the process of selecting a representative group from the population under study.
- Target population : the total group of individuals from which the sample might be drawn.
- Sample: a subset of individuals selected from a larger population for study or investigation. Those included in the sample are termed “participants.”
- Generalizability : the ability to apply research findings from a sample to the broader target population, contingent on the sample being representative of that population.
For instance, if the advert for volunteers is published in the New York Times, this limits how much the study’s findings can be generalized to the whole population, because NYT readers may not represent the entire population in certain respects (e.g., politically, socio-economically).
The Purpose of Sampling
We are interested in learning about large groups of people with something in common in psychological research. We call the group interested in studying our “target population.”
In some types of research, the target population might be as broad as all humans. Still, in other types of research, the target population might be a smaller group, such as teenagers, preschool children, or people who misuse drugs.

Studying every person in a target population is more or less impossible. Hence, psychologists select a sample or sub-group of the population that is likely to be representative of the target population we are interested in.
This is important because we want to generalize from the sample to the target population. The more representative the sample, the more confident the researcher can be that the results can be generalized to the target population.
One of the problems that can occur when selecting a sample from a target population is sampling bias. Sampling bias refers to situations where the sample does not reflect the characteristics of the target population.
Many psychology studies have a biased sample because they have used an opportunity sample that comprises university students as their participants (e.g., Asch ).
OK, so you’ve thought up this brilliant psychological study and designed it perfectly. But who will you try it out on, and how will you select your participants?
There are various sampling methods. The one chosen will depend on a number of factors (such as time, money, etc.).

Random Sampling
Random sampling is a type of probability sampling where everyone in the entire target population has an equal chance of being selected.
This is similar to the national lottery. If the “population” is everyone who bought a lottery ticket, then everyone has an equal chance of winning the lottery (assuming they all have one ticket each).
Random samples require naming or numbering the target population and then using some raffle method to choose those to make up the sample. Random samples are the best method of selecting your sample from the population of interest.
- The advantages are that your sample should represent the target population and eliminate sampling bias.
- The disadvantage is that it is very difficult to achieve (i.e., time, effort, and money).
Stratified Sampling
During stratified sampling , the researcher identifies the different types of people that make up the target population and works out the proportions needed for the sample to be representative.
A list is made of each variable (e.g., IQ, gender, etc.) that might have an effect on the research. For example, if we are interested in the money spent on books by undergraduates, then the main subject studied may be an important variable.
For example, students studying English Literature may spend more money on books than engineering students, so if we use a large percentage of English students or engineering students, our results will not be accurate.
We have to determine the relative percentage of each group at a university, e.g., Engineering 10%, Social Sciences 15%, English 20%, Sciences 25%, Languages 10%, Law 5%, and Medicine 15%. The sample must then contain all these groups in the same proportion as the target population (university students).
- The disadvantage of stratified sampling is that gathering such a sample would be extremely time-consuming and difficult to do. This method is rarely used in Psychology.
- However, the advantage is that the sample should be highly representative of the target population, and therefore we can generalize from the results obtained.
Opportunity Sampling
Opportunity sampling is a method in which participants are chosen based on their ease of availability and proximity to the researcher, rather than using random or systematic criteria. It’s a type of convenience sampling .
An opportunity sample is obtained by asking members of the population of interest if they would participate in your research. An example would be selecting a sample of students from those coming out of the library.
- This is a quick and easy way of choosing participants (advantage)
- It may not provide a representative sample and could be biased (disadvantage).
Systematic Sampling
Systematic sampling is a method where every nth individual is selected from a list or sequence to form a sample, ensuring even and regular intervals between chosen subjects.
Participants are systematically selected (i.e., orderly/logical) from the target population, like every nth participant on a list of names.
To take a systematic sample, you list all the population members and then decide upon a sample you would like. By dividing the number of people in the population by the number of people you want in your sample, you get a number we will call n.
If you take every nth name, you will get a systematic sample of the correct size. If, for example, you wanted to sample 150 children from a school of 1,500, you would take every 10th name.
- The advantage of this method is that it should provide a representative sample.
Sample size
The sample size is a critical factor in determining the reliability and validity of a study’s findings. While increasing the sample size can enhance the generalizability of results, it’s also essential to balance practical considerations, such as resource constraints and diminishing returns from ever-larger samples.
Reliability and Validity
Reliability refers to the consistency and reproducibility of research findings across different occasions, researchers, or instruments. A small sample size may lead to inconsistent results due to increased susceptibility to random error or the influence of outliers. In contrast, a larger sample minimizes these errors, promoting more reliable results.
Validity pertains to the accuracy and truthfulness of research findings. For a study to be valid, it should accurately measure what it intends to do. A small, unrepresentative sample can compromise external validity, meaning the results don’t generalize well to the larger population. A larger sample captures more variability, ensuring that specific subgroups or anomalies don’t overly influence results.
Practical Considerations
Resource Constraints : Larger samples demand more time, money, and resources. Data collection becomes more extensive, data analysis more complex, and logistics more challenging.
Diminishing Returns : While increasing the sample size generally leads to improved accuracy and precision, there’s a point where adding more participants yields only marginal benefits. For instance, going from 50 to 500 participants might significantly boost a study’s robustness, but jumping from 10,000 to 10,500 might not offer a comparable advantage, especially considering the added costs.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
3.4 Sampling Techniques in Quantitative Research
Target population.
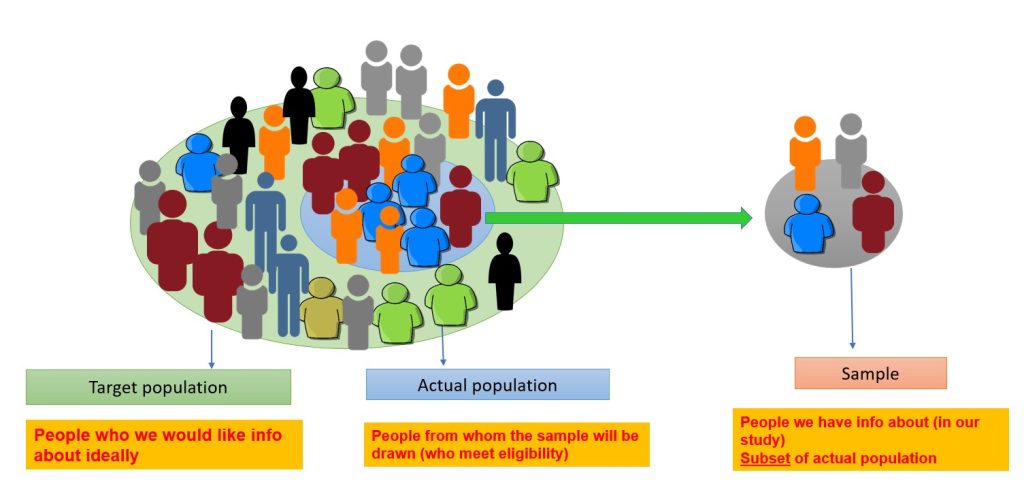
The target population includes the people the researcher is interested in conducting the research and generalizing the findings on. 40 For example, if certain researchers are interested in vaccine-preventable diseases in children five years and younger in Australia. The target population will be all children aged 0–5 years residing in Australia. The actual population is a subset of the target population from which the sample is drawn, e.g. children aged 0–5 years living in the capital cities in Australia. The sample is the people chosen for the study from the actual population (Figure 3.9). The sampling process involves choosing people, and it is distinct from the sample. 40 In quantitative research, the sample must accurately reflect the target population, be free from bias in terms of selection, and be large enough to validate or reject the study hypothesis with statistical confidence and minimise random error. 2
Sampling techniques
Sampling in quantitative research is a critical component that involves selecting a representative subset of individuals or cases from a larger population and often employs sampling techniques based on probability theory. 41 The goal of sampling is to obtain a sample that is large enough and representative of the target population. Examples of probability sampling techniques include simple random sampling, stratified random sampling, systematic random sampling and cluster sampling ( shown below ). 2 The key feature of probability techniques is that they involve randomization. There are two main characteristics of probability sampling. All individuals of a population are accessible to the researcher (theoretically), and there is an equal chance that each person in the population will be chosen to be part of the study sample. 41 While quantitative research often uses sampling techniques based on probability theory, some non-probability techniques may occasionally be utilised in healthcare research. 42 Non-probability sampling methods are commonly used in qualitative research. These include purposive, convenience, theoretical and snowballing and have been discussed in detail in chapter 4.
Sample size calculation
In order to enable comparisons with some level of established statistical confidence, quantitative research needs an acceptable sample size. 2 The sample size is the most crucial factor for reliability (reproducibility) in quantitative research. It is important for a study to be powered – the likelihood of identifying a difference if it exists in reality. 2 Small sample-sized studies are more likely to be underpowered, and results from small samples are more likely to be prone to random error. 2 The formula for sample size calculation varies with the study design and the research hypothesis. 2 There are numerous formulae for sample size calculations, but such details are beyond the scope of this book. For further readings, please consult the biostatistics textbook by Hirsch RP, 2021. 43 However, we will introduce a simple formula for calculating sample size for cross-sectional studies with prevalence as the outcome. 2
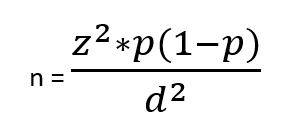
z is the statistical confidence; therefore, z = 1.96 translates to 95% confidence; z = 1.68 translates to 90% confidence
p = Expected prevalence (of health condition of interest)
d = Describes intended precision; d = 0.1 means that the estimate falls +/-10 percentage points of true prevalence with the considered confidence. (e.g. for a prevalence of 40% (0.4), if d=.1, then the estimate will fall between 30% and 50% (0.3 to 0.5).
Example: A district medical officer seeks to estimate the proportion of children in the district receiving appropriate childhood vaccinations. Assuming a simple random sample of a community is to be selected, how many children must be studied if the resulting estimate is to fall within 10% of the true proportion with 95% confidence? It is expected that approximately 50% of the children receive vaccinations
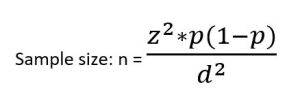
z = 1.96 (95% confidence)
d = 10% = 10/ 100 = 0.1 (estimate to fall within 10%)
p = 50% = 50/ 100 = 0.5
Now we can enter the values into the formula
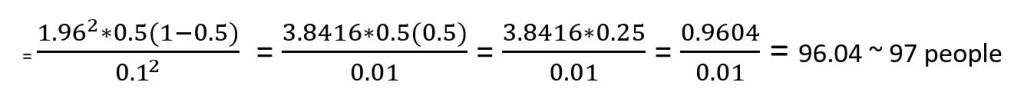
Given that people cannot be reported in decimal points, it is important to round up to the nearest whole number.
An Introduction to Research Methods for Undergraduate Health Profession Students Copyright © 2023 by Faith Alele and Bunmi Malau-Aduli is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License , except where otherwise noted.
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

The Sample and Sampling Techniques

Related Papers
Sandeep Kumar
Shevoni Wisidagama
Adv Bukhari
Achini Gunawardena
Morin J.-F., Olsson Ch., Atikcan E. (eds) , Research Methods in the Social Sciences: An A-Z of key concepts, Oxford, OUP
Emilie van Haute
Amandeep Shoker
okedare toyinbliss
SEEU Review
Aidin Salamzadeh
Collecting data using an appropriate sampling technique is a challenging task for a researcher to do. The researchers will be unable to collect data from all possible situations, which will preclude them from answering the study’s research questions in their current form. In light of the enormous number and variety of sampling techniques/methods available, the researcher must be knowledgeable about the differences to select the most appropriate sampling technique/method for the specific study under consideration. In this context, this study also looks into the basic concepts in probability sampling, kinds of probability sampling techniques with their advantages and disadvantages. Social science researchers will benefit from this study since it will assist them in choosing the most suitable probability sampling technique(s) for completing their research smoothly and successfully.
American Journal of Biomedical Science and Research
Kyu-Seong Kim
Mohsin Hassan Alvi
The Manual for Sampling Techniques used in Social Sciences is an effort to describe various types of sampling methodologies that are used in researches of social sciences in an easy and understandable way. Characteristics, benefits, crucial issues/ draw backs, and examples of each sampling type are provided separately.
Loading Preview
Sorry, preview is currently unavailable. You can download the paper by clicking the button above.
RELATED PAPERS
Net Journal of Social Sciences
joseph adekeye
Chiradee Francia
Rachel Irish Kozicki
christopher masebo
Andrea Weinberg
Biometrics & Biostatistics International Journal
Rufai Iliyasu
Manuela Gabor
Rajender Parsad
College Teaching
Deborah NOLAN
Dr. VISHAL VARIA
PIJUSH KHAN
Nydia Sánchez
Oxfam Research Guidelines
Martin Walsh
Nikki Laning
MSC Publishing Services
Murry C. Siyasiya
Moses Adeleke ADEOYE
Air Medical Journal
cheryl Thompson
Iyorter Anenge
Hu li za zhi The journal of nursing
Prof. Dr. İlker Etikan
Imran Ahmad Sajid
Journal of Health Specialties
Aamir Omair
Alliana Ulila
Advances in Business Information Systems and Analytics
SUDEEPTA PRADHAN
Colm O'Muircheartaigh
Sample Surveys: Design, Methods and Applications, Vol. 29A, Elsevier B.V.
Hagit Glickman
RELATED TOPICS
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
Click through the PLOS taxonomy to find articles in your field.
For more information about PLOS Subject Areas, click here .
Loading metrics
Open Access
Peer-reviewed
Research Article
Archaeology in space: The Sampling Quadrangle Assemblages Research Experiment (SQuARE) on the International Space Station. Report 1: Squares 03 and 05
Roles Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Supervision, Visualization, Writing – original draft, Writing – review & editing
* E-mail: [email protected]
Affiliations Department of Art, Chapman University, Orange, CA, United States of America, Space Engineering Research Center, University of Southern California, Marina del Rey, CA, United States of America
Roles Data curation, Formal analysis, Investigation, Methodology, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing
Affiliation Department of History, Carleton University, Ottawa, ON, United States of America
Roles Conceptualization, Data curation, Methodology, Project administration, Supervision, Writing – review & editing
Affiliation College of Humanities, Arts and Social Sciences, Flinders University, Adelaide, Australia
Roles Software, Writing – original draft
Roles Investigation, Writing – original draft
Affiliation Archaeology Research Center, University of Southern California, Los Angeles, CA, United States of America
- Justin St. P. Walsh,
- Shawn Graham,
- Alice C. Gorman,
- Chantal Brousseau,
- Salma Abdullah
- Published: August 7, 2024
- https://doi.org/10.1371/journal.pone.0304229
- Reader Comments
Between January and March 2022, crew aboard the International Space Station (ISS) performed the first archaeological fieldwork in space, the Sampling Quadrangle Assemblages Research Experiment (SQuARE). The experiment aimed to: (1) develop a new understanding of how humans adapt to life in an environmental context for which we are not evolutionarily adapted, using evidence from the observation of material culture; (2) identify disjunctions between planned and actual usage of facilities on a space station; (3) develop and test techniques that enable archaeological research at a distance; and (4) demonstrate the relevance of social science methods and perspectives for improving life in space. In this article, we describe our methodology, which involves a creative re-imagining of a long-standing sampling practice for the characterization of a site, the shovel test pit. The ISS crew marked out six sample locations (“squares”) around the ISS and documented them through daily photography over a 60-day period. Here we present the results from two of the six squares: an equipment maintenance area, and an area near exercise equipment and the latrine. Using the photographs and an innovative webtool, we identified 5,438 instances of items, labeling them by type and function. We then performed chronological analyses to determine how the documented areas were actually used. Our results show differences between intended and actual use, with storage the most common function of the maintenance area, and personal hygiene activities most common in an undesignated area near locations for exercise and waste.
Citation: Walsh JSP, Graham S, Gorman AC, Brousseau C, Abdullah S (2024) Archaeology in space: The Sampling Quadrangle Assemblages Research Experiment (SQuARE) on the International Space Station. Report 1: Squares 03 and 05. PLoS ONE 19(8): e0304229. https://doi.org/10.1371/journal.pone.0304229
Editor: Peter F. Biehl, University of California Santa Cruz, UNITED STATES OF AMERICA
Received: March 9, 2024; Accepted: May 7, 2024; Published: August 7, 2024
Copyright: © 2024 Walsh et al. This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Data Availability: All relevant data are within the paper and its Supporting Information files.
Funding: JW was the recipient of funding from Chapman University’s Office of Research and Sponsored Programs to support the activities of Axiom Space as implementation partner for the research presented in this article. There are no associated grant numbers for this financial support. Axiom Space served in the role of a contractor hired by Chapman University for the purpose of overseeing logistics relating to our research. In-kind support in the form of ISS crew time and access to the space station’s facilities, also awarded to JW from the ISS National Laboratory, resulted from an unsolicited proposal, and therefore there is no opportunity title or number associated with our work. No salary was received by any of the investigators as a result of the grant support. No additional external funding was received for this study.
Competing interests: The authors have declared that no competing interests exist.
Introduction
The International Space Station Archaeological Project (ISSAP) aims to fill a gap in social science investigation into the human experience of long-duration spaceflight [ 1 – 3 ]. As the largest, most intensively inhabited space station to date, with over 270 visitors from 23 countries during more than 23 years of continuous habitation, the International Space Station (ISS) is the ideal example of a new kind of spacefaring community—“a microsociety in a miniworld” [ 4 ]. While it is possible to interview crew members about their experiences, the value of an approach focused on material culture is that it allows identification of longer-term patterns of behaviors and associations that interlocutors are unable or even unwilling to articulate. In this respect, we are inspired by previous examples of contemporary archaeology such as the Tucson Garbage Project and the Undocumented Migration Project [ 5 – 7 ]. We also follow previous discussions of material culture in space contexts that highlight the social and cultural features of space technology [ 8 , 9 ].
Our primary goal is to identify how humans adapt to life in a new environment for which our species has not evolved, one characterized by isolation, confinement, and especially microgravity. Microgravity introduces opportunities, such as the ability to move and work in 360 degrees, and to carry out experiments impossible in full Earth gravity, but also limitations, as unrestrained objects float away. The most routine activities carried out on Earth become the focus of intense planning and technological intervention in microgravity. By extension, our project also seeks to develop archaeological techniques that permit the study of other habitats in remote, extreme, or dangerous environments [ 10 , 11 ]. Since it is too costly and difficult to visit our archaeological site in person, we have to creatively re-imagine traditional archaeological methods to answer key questions. To date, our team has studied crew-created visual displays [ 12 , 13 ], meanings and processes associated with items returned to Earth [ 14 ], distribution of different population groups around the various modules [ 15 ], and the development of machine learning (ML) computational techniques to extract data about people and places, all from historic photographs of life on the ISS [ 16 ].
From January to March 2022, we developed a new dataset through the first archaeological work conducted off-Earth. We documented material culture in six locations around the ISS habitat, using daily photography taken by the crew which we then annotated and studied as evidence for changes in archaeological assemblages of material culture over time. This was the first time such data had been captured in a way that allowed statistical analysis. Here, we present the data and results from Squares 03 and 05, the first two sample locations to be completed.
Materials and methods
Square concept and planning.
Gorman proposed the concept behind the investigation, deriving it from one of the most traditional terrestrial archaeological techniques, the shovel test pit. This method is used to understand the overall characteristics of a site quickly through sampling. A site is mapped with a grid of one-meter squares. Some of the squares are selected for initial excavation to understand the likely spatial and chronological distribution of features across the entire site. In effect, the technique is a way to sample a known percentage of the entire site systematically. In the ISS application of this method, we documented a notional stratigraphy through daily photography, rather than excavation.
Historic photography is a key dataset for the International Space Station Archaeological Project. Tens of thousands of images have been made available to us, either through publication [ 17 ], or through an arrangement with the ISS Research Integration Office, which supplied previously unpublished images from the first eight years of the station’s habitation. These photographs are informative about the relationships between people, places, and objects over time in the ISS. However, they were taken randomly (from an archaeological perspective) and released only according to NASA’s priorities and rules. Most significantly, they were not made with the purpose of answering archaeological questions. By contrast, the photographs taken during the present investigation were systematic, representative of a defined proportion of the habitat’s area, and targeted towards capturing archaeology’s primary evidence: material culture. We were interested in how objects move around individual spaces and the station, what these movements revealed about crew adherence to terrestrial planning, and the creative use of material culture to make the laboratory-like interior of the ISS more habitable.
Access to the field site was gained through approval of a proposal submitted to the Center for the Advancement of Science in Space (also known as the ISS National Laboratory [ISS NL]). Upon acceptance, Axiom Space was assigned as the Implementation Partner for carriage of the experiment according to standard procedure. No other permits were required for this work.
Experiment design
Since our work envisioned one-meter sample squares, and recognizing the use of acronyms as a persistent element of spacefaring culture, we named our payload the Sampling Quadrangle Assemblages Research Experiment (SQuARE). Permission from the ISS NL to conduct SQuARE was contingent on using equipment that was already on board the space station. SQuARE required only five items: a camera, a wide-angle lens, adhesive tape (for marking the boundaries of the sample locations), a ruler (for scale), and a color calibration card (for post-processing of the images). All of these were already present on the ISS.
Walsh performed tests on the walls of a terrestrial art gallery to assess the feasibility of creating perfect one-meter squares in microgravity. He worked on a vertical surface, using the Pythagorean theorem to determine where the corners should be located. The only additional items used for these tests were two metric measuring tapes and a pencil for marking the wall (these were also already on the ISS). While it was possible to make a square this way, it also became clear that at least two people were needed to manage holding the tape measures in position while marking the points for the corners. This was not possible in the ISS context.
Walsh and Gorman identified seven locations for the placement of squares. Five of these were in the US Orbital Segment (USOS, consisting of American, European, and Japanese modules) and two in the Russian Orbital Segment. Unfortunately, tense relations between the US and Russian governments meant we could only document areas in the USOS. The five locations were (with their SQuARE designations):
- 01—an experimental rack on the forward wall, starboard end, of the Japanese Experiment Module
- 02—an experimental rack on the forward wall, port end, of the European laboratory module Columbus
- 03—the starboard Maintenance Work Area (workstation) in the US Node 2 module
- 04—the wall area “above” (according to typical crew body orientation) the galley table in the US Node 1 module
- 05—the aft wall, center location, of the US Node 3 module
Our square selection encompassed different modules and activities, including work and leisure. We also asked the crew to select a sixth sample location based on their understanding of the experiment and what they thought would be interesting to document. They chose a workstation on the port wall of the US laboratory module, at the aft end, which they described in a debriefing following their return to Earth in June 2022 as “our central command post, like our shared office situation in the lab.” Results from the four squares not included here will appear in future publications.
Walsh worked with NASA staff to determine payload procedures, including precise locations for the placement of the tape that would mark the square boundaries. The squares could not obstruct other facilities or experiments, so (unlike in terrestrial excavations, where string is typically used to demarcate trench boundaries) only the corners of each square were marked, not the entire perimeter. We used Kapton tape due to its bright yellow-orange color, which aided visibility for the crew taking photographs and for us when cropping the images. In practice, due to space constraints, the procedures that could actually be performed by crew in the ISS context, and the need to avoid interfering with other ongoing experiments, none of the locations actually measured one square meter or had precise 90° corners like a trench on Earth.
On January 14, 2022, NASA astronaut Kayla Barron set up the sample locations, marking the beginning of archaeological work in space ( S1 Movie ). For 30 days, starting on January 21, a crew member took photos of the sample locations at approximately the same time each day; the process was repeated at a random time each day for a second 30-day period to eliminate biases. Photography ended on March 21, 2022. The crew were instructed not to move any items prior to taking the photographs. Walsh led image management, including color and barrel distortion correction, fixing the alignment of each image, and cropping them to the boundaries of the taped corners.
Data processing—Item tagging, statistics, visualizations
We refer to each day’s photo as a “context” by analogy with chronologically-linked assemblages of artifacts and installations at terrestrial archaeological sites ( S1 and S2 Datasets). As previously noted, each context represented a moment roughly 24 hours distant from the previous one, showing evidence of changes in that time. ISS mission planners attempted to schedule the activity at the same time in the first month, but there were inevitable changes due to contingencies. Remarkably, the average time between contexts in Phase 1 was an almost-perfect 24h 0m 13s. Most of the Phase 1 photos were taken between 1200 and 1300 GMT (the time zone in which life on the ISS is organized). In Phase 2, the times were much more variable, but the average time between contexts during this period was still 23h 31m 45s. The earliest Phase 2 photo was taken at 0815 GMT, and the latest at 2101. We did not identify any meaningful differences between results from the two phases.
Since the “test pits” were formed of images rather than soil matrices, we needed a tool to capture information about the identity, nature, and location of every object. An open-source image annotator platform [ 18 ] mostly suited our needs. Brousseau rebuilt the platform to work within the constraints of our access to the imagery (turning it into a desktop tool with secure access to our private server), to permit a greater range of metadata to be added to each item or be imported, to autosave, and to export the resulting annotations. The tool also had to respect privacy and security limitations required by NASA.
The platform Brousseau developed and iterated was rechristened “Rocket-Anno” ( S1 File ). For each context photograph, the user draws an outline around every object, creating a polygon; each polygon is assigned a unique ID and the user provides the relevant descriptive information, using a controlled vocabulary developed for ISS material culture by Walsh and Gorman. Walsh and Abdullah used Rocket-Anno to tag the items in each context for Squares 03 and 05. Once all the objects were outlined for every context’s photograph, the tool exported a JSON file with all of the metadata for both the images themselves and all of the annotations, including the coordinate points for every polygon ( S3 Dataset ). We then developed Python code using Jupyter “notebooks” (an interactive development environment) that ingests the JSON file and generates dataframes for various facets of the data. Graham created a “core” notebook that exports summary statistics, calculates Brainerd-Robinson coefficients of similarity, and visualizes the changing use of the square over time by indicating use-areas based on artifact types and subtypes ( S2 File ). Walsh and Abdullah also wrote detailed square notes with context-by-context discussions and interpretations of features and patterns.
We asked NASA for access to the ISS Crew Planner, a computer system that shows each astronaut’s tasks in five-minute increments, to aid with our interpretation of contexts, but were denied. As a proxy, we use another, less detailed source: the ISS Daily Summary Reports (DSRs), published on a semi-regular basis by NASA on its website [ 19 ]. Any activities mentioned in the DSRs often must be connected with a context by inference. Therefore, our conclusions are likely less precise than if we had seen the Crew Planner, but they also more clearly represent the result of simply observing and interpreting the material culture record.
The crew during our sample period formed ISS Expedition 66 (October 2021-March 2022). They were responsible for the movement of objects in the sample squares as they carried out their daily tasks. The group consisted of two Russians affiliated with Roscosmos (the Russian space agency, 26%), one German belonging to the European Space Agency (ESA, 14%), and four Americans employed by NASA (57%). There were six men (86%) and one woman (14%), approximately equivalent to the historic proportions in the ISS population (84% and 16%, respectively). The Russian crew had their sleeping quarters at the aft end of the station, in the Zvezda module. The ESA astronaut slept in the European Columbus laboratory module. The four NASA crew slept in the US Node 2 module (see below). These arrangements emphasize the national character of discrete spaces around the ISS, also evident in our previous study of population distributions [ 15 ]. Both of the sample areas in this study were located in US modules.
Square 03 was placed in the starboard Maintenance Work Area (MWA, Fig 1 ), one of a pair of workstations located opposite one another in the center of the Node 2 module, with four crew berths towards the aft and a series of five ports for the docking of visiting crew/cargo vehicles and two modules on the forward end ( Fig 2 ). Node 2 (sometimes called “Harmony”) is a connector that links the US, Japanese, and European lab modules. According to prevailing design standards when the workstation was developed, an MWA “shall serve as the primary location for servicing and repair of maximum sized replacement unit/system components” [ 20 ]. Historic images published by NASA showing its use suggested that its primary function was maintenance of equipment and also scientific work that did not require a specific facility such as a centrifuge or furnace.
- PPT PowerPoint slide
- PNG larger image
- TIFF original image
An open crew berth is visible at right. The yellow dotted line indicates the boundaries of the sample area. Credit: NASA/ISSAP.
https://doi.org/10.1371/journal.pone.0304229.g001
Credit: Tor Finseth, by permission, modified by Justin Walsh.
https://doi.org/10.1371/journal.pone.0304229.g002
Square 03 measured 90.3 cm (top) x 87.8 (left) x 89.4 (bottom) x 87.6 (right), for an area of approximately 0.79 m 2 . Its primary feature was a blue metal panel with 40 square loop-type Velcro patches arranged in four rows of ten. During daily photography, many items were attached to the Velcro patches (or held by a clip or in a resealable bag which had its own hook-type Velcro). Above and below the blue panel were additional Velcro patches placed directly on the white plastic wall surface. These patches were white, in different sizes and shapes and irregularly arranged, indicating that they had been placed on the wall in response to different needs. Some were dirty, indicating long use. The patches below the blue panel were rarely used during the sample period, but the patches above were used frequently to hold packages of wet wipes, as well as resealable bags with electrostatic dispersion kits and other items. Outside the sample area, the primary features were a crew berth to the right, and a blue metal table attached to the wall below. This table, the primary component of the MWA, “provides a rigid surface on which to perform maintenance tasks,” according to NASA [ 21 ]. It is modular and can be oriented in several configurations, from flat against the wall to horizontal ( i . e ., perpendicular to the wall). A laptop to the left of the square occasionally showed information about work happening in the area.
In the 60 context photos of Square 03, we recorded 3,608 instances of items, an average of 60.1 (median = 60.5) per context. The lowest count was 24 in context 2 (where most of the wall was hidden from view behind an opaque storage bag), and the highest was 75 in both contexts 20 and 21. For comparison between squares, we can also calculate the item densities per m 2 . The average count was 76.1/m 2 (minimum = 30, maximum = 95). The count per context ( Fig 3(A)) began much lower than average in the first three contexts because of a portable glovebag and a stowage bag that obscured much of the sample square. It rose to an above-average level which was sustained (with the exception of contexts 11 and 12, which involved the appearance of another portable glovebag) until about context 43, when the count dipped again and the area seemed to show less use. Contexts 42–59 showed below-average numbers, as much as 20% lower than previously.
(a) Count of artifacts in Square 03 over time. (b) Proportions of artifacts by function in Square 03. Credit: Rao Hamza Ali.
https://doi.org/10.1371/journal.pone.0304229.g003
74 types of items appeared at least once here, belonging to six categories: equipment (41%), office supplies (31%), electronic (17%), stowage (9%), media (1%), and food (<1%). To better understand the significance of various items in the archaeological record, we assigned them to functional categories ( Table 1 , Fig 3(B)) . 35% of artifacts were restraints, or items used for holding other things in place; 12% for tools; 9% for containers; 9% for writing items; 6% for audiovisual items; 6% for experimental items; 4% for lights; 4% for safety items; 4% for body maintenance; 4% for power items; 3% for computing items; 1% for labels; and less than 1% drinks. We could not identify a function for two percent of the items.
https://doi.org/10.1371/journal.pone.0304229.t001
One of the project goals is understanding cultural adaptations to the microgravity environment. We placed special attention on “gravity surrogates,” pieces of (often simple) technology that are used in space to replicate the terrestrial experience of things staying where they are placed. Gravity surrogates include restraints and containers. It is quite noticeable that gravity surrogates comprise close to half of all items (44%) in Square 03, while the tools category, which might have been expected to be most prominent in an area designated for maintenance, is less than one-third as large (12%). Adding other groups associated with work, such as “experiment” and “light,” only brings the total to 22%.
Square 05 (Figs 2 and 4 ) was placed in a central location on the aft wall of the multipurpose Node 3 (“Tranquility”) module. This module does not include any specific science facilities. Instead, there are two large pieces of exercise equipment, the TVIS (Treadmill with Vibration Isolation Stabilization System, on the forward wall at the starboard end), and the ARED (Advanced Resistive Exercise Device, on the overhead wall at the port end). Use of the machines forms a significant part of crew activities, as they are required to exercise for two hours each day to counteract loss of muscle mass and bone density, and enable readjustment to terrestrial gravity on their return. The Waste and Hygiene Compartment (WHC), which includes the USOS latrine, is also here, on the forward wall in the center of the module, opposite Square 05. Finally, three modules are docked at Node 3’s port end. Most notable is the Cupola, a kind of miniature module on the nadir side with a panoramic window looking at Earth. This is the most popular leisure space for the crew, who often describe the hours they spend there. The Permanent Multipurpose Module (PMM) is docked on the forward side, storing equipment, food, and trash. In previous expeditions, some crew described installing a curtain in the PMM to create a private space for changing clothes and performing body maintenance activities such as cleaning oneself [ 22 , 23 ], but it was unclear whether that continued to be its function during the expedition we observed. One crew member during our sample period posted a video on Instagram showing the PMM interior and their efforts to re-stow equipment in a bag [ 24 ]. The last space attached to Node 3 is an experimental inflatable module docked on the aft side, called the Bigelow Expandable Activity Module (BEAM), which is used for storage of equipment.
The yellow dotted line indicates the boundaries of the sample area. The ARED machine is at the far upper right, on the overhead wall. The TVIS treadmill is outside this image to the left, on the forward wall. The WHC is directly behind the photographer. Credit: NASA/ISSAP.
https://doi.org/10.1371/journal.pone.0304229.g004
Square 05 was on a mostly featureless wall, with a vertical handrail in the middle. Handrails are metal bars located throughout the ISS that are used by the crew to hold themselves in place or provide a point from which to propel oneself to another location. NASA’s most recent design standards acknowledge that “[t]hey also serve as convenient locations for temporary mounting, affixing, or restraint of loose equipment and as attachment points for equipment” [ 25 ]. The handrail in Square 05 was used as an impromptu object restraint when a resealable bag filled with other bags was squeezed between the handrail and the wall.
The Brine Processing Assembly (BPA), a white plastic box which separates water from other components of urine for treatment and re-introduction to the station’s drinkable water supply [ 26 ], was fixed to the wall outside the square boundaries at lower left. A bungee cord was attached to both sides of the box; the one on the right was connected at its other end to the handrail attachment bracket. Numerous items were attached to or wedged into this bungee cord during the survey, bringing “gravity” into being. A red plastic duct ran through the square from top center into the BPA. This duct led from the latrine via the overhead wall. About halfway through the survey period, in context 32, the duct was wrapped in Kapton tape. According to the DSR for that day, “the crew used duct tape [ sic ] to make a seal around the BPA exhaust to prevent odor permeation in the cabin” [ 27 ], revealing an aspect of the crew’s experience of this area that is captured only indirectly in the context photograph. Permanently attached to the wall were approximately 20 loop-type Velcro patches in many shapes and sizes, placed in a seemingly random pattern that likely indicates that they were put there at different times and for different reasons.
Other common items in Square 05 were a mirror, a laptop computer, and an experimental item belonging to the German space agency DLR called the Touch Array Assembly [ 28 ]. The laptop moved just three times, and only by a few centimeters each time, during the sample period. The Touch Array was a black frame enclosing three metal surfaces which were being tested for their bacterial resistance; members of the crew touched the surfaces at various moments during the sample period. Finally, and most prominent due to its size, frequency of appearance, and use (judged by its movement between context photos) was an unidentified crew member’s toiletry kit.
By contrast with Square 03, 05 was the most irregular sample location, roughly twice as wide as it was tall. Its dimensions were 111 cm (top) x 61.9 (left) x 111.4 (bottom) x 64.6 (right), for an area of approximately 0.7 m 2 , about 89% of Square 03. We identified 1,830 instances of items in the 60 contexts, an average of 30.5 (median = 32) per context. The minimum was 18 items in context 5, and the maximum was 39 in contexts 24, 51, and 52. The average item density was 43.6/m 2 (minimum = 26, maximum = 56), 57% of Square 03.
The number of items trended upward throughout the sample period ( Fig 5(A)) . The largest spike occurred in context 6 with the appearance of the toiletry kit, which stored (and revealed) a number of related items. The kit can also be linked to one of the largest dips in item count, seen from contexts 52 to 53, when it was closed (but remained in the square). Other major changes can often be attributed to the addition and removal of bungee cords, which had other items such as carabiners and brackets attached. For example, the dip seen in context 25 correlates with the removal of a bungee cord with four carabiners.
(a) Count of artifacts and average count in Square 05 over time. (b) Proportions of artifacts by function in Square 05. Credit: Rao Hamza Ali.
https://doi.org/10.1371/journal.pone.0304229.g005
41 different item types were found in Square 05, about 55% as many as in Square 03. These belonged to five different categories: equipment (63%), electronic (17%), stowage (10%), office supplies (5%), and food (2%). The distribution of function proportions was quite different in this sample location ( Table 2 and Fig 5(B)) . Even though restraints were still most prominent, making up 32% of all items, body maintenance was almost as high (30%), indicating how strongly this area was associated with the activity of cleaning and caring for oneself. Computing (8%, represented by the laptop, which seems not to have been used), power (8%, from various cables), container (7%, resealable bags and Cargo Transfer Bags), and hygiene (6%, primarily the BPA duct) were the next most common items. Experiment was the function of 4% of the items, mostly the Touch Array, which appeared in every context, followed by drink (2%) and life support (1%). Safety, audiovisual, food, and light each made up less than 1% of the functional categories.
https://doi.org/10.1371/journal.pone.0304229.t002
Tracking changes over time is critical to understanding the activity happening in each area. We now explore how the assemblages change by calculating the Brainerd-Robinson Coefficient of Similarity [ 29 , 30 ] as operationalized by Peeples [ 31 , 32 ]. This metric is used in archaeology for comparing all pairs of the contexts by the proportions of categorical artifact data, here functional type. Applying the coefficient to the SQuARE contexts enables identification of time periods for distinct activities using artifact function and frequency alone, independent of documentary or oral evidence.
Multiple phases of activities took place in the square. Moments of connected activity are visible as red clusters in contexts 0–2, 11–12, 28–32, and 41 ( Fig 6(A)) . Combining this visualization with close observation of the photos themselves, we argue that there are actually eight distinct chronological periods.
- Contexts 0–2: Period 1 (S1 Fig in S3 File ) is a three-day period of work involving a portable glovebag (contexts 0–1) and a large blue stowage bag (context 2). It is difficult to describe trends in functional types because the glovebag and stowage bag obstruct the view of many objects. Items which appear at the top of the sample area, such as audiovisual and body maintenance items, are overemphasized in the data as a result. It appears that some kind of science is happening here, perhaps medical sample collection due to the presence of several small resealable bags visible in the glovebag. The work appears particularly intense in context 1, with the positioning of the video camera and light to point into the glovebag. These items indicate observation and oversight of crew activities by ground control. A white cargo transfer bag for storage and the stowage bag for holding packing materials in the context 2 photo likely relate to the packing of a Cargo Dragon vehicle that was docked to Node 2. The Dragon departed from the ISS for Earth, full of scientific samples, equipment, and crew personal items, a little more than three hours after the context 2 photo was taken [ 33 ].
- Contexts 3–10: Period 2 (S2 Fig in S3 File ) was a “stable” eight-day period in the sample, when little activity is apparent, few objects were moved or transferred in or out the square, and the primary function of the area seems to be storage rather than work. In context 6, a large Post-It notepad appeared in the center of the metal panel with a phone number written on it. This number belonged to another astronaut, presumably indicating that someone on the ISS had been told to call that colleague on the ground (for reasons of privacy, and in accordance with NASA rules for disseminating imagery, we have blurred the number in the relevant images). In context 8, the same notepad sheet had new writing appear on it, this time reading “COL A1 L1,” the location of an experimental rack in the European lab module.
- Contexts 11–12: Period 3 (S3 Fig in S3 File ) involves a second appearance of a portable glovebag (a different one from that used in contexts 0–1, according to its serial number), this time for a known activity, a concrete hardening experiment belonging to the European Space Agency [ 34 , 35 ]. This two-day phase indicates how the MWA space can be shared with non-US agencies when required. It also demonstrates the utility of this flexible area for work beyond biology/medicine, such as material science. Oversight of the crew’s activities by ground staff is evident from the positioning of the video camera and LED light pointing into the glovebag.
- Contexts 13–27: Period 4 (S4 Fig in S3 File ) is another stable fifteen-day period, similar to Period 2. Many items continued to be stored on the aluminum panel. The LED light’s presence is a trace of the activity in Period 3 that persists throughout this phase. Only in context 25 can a movement of the lamp potentially be connected to an activity relating to one of the stored items on the wall: at least one nitrile glove was removed from a resealable bag behind the lamp. In general, the primary identifiable activity during Period 4 is storage.
- Contexts 28–32: Period 5 (S5 Fig in S3 File ), by contrast, represents a short period of five days of relatively high and diverse activity. In context 28, a Microsoft Hololens augmented reality headset appeared. According to the DSR for the previous day, a training activity called Sidekick was carried out using the headset [ 36 ]. The following day, a Saturday, showed no change in the quantity or type of objects, but many were moved around and grouped by function—adhesive tape rolls were placed together, tools were moved from Velcro patches into pouches or straightened, and writing implements were placed in a vertical orientation when previously they were tilted. Context 29 represents a cleaning and re-organization of the sample area, which is a common activity for the crew on Saturdays [ 37 ]. Finally, in context 32, an optical coherence tomography scanner—a large piece of equipment for medical research involving crew members’ eyes—appeared [ 38 ]. This device was used previously during the sample period, but on the same day as the ESA concrete experiment, so that earlier work seems to have happened elsewhere [ 39 ].
- Contexts 33–40: Period 6 (S6 Fig in S3 File ) is the third stable period, in which almost no changes are visible over eight days. The only sign of activity is a digital timer which was started six hours before the context 39 image was made and continued to run at least through context 42.
- Context 41: Period 7 (S7 Fig in S3 File ) is a single context in which medical sample collection may have occurred. Resealable bags (some holding others) appeared in the center of the image and at lower right. One of the bags at lower right had a printed label reading “Reservoir Containers.” We were not able to discern which type of reservoir containers the label refers to, although the DSR for the day mentions “[Human Research Facility] Generic Saliva Collection,” without stating the location for this work [ 40 ]. Evidence from photos of other squares shows that labeled bags could be re-used for other purposes, so our interpretation of medical activity for this context is not conclusive.
- Contexts 42–60: Period 8 (S8 Fig in S3 File ) is the last and longest period of stability and low activity—eighteen days in which no specific activity other than the storage of items can be detected. The most notable change is the appearance for the first time of a foil water pouch in the central part of the blue panel.
Visualization of Brainerd-Robinson similarity, compared context-by-context by item function, for (a) Square 03 and (b) Square 05. The more alike a pair of contexts is, the higher the coefficient value, with a context compared against itself where a value of 200 equals perfect similarity. The resulting matrix of coefficients is visualized on a scale from blue to red where blue is lowest and red is highest similarity. The dark red diagonal line indicates complete similarity, where each context is compared to itself. Dark blue represents a complete difference. Credit: Shawn Graham.
https://doi.org/10.1371/journal.pone.0304229.g006
In the standards used at the time of installation, “stowage space” was the sixth design requirement listed for the MWA after accessibility; equipment size capability; scratch-resistant surfaces; capabilities for electrical, mechanical, vacuum, and fluid support during maintenance; and the accommodation of diagnostic equipment [ 20 ]. Only capabilities for fabrication were listed lower than stowage. Yet 50 of the 60 contexts (83%) fell within stable periods where little or no activity is identifiable in Square 03. According to the sample results, therefore, this area seems to exist not for “maintenance,” but primarily for the storage and arrangement of items. The most recent update of the design standards does not mention the MWA, but states, “Stowage location of tool kits should be optimized for accessibility to workstations and/or maintenance workbenches” [ 25 ]. Our observation confirms the importance of this suggestion.
The MWA was also a flexible location for certain science work, like the concrete study or crew health monitoring. Actual maintenance of equipment was hardly in evidence in the sample (possibly contexts 25, 39, and 44), and may not even have happened at all in this location. Some training did happen here, such as review of procedures for the Electromagnetic Levitator camera (instructions for changing settings on a high-speed camera appeared on the laptop screen; the day’s DSR shows that this camera is part of the Electromagnetic Levitator facility, located in the Columbus module [ 41 ]. The training required the use of the Hololens system (context 28 DSR, cited above).
Although many item types were represented in Square 03, it became clear during data capture how many things were basically static, unmoving and therefore unused, especially certain tools, writing implements, and body maintenance items. The MWA was seen as an appropriate place to store these items. It may be the case that their presence here also indicates that their function was seen as an appropriate one for this space, but the function(s) may not be carried out—or perhaps not in this location. Actualization of object function was only visible to us when the state of the item changed—it appeared, it moved, it changed orientation, it disappeared, or, in the case of artifacts that were grouped in collections rather than found as singletons, its shape changed or it became visibly smaller/lesser. We therefore have the opportunity to explore not only actuality of object use, but also potentiality of use or function, and the meaning of that quality for archaeological interpretation [ 42 , 43 ]. This possibility is particularly intriguing in light of the archaeological turn towards recognizing the agency of objects to impact human activity [ 44 , 45 ]. We will explore these implications in a future publication.
We performed the same chronological analysis for Square 05. Fig 6(B) represents the analysis for both item types and for item functions. We identified three major phases of activity, corresponding to contexts 0–5, 6–52, and 53–59 (S9-S11 Figs in S3 File ). The primary characteristics of these phases relate to an early period of unclear associations (0–5) marked by the presence of rolls of adhesive tape and a few body maintenance items (toothpaste and toothbrush, wet wipes); the appearance of a toiletry kit on the right side of the sample area, fully open with clear views of many of the items contained within (6–52); and finally, the closure of the toiletry kit so that its contents can no longer be seen (53–59). We interpret the phases as follows:
- Contexts 0–5: In Period 1 (six days, S9 Fig in S3 File ), while items such as a mirror, dental floss picks, wet wipes, and a toothbrush held in the end of a toothpaste tube were visible, the presence of various other kinds of items confounds easy interpretation. Two rolls of duct tape were stored on the handrail in the center of the sample area, and the Touch Array and laptop appeared in the center. Little movement can be identified, apart from a blue nitrile glove that appeared in context 1 and moved left across the area until it was wedged into the bungee cord for contexts 3 and 4. The tape rolls were removed prior to context 5. A collection of resealable bags was wedged behind the handrail in context 3, remaining there until context 9. Overall, this appears to be a period characterized by eclectic associations, showing an area without a clear designated function.
- Contexts 6–52: Period 2 (S10 Fig in S3 File ) is clearly the most significant one for this location due to its duration (47 days). It was dominated by the number of body maintenance items located in and around the toiletry kit, especially a white hand towel (on which a brown stain was visible from context 11, allowing us to confirm that the same towel was present until context 46). A second towel appeared alongside the toiletry kit in context 47, and the first one was fixed at the same time to the handrail, where it remained through the end of the sample period. A third towel appeared in context 52, attached to the handrail together with the first one by a bungee cord, continuing to the end of the sample period. Individual body maintenance items moved frequently from one context to the next, showing the importance of this type of activity for this part of Node 3. For reasons that are unclear, the mirror shifted orientation from vertical to diagonal in context 22, and then was put back in a vertical orientation in context 31 (a Monday, a day which is not traditionally associated with cleaning and organization). Collections of resealable bags appeared at various times, including a large one labeled “KYNAR BAG OF ZIPLOCKS” in green marker at the upper left part of the sample area beginning of context 12 (Kynar is a non-flammable plastic material that NASA prefers for resealable bags to the generic commercial off-the-shelf variety because it is non-flammable; however, its resistance to heat makes it less desirable for creating custom sizes, so bags made from traditional but flammable low-density polyethylene still dominate on the ISS [ 14 ]). The Kynar bag contained varying numbers of bags within it over time; occasionally, it appeared to be empty. The Touch Array changed orientation on seven of 47 days in period 2, or 15% of the time (12% of all days in the survey), showing activity associated with scientific research in this area. In context 49, a life-support item, the Airborne Particulate Monitor (APM) was installed [ 46 ]. This device, which measures “real-time particulate data” to assess hazards to crew health [ 47 ], persisted through the end of the sample period.
- Contexts 53–59: Period 3 (S11 Fig in S3 File ) appears as a seven-day phase marked by low activity. Visually, the most notable feature is the closure of the toiletry kit, which led to much lower counts of body maintenance items. Hardly any of the items on the wall moved at all during this period.
While body maintenance in the form of cleaning and caring for oneself could be an expected function for an area with exercise and excretion facilities, it is worth noting that the ISS provides, at most, minimal accommodation for this activity. A description of the WHC stated, “To provide privacy…an enclosure was added to the front of the rack. This enclosure, referred to as the Cabin, is approximately the size of a typical bathroom stall and provides room for system consumables and hygiene item stowage. Space is available to also support limited hygiene functions such as hand and body washing” [ 48 ]. A diagram of the WHC in the same publication shows the Cabin without a scale but suggests that it measures roughly 2 m (h) x .75 (w) x .75 (d), a volume of approximately 1.125 m 3 . NASA’s current design standards state that the body volume of a 95th percentile male astronaut is 0.99 m 3 [ 20 ], meaning that a person of that size would take up 88% of the space of the Cabin, leaving little room for performing cleaning functions—especially if the Cabin is used as apparently intended, to also hold “system consumables and hygiene item[s]” that would further diminish the usable volume. This situation explains why crews try to adapt other spaces, such as storage areas like the PMM, for these activities instead. According to the crew debriefing statement, only one of them used the WHC for body maintenance purposes; it is not clear whether the toiletry kit belonged to that individual. But the appearance of the toiletry kit in Square 05—outside of the WHC, in a public space where others frequently pass by—may have been a response to the limitations of the WHC Cabin. It suggests a need for designers to re-evaluate affordances for body maintenance practices and storage for related items.
Although Square 03 and 05 were different sizes and shapes, comparing the density of items by function shows evidence of their usage ( Table 3 ). The typical context in Square 03 had twice as many restraints and containers, but less than one-quarter as many body maintenance items as Square 05. 03 also had many tools, lights, audiovisual equipment, and writing implements, while there were none of any of these types in 05. 05 had life support and hygiene items which were missing from 03. It appears that flexibility and multifunctionality were key elements for 03, while in 05 there was emphasis on one primary function (albeit an improvised one, designated by the crew rather than architects or ground control), cleaning and caring for one’s body, with a secondary function of housing static equipment for crew hygiene and life support.
https://doi.org/10.1371/journal.pone.0304229.t003
As this is the first time such an analysis has been performed, it is not yet possible to say how typical or unusual these squares are regarding the types of activities taking place; but they provide a baseline for eventual comparison with the other four squares and future work on ISS or other space habitats.
Some general characteristics are revealed by archaeological analysis of a space station’s material culture. First, even in a small, enclosed site, occupied by only a few people over a relatively short sample period, we can observe divergent patterns for different locations and activity phases. Second, while distinct functions are apparent for these two squares, they are not the functions that we expected prior to this research. As a result, our work fulfills the promise of the archaeological approach to understanding life in a space station by revealing new, previously unrecognized phenomena relating to life and work on the ISS. There is now systematically recorded archaeological data for a space habitat.
Squares 03 and 05 served quite different purposes. The reasons for this fact are their respective affordances and their locations relative to activity areas designated for science and exercise. Their national associations, especially the manifestation of the control wielded by NASA over its modules, also played a role in the use of certain materials, the placement of facilities, and the organization of work. How each area was used was also the result of an interplay between the original plans developed by mission planners and habitat designers (or the lack of such plans), the utility of the equipment and architecture in each location, and the contingent needs of the crew as they lived in the station. This interplay became visible in the station’s material culture, as certain areas were associated with particular behaviors, over time and through tradition—over the long duration across many crews (Node 2, location of Square 03, docked with the ISS in 2007, and Node 3, location of Square 05, docked in 2010), and during the specific period of this survey, from January to March 2022. During the crew debriefing, one astronaut said, “We were a pretty organized crew who was also pretty much on the same page about how to do things…. As time went on…we organized the lab and kind of got on the same page about where we put things and how we’re going to do things.” This statement shows how functional associations can become linked to different areas of the ISS through usage and mutual agreement. At the same time, the station is not frozen in time. Different people have divergent ideas about how and where to do things. It seems from the appearance of just one Russian item—a packet of generic wipes ( salfetky sukhiye ) stored in the toiletry kit throughout the sample period—that the people who used these spaces and carried out their functions did not typically include the ISS’s Russian crew. Enabling greater flexibility to define how spaces can be used could have a significant impact on improving crew autonomy over their lives, such as how and where to work. It could also lead to opening of all spaces within a habitat to the entire crew, which seems likely to improve general well-being.
An apparent disjunction between planned and actual usage appeared in Square 03. It is intended for maintenance as well as other kinds of work. But much of the time, there was nobody working here—a fact that is not captured by historic photos of the area, precisely because nothing is happening. The space has instead become the equivalent of a pegboard mounted on a wall in a home garage or shed, convenient for storage for all kinds of items—not necessarily items being used there—because it has an enormous number of attachment points. Storage has become its primary function. Designers of future workstations in space should consider that they might need to optimize for functions other than work, because most of the time, there might not be any work happening there. They could optimize for quick storage, considering whether to impose a system of organization, or allow users to organize as they want.
We expected from previous (though unsystematic) observation of historic photos and other research, that resealable plastic bags (combined with Velcro patches on the bags and walls) would be the primary means for creating gravity surrogates to control items in microgravity. They only comprise 7% of all items in Square 03 (256 instances). There are more than twice as many clips (572—more than 9 per context) in the sample. There were 193 instances of adhesive tape rolls, and more than 100 cable ties, but these were latent (not holding anything), representing potentiality of restraint rather than actualization. The squares showed different approaches to managing “gravity.” While Square 03 had a pre-existing structured array of Velcro patches, Square 05 showed a more expedient strategy with Velcro added in response to particular activities. Different needs require different affordances; creating “gravity” is a more nuanced endeavor than it initially appears. More work remains to be done to optimize gravity surrogates for future space habitats, because this is evidently one of the most critical adaptations that crews have to make in microgravity (44% of all items in Square 03, 39% in 05).
Square 05 is an empty space, seemingly just one side of a passageway for people going to use the lifting machine or the latrine, to look out of the Cupola, or get something out of deep storage in one of the ISS’s closets. In our survey, this square was a storage place for toiletries, resealable bags, and a computer that never (or almost never) gets used. It was associated with computing and hygiene simply by virtue of its location, rather than due to any particular facilities it possessed. It has no affordances for storage. There are no cabinets or drawers, as would be appropriate for organizing and holding crew personal items. A crew member decided that this was an appropriate place to leave their toiletry kit for almost two months. Whether this choice was appreciated or resented by fellow crew members cannot be discerned based on our evidence, but it seems to have been tolerated, given its long duration. The location of the other four USOS crew members’ toiletry kits during the sample period is unknown. A question raised by our observations is: how might a function be more clearly defined by designers for this area, perhaps by providing lockers for individual crew members to store their toiletries and towels? This would have a benefit not only for reducing clutter, but also for reducing exposure of toiletry kits and the items stored in them to flying sweat from the exercise equipment or other waste particles from the latrine. A larger compartment providing privacy for body maintenance and a greater range of motion would also be desirable.
As the first systematic collection of archaeological data from a space site outside Earth, this analysis of two areas on the ISS as part of the SQuARE payload has shown that novel insights into material culture use can be obtained, such as the use of wall areas as storage or staging posts between activities, the accretion of objects associated with different functions, and the complexity of using material replacements for gravity. These results enable better space station design and raise new questions that will be addressed through analysis of the remaining four squares.
Supporting information
S1 movie. nasa astronaut kayla barron installs the first square for the sampling quadrangle assemblages research experiment in the japanese experiment module (also known as kibo) on the international space station, january 14, 2022..
She places Kapton tape to mark the square’s upper right corner. Credit: NASA.
https://doi.org/10.1371/journal.pone.0304229.s001
S1 Dataset.
https://doi.org/10.1371/journal.pone.0304229.s002
S2 Dataset.
https://doi.org/10.1371/journal.pone.0304229.s003
S3 Dataset. The image annotations are represented according to sample square in json formatted text files.
The data is available in the ‘SQuARE-notebooks’ repository on Github.com in the ‘data’ subfolder at https://github.com/issarchaeologicalproject/SQuARE-notebooks/tree/main ; archived version of the repository is at Zenodo, DOI: 10.5281/zenodo.10654812 .
https://doi.org/10.1371/journal.pone.0304229.s004
S1 File. The ‘Rocket-Anno’ image annotation software is available on Github at https://github.com/issarchaeologicalproject/MRE-RocketAnno .
The archived version of the repository is at Zenodo, DOI: 10.5281/zenodo.10648399 .
https://doi.org/10.1371/journal.pone.0304229.s005
S2 File. The computational notebooks that process the data json files to reshape the data suitable for basic statistics as well as the computation of the Brainerd-Robinson coefficients of similarity are in the.ipynb notebook format.
The code is available in the ‘SQuARE-notebooks’ repository on Github.com in the ‘notebooks’ subfolder at https://github.com/issarchaeologicalproject/SQuARE-notebooks/tree/main ; archived version of the repository is at Zenodo, DOI: 10.5281/zenodo.10654812 . The software can be run online in the Google Colab environment ( https://colab.research.google.com ) or any system running Jupyter Notebooks ( https://jupyter.org/ ).
https://doi.org/10.1371/journal.pone.0304229.s006
https://doi.org/10.1371/journal.pone.0304229.s007
Acknowledgments
We thank Chapman University’s Office of Research and Sponsored Programs, and especially Dr. Thomas Piechota and Dr. Janeen Hill, for funding the Implementation Partner costs associated with the SQuARE payload. Chapman’s Leatherby Libraries’ Supporting Open Access Research and Scholarship (SOARS) program funded the article processing fee for this publication. Ken Savin and Ken Shields at the ISS National Laboratory gave major support by agreeing to sponsor SQuARE and providing access to ISS NL’s allocation of crew time. David Zuniga and Kryn Ambs at Axiom Space were key collaborators in managing payload logistics. NASA staff and contractors were critical to the experiment’s success, especially Kristen Fortson, Jay Weber, Crissy Canerday, Sierra Wolbert, and Jade Conway. We also gratefully acknowledge the help and resources provided by Dr. Erik Linstead, director of the Machine Learning and Affiliated Technology Lab at Chapman University. Aidan St. P. Walsh corrected the color and lens barrel distortion in all of the SQuARE imagery. Rao Hamza Ali produced charts using accessible color combinations for Figs 3 and 5 . And finally, of course, we are extremely appreciative of the efforts of the five USOS members of the Expedition 66 crew on the ISS—Kayla Barron, Raja Chari, Thomas Marshburn, Matthias Maurer, and Mark Vande Hei—who were the first archaeologists in space.
- 1. Buchli V. Extraterrestrial methods: Towards an ethnography of the ISS. In: Carroll T, Walford A, Walton S, editors. Lineages and advancements in material culture studies: Perspectives from UCL anthropology. London: Routledge; 2021, pp. 17–32.
- 2. Gorman A, Walsh J. Archaeology in a vacuum: obstacles to and solutions for developing a real space archaeology. In: Barnard H, editor. Archaeology outside the box: investigations at the edge of the discipline. Los Angeles, Cotsen Institute of Archaeology Press; 2023. pp. 131–123.
- 3. Walsh J. Adapting to space: The International Space Station Archaeological Project. In: Salazar Sutil JF, Gorman A, editors. Routledge handbook of social studies of outer space. London, Routledge; 2023. pp. 400–412. https://doi.org/10.4324/9781003280507-37
- View Article
- Google Scholar
- 6. Rathje W, Murphy C. Rubbish! The archaeology of garbage Tucson: University of Arizona Press; 2001.
- 7. De León J. The land of open graves: living and dying on the migrant trail. Berkeley, University of California Press; 2015.
- 8. Garrison Darrin A, O’Leary B, editors. Handbook of space engineering, archaeology, and heritage. Boca Raton, CRC Press; 2009.
- 9. Capelotti PJ. The human archaeology of space: Lunar, planetary, and interstellar relics of exploration. Jefferson, NC, McFarland Press; 2010.
- 11. Gorman A. Space and time through material culture: An account of space archaeology. In: Salazar Sutil JF, Gorman A, editors. Routledge handbook of social studies of outer space. London, Routledge; 2023. pp. 44–56. https://doi.org/10.4324/9781003280507-5
- 17. NASA. NASA Johnson. 2008 Aug [cited May 12 2024]. In: Flickr [Internet]. San Francisco. Available from https://www.flickr.com/photos/nasa2explore/
- 19. NASA. ISS Daily Status Reports. 2012 Mar 1 [Cited May 12 2024]. Available from: https://blogs.nasa.gov/stationreport/
- 20. NASA. Man-systems integration. STD-3000 Vol. 1. Houston, NASA Johnson; 1995, pp. 9–15, 78
- 21. NASA. Maintenance Work Area | Glenn Research Center. 2020 Mar 6 [cited May 12 2024]. Available from: https://www1.grc.nasa.gov/space/iss-research/mwa/
- 22. Cristoforetti S. Diario di un’apprendista astronauta. Milan, Le Polene; 2018. pp. 379.
- 23. Kelly S. Endurance: A year in space, a lifetime of discovery. New York, Knopf; 2017. pp. 175, 285–86.
- 24. Barron K. Instagram post, 2022 Feb 12 [cited 2024 May 12]. Available from: https://www.instagram.com/tv/CZ4pW9HJ2Wg/?igsh=ZDE1MWVjZGVmZQ==
- 25. NASA. NASA space flight human-system standard. STD-3001 Volume 1: Human integration design handbook. Rev. 1 Houston, NASA Johnson; 2014. pp. 814, 829–833.
- 27. Keeter B. ISS daily summary report– 2/21/2022. 2022 Feb 21 [cited May 12 2024]. In: NASA ISS On-Orbit Status Report blog [Internet]. Houston. Available from: https://blogs.nasa.gov/stationreport/2022/02/page/6/
- 28. DLR. Fingerprint research to combat harmful bacteria. 2022 Jan 18 [cited May 12 2024]. Available from: https://www.dlr.de/en/latest/news/2022/01/20220118_fingerprint-research-to-combat-harmful-bacteria
- 31. Peeples MA. R script for calculating the Brainerd-Robinson coefficient of similarity and assessing sampling error. 2011 [cited May 12 2024]. Available from: http://www.mattpeeples.net/br.html .
- 33. Garcia M. Cargo Dragon Splashes Down Ending SpaceX CRS-24 Mission. 2022 Jan 24 [cited May 12 2024]. NASA Space Station blog [Internet]. Available from: https://blogs.nasa.gov/spacestation/2022/01/24/cargo-dragon-splashes-down-ending-spacex-crs-24-mission/
- 34. ESA. Concrete Hardening | Cosmic Kiss 360°. 2022 Mar 5 [cited May 12 2024]. Available from: https://www.esa.int/ESA_Multimedia/Videos/2022/05/Concrete_Hardening_Cosmic_Kiss_360
- 35. Keeter B. ISS daily summary report– 2/01/2022. 2022 Feb 1 [cited May 12 2024]. In: NASA ISS On-Orbit Status Report blog [Internet]. Houston. Available from: https://blogs.nasa.gov/stationreport/2022/02/page/19/
- 36. Keeter B. ISS daily summary report– 2/17/2022. 2022 Feb 17 [cited May 12 2024]. In: NASA ISS On-Orbit Status Report blog [Internet]. Houston. Available from: https://blogs.nasa.gov/stationreport/2022/02/page/8/
- 37. T. Pultarova, How Do You Clean a Space Station? Astronaut Thomas Pesquet Shares Orbital Spring Cleaning Tips, Space.com, May 6, 2021. Online at https://www.space.com/space-station-cleaning-tips-astronaut-thomas-pesquet
- 38. Keeter B. ISS daily summary report– 2/22/2022. 2022 Feb 22 [cited May 12 2024]. In: NASA ISS On-Orbit Status Report blog [Internet]. Houston. Available from: https://blogs.nasa.gov/stationreport/2022/02/page/5/
- 39. Keeter B. ISS daily summary report– 2/02/2022. 2022 Feb 2 [cited May 12 2024]. NASA ISS On-Orbit Status Report blog [Internet]. Houston. Online at https://blogs.nasa.gov/stationreport/2022/02/page/18/
- 40. Keeter B. ISS daily summary report– 3/03/2022. 2022 Mar 3 [cited May 12 2024]. In: NASA ISS On-Orbit Status Report blog [Internet]. Houston. Available from: https://blogs.nasa.gov/stationreport/2022/03/page/21/
- 41. Keeter B. ISS daily summary report– 2/08/2022. 2022 Feb 8 [cited May 12 2024]. NASA ISS On-Orbit Status Report blog [Internet]. Houston. Available from: https://blogs.nasa.gov/stationreport/2022/02/page/15/
- 42. Aristotle of Stageira. Metaphysics, Volume I: Books 1–9, Tredennick H, translator. Loeb Classical Library 271. Cambridge, MA, Harvard University Press; 1933. pp. 429–473.
- 44. Hodder I. Entangled: An archaeology of the relationships between humans and things. Hoboken. NJ, Wiley-Blackwell; 2012.
- 45. Malafouris L., How Things Shape the Mind: A Theory of Material Engagement (MIT Press, 2016).
- 46. Keeter B. ISS daily summary report– 3/11/2022. 2022 Mar 11 [cited May 12 2024]. NASA ISS On-Orbit Status Report blog [Internet]. Houston. Available from: https://blogs.nasa.gov/stationreport/2022/03/page/15/

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Ann Indian Acad Neurol
- v.14(4); Oct-Dec 2011
Design, data analysis and sampling techniques for clinical research
Karthik suresh.
Department of Pulmonary and Critical Care Medicine, Johns Hopkins University School of Medicine, Trivandrum, India
Sanjeev V. Thomas
1 Department of Neurology, Sree Chitra Tirunal Institute for Medical Sciences and Technology, Trivandrum, India
Geetha Suresh
2 Department of Justice Administration, University of Louisville, Louiseville, USA
Statistical analysis is an essential technique that enables a medical research practitioner to draw meaningful inference from their data analysis. Improper application of study design and data analysis may render insufficient and improper results and conclusion. Converting a medical problem into a statistical hypothesis with appropriate methodological and logical design and then back-translating the statistical results into relevant medical knowledge is a real challenge. This article explains various sampling methods that can be appropriately used in medical research with different scenarios and challenges.
Problem Identification
Clinical research often starts from questions raised at the bedside in hospital wards. Is there an association between neurocysticercosis (NCC) and epilepsy? Are magnetic resonance imaging changes good predictors of multiple sclerosis? Is there a benefit in using steroids in pyogenic meningitis? Typically, these questions lead us to set up more refined research questions. For example, do persons with epilepsy have a higher probability of having serological (or computed tomography [CT] scan) markers for NCC? What proportion of persons with multiple lesions in the brain has Multiple Sclerosis (MS) Do children with pyogenic meningitis have a lesser risk of mortality if dexamethasone is used concomitantly with antibiotics?
Designing a clinical study involves narrowing a topic of interest into a single focused research question, with particular attention paid to the methods used to answer the research question from a cost, viability and overall effectiveness standpoint. In this paper, we focus attention on residents and younger faculty who are planning short-term research projects that could be completed in 2–3 years. Once we have a fairly well-defined research question, we need to consider the best strategy to address these questions. Further considerations in clinical research, such as the clinical setting, study design, selection criteria, data collection and analysis, are influenced by the disease characteristics, prevalence, time availability, expertise, research grants and several other factors. In the example of NCC, should we use serological markers or CT scan findings as evidence of NCC? Such a question raises further questions. How good are serologic markers compared with CT scans in terms of identifying NCC? Which test (CT or blood test) is easier, safer and acceptable for this study? Do we have the expertise to carry out these laboratory tests and make interpretations? Which procedure is going to be more expensive? It is very important that the researcher spend adequate time considering all these aspects of his study and engage in discussion with biostatisticians before actually starting the study.
The major objective of this article is to explain these initial steps. We do not intend to provide a tailor-made design. Our aim is to familiarize the reader with different sampling methods that can be appropriately used in medical research with different scenarios and challenges.
One of the first steps in clinical study is choosing an appropriate setting to conduct the study (i.e., hospital, population-based). Some diseases, such as migraine, may have a different profile when evaluated in the population than when evaluated in the hospital. On the other hand, acute diseases such as meningitis would have a similar profile in the hospital and in the community. The observations in a study may or may not be generalizable, depending on how closely the sample represents the population at large.
Consider the following studies. Both De Gans et al .[ 1 ] and Scarborough et al .[ 2 ] looked at the effect of adjunctive Dexamethasone in bacterial meningitis. Both studies are good examples of using the hospital setting. Because the studies involved acute conditions, they utilize the fact that sicker patients will seek hospital care to concentrate their ability to find patients with meningitis. By the same logic, it would be inappropriate to study less-acute conditions in such a fashion as it would bias the study toward sicker patients.
On the other hand, consider the study by Holroyd et al .[ 3 ] investigating therapies in the treatment of migraine. Here, the authors intentionally chose an outpatient setting (the patients were referred to the study clinic from a network of other physician clinics as well as local advertisements) so that their population would not include patients with more severe pathology (requiring hospital admission).
If the sample was restricted to a particular age group, sex, socioeconomic background or stage of the disease, the results would be applicable to that particular group only. Hence, it is important to decide how you select your sample. After choosing an appropriate setting, attention must be turned to the inclusion and exclusion criteria. This is often locale specific. If we compare the exclusion criteria for the two meningitis studies mentioned above, we see that in the study by de Gans,[ 1 ] patients with shunts, prior neurosurgery and active tuberculosis were specifically excluded; in the Scarbrough study, however, such considerations did not apply as the locale was considerably different (sub-saharan Africa vs. Europe).
Validity (Precision) and Reliability (Consistency)
Clinical research generally requires making use of an existing test or instrument. These instruments and investigations have usually been well validated in the past, although the populations in which such validations were conducted may be different. Many such questionnaires and patient self-rating scales (MMSE or QOLIE, for instance) were developed in another part of the world. Therefore, in order to use these tests in clinical studies locally, they require validation. Socio-demographic characteristics and language differences often influence such tests considerably. For example, consider a scale that uses the ability to drive a motor car as a Quality of Life measure. Does this measure have the same relevance in India as in the USA, where only a small minority of people drive their own vehicles? Hence, it is very important to ensure that the instruments that we use have good validity.
Validity is the degree to which the investigative goals are measured accurately. The degree to which the research truly measures what it intended to measure[ 4 ] determines the fundamentals of medical research. Peace, Parrillo and Hardy[ 5 ] explain that the validity of the entire research process must be critically analyzed to the greatest extent possible so that appropriate conclusions can be drawn, and recommendations for development of sound health policy and practice can be offered.
Another measurement issue is reliability. Reliability refers to the extent to which the research measure is a consistent and dependable indicator of medical investigation. In measurement, reliability is an estimate of the degree to which a scale measures a construct consistently when it is used under the same condition with the same or different subjects. Reliability (consistency) describes the extent to which a measuring technique consistently provides the same results if the measurement is repeated. The validity (accuracy) of a measuring instrument is high if it measures exactly what it is supposed to measure. Thus, the validity and reliability together determine the accuracy of the measurement, which is essential to make valid statistical inference from a medical research.
Consider the following scenario. Kasner et al .[ 6 ] established reliability and validity of a new National Institute of Health Stroke Scale (NIHSS) generation method. This paper provides a good example of how to test a new instrument (NIH stroke score generation via retrospective chart review) with regards to its reliability and validity. To test validity, the investigators had multiple physicians review the same set of charts and compared the variability within the scores calculated by these physicians. To test reliability, the investigators compared the new test (NIHSS calculated by chart review) to the old test (NIHSS calculated at the bedside at the time of diagnosis). They reported that, overall, 88% of the estimated scores deviated by less than five points from the actual scores at both admission and discharge.
A major purpose of doing research is to infer or generalize research objectives from a sample to a larger population. The process of inference is accomplished by using statistical methods based on probability theory. A sample is a subset of the population selected, which is an unbiased representative of the larger population. Studies that use samples are less-expensive, and study of the entire population is sometimes impossible. Thus, the goal of sampling is to ensure that the sample group is a true representative of the population without errors. The term error includes sampling and nonsampling errors. Sampling errors that are induced by sampling design include selection bias and random sampling error. Nonsampling errors are induced by data collection and processing problems, and include issues related to measurement, processing and data collection errors.
Methods of sampling
To ensure reliable and valid inferences from a sample, probability sampling technique is used to obtain unbiased results. The four most commonly used probability sampling methods in medicine are simple random sampling, systematic sampling, stratified sampling and cluster sampling.
In simple random sampling, every subject has an equal chance of being selected for the study. The most recommended way to select a simple random sample is to use a table of random numbers or a computer-generated list of random numbers. Consider the study by Kamal et al .[ 7 ] that aimed to assess the burden of stroke and transient ischemic attack in Pakistan. In this study, the investigators used a household list from census data and picked a random set of households from this list. They subsequently interviewed the members of the randomly chosen households and used this data to estimate cerebrovascular disease prevalence in a particular region of Pakistan. Prevalence studies such as this are often conducted by using random sampling to generate a sampling frame from preexisting lists (such as census lists, hospital discharge lists, etc.).
A systematic random sample is one in which every k th item is selected. k is determined by dividing the number of items in the sampling frame by sample size.
A stratified random sample is one in which the population is first divided into relevant strata or subgroups and then, using the simple random sample method, a sample is drawn from each strata. Deng et al .[ 8 ] studied IV tissue Plasminogen Activator (tPA) usage in acute stroke among hospitals in Michigan. In order to enroll patients across a wide array of hospitals, they employ a stratified random sampling in order to construct the list of hospitals. They stratified hospitals by number of stroke discharges, and then randomly picked an equal number of hospitals within each stratum. Stratified random sampling such as this can be used to ensure that sampling adequately reflects the nature of current practice (such as practice and management trends across the range of hospital patient volumes, for instance).
A cluster sample results from a two-stage process in which the population is divided into clusters, and a subset of the clusters is randomly selected. Clusters are commonly based on geographic areas or districts and, therefore, this approach is used more often in epidemiologic research than in clinical studies.[ 9 ]
Random samples and randomization
Random samples and randomization (aka, random assignment) are two different concepts. Although both involve the use of the probability sampling method, random sampling determines who will be included in the sample. Randomization, or random assignment, determines who will be in the treatment or control group. Random sampling is related to sampling and external validity (generalizability), whereas random assignment is related to design and internal validity.
In experimental studies such as randomized controlled trials, subjects are first selected for inclusion in the study on the basis of appropriate criteria; they are then assigned to different treatment modalities using random assignment. Randomized controlled trials that are considered to be the most efficient method of controlling validity issues by taking into account all the potential confounding variables (such as other outside factors that could influence the variables under study) are also considered most reliable and impartial method of determining the impact of the experiment. Any differences in the outcome of the study are more likely to be the result of difference in the treatments under consideration than due to differences because of groups.
Scarborough et al .,[ 2 ] in a trial published in the New England Journal of Medicine , looked at corticosteroid therapy for bacterial meningitis in sub-saharan Africa to see whether the benefits seen with early corticosteroid administration in bacterial meningitis in the developed world also apply to the developing world. Interestingly, they found that adjuvant Dexamethasone therapy did not improve outcomes in meningitis cases in sub-saharan Africa. In this study, they performed random assignment of therapy (Dexamethasone vs. placebo). It is useful to note that the process of random assignment usually involves multiple sub-steps, each designed to eliminate confounders. For instance, in the above-mentioned study, both steroids and placebo were packaged similarly, in opaque envelopes, and given to patients (who consented to enroll) in a randomized fashion. These measures ensure the double-blind nature of the trial. Care is taken to make sure that the administrators of the therapy in question are blinded to the type of therapy (steroid vs. placebo) that is being given.
Sample size
The most important question that a researcher should ask when planning a study is “How large a sample do I need?” If the sample size is too small, even a well-conducted study may fail to answer its research question, may fail to detect important effects or associations, or may estimate those effects or associations too imprecisely. Similarly, if the sample size is too large, the study will be more difficult and costly, and may even lead to a loss in accuracy. Hence, optimum sample size is an essential component of any research. Careful consideration of sample size and power analysis during the planning and design stages of clinical research is crucial.
Statistical power is the probability that an empirical test will detect a relationship when a relationship in fact exists. In other words, statistical power explains the generalizability of the study results and its inferential power to explain population variability. Sample size is directly related to power; ceteris paribus, the bigger a sample, the higher the statistical power.[ 10 ] If the statistical power is low, this does not necessarily mean that an undetected relationships exist, but does indicate that the research is unlikely to find such links if they exist.[ 10 ] Flow chart relating research question, sampling and research design and data analysis is shown in Figure 1 .

Overall framework of research design
The power of a study tells us how confidently we can exclude an association between two parameters. For example, regarding the prior research question of the association between NCC and epilepsy, a negative result might lead one to conclude that there is no association between NCC and epilepsy. However, the study might not have been sufficiently powered to exclude any possible association, or the sample size might have been too small to reveal an association.
The sample sizes seen in the two meningitis studies mentioned earlier are calculated numbers. Using estimates of prevalence of meningitis in their respective communities, along with variables such as size of expected effect (expected rate difference between treated and untreated groups) and level of significance, the investigators in both studies would have calculated their sample numbers ahead of enrolling patients. Sample sizes are calculated based on the magnitude of effect that the researcher would like to see in his treatment population (compared with placebo). It is important to note variables such as prevalence, expected confidence level and expected treatment effect need to be predetermined in order to calculate sample size. As an example, Scarborough et al .[ 2 ] state that “on the basis of a background mortality of 56% and an ability to detect a 20% or greater difference in mortality, the initial sample size of 660 patients was modified to 420 patients to detect a 30% difference after publication of the results of a European trial that showed a relative risk of death of 0.59 for corticosteroid treatment.” Determining existing prevalence and effect size can be difficult in areas of research where such numbers are not readily available in the literature. Ensuring adequate sample size has impacts for the final results of a trial, particularly negative trials. An improperly powered negative trial could fail to detect an existing association simply because not enough patients were enrolled. In other words, the result of the sample analysis would have failed to reject the null hypothesis (that there is no difference between the new treatment and the alternate treatment), when in fact it should have been rejected, which is referred to as type II error. This statistical error arises because of inadequate power to explain population variability. Careful consideration of sample size and power analysis is one of the prerequisites of medical research. Another prerequisite is appropriate and adequate research design, which will be addressed in the next issue.
Source of Support: Nil,
Conflict of Interest: Nil.
- Sampling Design
- Mathematics
- Sample Size
Research Sampling and Sample Size Determination: A practical Application
- October 2019

- University of Africa, Toru-Orua, Bayelsa State, Nigeria
- This person is not on ResearchGate, or hasn't claimed this research yet.
Discover the world's research
- 25+ million members
- 160+ million publication pages
- 2.3+ billion citations

- Carlos Da Coneceicao De Deus

- Hamid Anwar
- Afed Ullah Khan

- Eric Frimpong
- J Air Waste Manag Assoc

- Samuel Jerry Cobbina

- Irene Halim
- Recruit researchers
- Join for free
- Login Email Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google Welcome back! Please log in. Email · Hint Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google No account? Sign up
IMAGES
COMMENTS
Cluster sampling is advantageous for those researcher s. whose subjects are fragmented over large geographical areas as it saves time and money. (Davis, 2005). The stages to cluster sa mpling can ...
Example: Simple random sampling. You want to select a simple random sample of 1000 employees of a social media marketing company. You assign a number to every employee in the company database from 1 to 1000, and use a random number generator to select 100 numbers. 2. Systematic sampling.
Linear systematic sampling is a statistical sampling technique that involves selec ting every kth element from a. list or population after a random starting point has been det ermined. This method ...
Understand sampling methods in research, from simple random sampling to stratified, systematic, and cluster sampling. Learn how these sampling techniques boost data accuracy and representation, ensuring robust, reliable results. Check this article to learn about the different sampling method techniques, types and examples.
Sampling types. There are two major categories of sampling methods ( figure 1 ): 1; probability sampling methods where all subjects in the target population have equal chances to be selected in the sample [ 1, 2] and 2; non-probability sampling methods where the sample population is selected in a non-systematic process that does not guarantee ...
First, we'll look at four common probability-based (random) sampling methods: Simple random sampling. Stratified random sampling. Cluster sampling. Systematic sampling. Importantly, this is not a comprehensive list of all the probability sampling methods - these are just four of the most common ones.
Abstract. Knowledge of sampling methods is essential to design quality research. Critical questions are provided to help researchers choose a sampling method. This article reviews probability and non-probability sampling methods, lists and defines specific sampling techniques, and provides pros and cons for consideration.
The method by which the researcher selects the sample is the ' Sampling Method'. There are essentially two types of sampling methods: 1) probability sampling - based on chance events (such as random numbers, flipping a coin etc.); and 2) non-probability sampling - based on researcher's choice, population that accessible & available.
We could choose a sampling method based on whether we want to account for sampling bias; a random sampling method is often preferred over a non-random method for this reason. Random sampling examples include: simple, systematic, stratified, and cluster sampling. Non-random sampling methods are liable to bias, and common examples include ...
This paper presents the steps to go through to conduct sampling. Furthermore, as there are different types of sampling techniques/methods, researcher needs to understand the differences to select the proper sampling method for the research. In the regards, this paper also presents the different types of sampling techniques and methods.
In quantitative studies, the sampling plan, including sample size, is determined in detail in beforehand but qualitative research projects start with a broadly defined sampling plan. This plan enables you to include a variety of settings and situations and a variety of participants, including negative cases or extreme cases to obtain rich data.
This paper presents the steps to go through to conduct sampling. Furthermore, as there are different types of sampling techniques/methods, researcher needs to understand the differences to select the proper sampling method for the research. In the regards, this paper also presents the different types of sampling techniques and methods.
Sampling methods refer to the techniques used to select a subset of individuals or units from a larger population for the purpose of conducting statistical analysis or research. Sampling is an essential part of the Research because it allows researchers to draw conclusions about a population without having to collect data from every member of ...
Sampling methods in psychology refer to strategies used to select a subset of individuals (a sample) from a larger population, to study and draw inferences about the entire population. Common methods include random sampling, stratified sampling, cluster sampling, and convenience sampling. Proper sampling ensures representative, generalizable, and valid research results.
Also, in the case of a small. sample set, a representation of the entire population is more likely to be compromised ( Bhardwaj, 2019; Sharma, 2017 ). 3.2. Systematic Sampling. Systematic sampling ...
3.4 Sampling Techniques in Quantitative Research Target Population. The target population includes the people the researcher is interested in conducting the research and generalizing the findings on. 40 For example, if certain researchers are interested in vaccine-preventable diseases in children five years and younger in Australia. The target population will be all children aged 0-5 years ...
The essential topics related to the selection of participants for a health research are: 1) whether to work with samples or include the whole reference population in the study (census); 2) the sample basis; 3) the sampling process and 4) the potential effects nonrespondents might have on study results. We will refer to each of these aspects ...
A Manual for Selecting Sampling Techniques in Research. Mohsin Hassan Alvi. The Manual for Sampling Techniques used in Social Sciences is an effort to describe various types of sampling methodologies that are used in researches of social sciences in an easy and understandable way. Characteristics, benefits, crucial issues/ draw backs, and ...
Sampling is one of the most important factors which determines the accuracy of a study. This article review the sampling techniques used in research including Probability sampling techniques ...
Sampling Methods in Research Design. Dana P. Turner MSPH, PhD, Corresponding Author. ... Search for more papers by this author. Dana P. Turner MSPH, PhD, Corresponding Author. ... Wiley Research DE&I Statement and Publishing Policies; Help & Support. Contact Us;
Between January and March 2022, crew aboard the International Space Station (ISS) performed the first archaeological fieldwork in space, the Sampling Quadrangle Assemblages Research Experiment (SQuARE). The experiment aimed to: (1) develop a new understanding of how humans adapt to life in an environmental context for which we are not evolutionarily adapted, using evidence from the observation ...
Statistical analysis is an essential technique that enables a medical research practitioner to draw meaningful inference from their data analysis. Improper application of study design and data analysis may render insufficient and improper results and conclusion. Converting a medical problem into a statistical hypothesis with appropriate ...
Research sampling techniques refer to case selection strategy — the process and methods used to select a subset of units from a population. ... Research Papers, The ses, and Dissertations. 8 th ...
For a professional paper, the affiliation is the institution at which the research was conducted. Include both the name of any department and the name of the college, university, or other institution, separated by a comma. Center the affiliation on the next double-spaced line after the author names; when there are multiple affiliations, center ...
The aim of this paper is to sensitize our researchers on the importance of proper sampling and sample size determination. The various types of probability and non-probability sampling techniques ...